CookBook по регулярным выражениям (REGEX)
Проверка работы регулярок (выставить флаги gm):
Доп чтиво:
- https://habr.com/ru/articles/545150/
- https://regex.sorokin.engineer/ru/latest/regular_expressions.html
В KUMA все группы которые участвуют в маппинге (нормализации) должны быть именованы, пример именования "priority" для группы: (?P<priority>\d|\d{2}|1[1-8]\d|19[01])
Если группа не нужна в маппинге, то можно использовать не именованную группу, пример: (?:\d|\d{2}|1[1-8]\d|19[01])
Простейшие приемы, практику отработаем на тестовом сообщении:
Message from 127.0.0.1 (localhost): KUMA is the best SIEM in 2023!Захватить строку KUMA
KUMA Ищется полное соответствие строке KUMA.

Захватить строку содержащую только буквы
[A-Za-z]+ Ищем группу ([]) символов с большими (A-Z) и маленькими (a-z) буквами от одной и более (+).

Захватить строку содержащую только числа
\d+ Ищем по токену \d, что является эквивалентом [0-9] от одного и более вхождений (+).

Захватить строку внутри круглых скобок
\((\w+)\) Ищем по токену \w, что является эквивалентом [a-zA-Z0-9_] от одного и более вхождений (+), при этом экранируем круглые скобки с помощью обратного слеша \ и строку нашу определяем в группу круглыми скобками ()

Захватить строку до двоеточия
^[^\:]+ Ищем с начала строки ^, далее захватываем в группе все кроме двоеточия (символ двоеточия экранирован) [^\:] от одного и более вхождений (+)

Захватить строку после двоеточия
[^\:]+$ Такая, подобная предствленной выше, конструкция не подойдет, т.к. она будет очень емокой (633 шага). Ищем все кроме двоеточия (символ двоеточия экранирован) [^\:] от одного и более вхождений (+), но до конца строки $

В нашем случае лучше использовать следующее
\:(.*)$ Ищем в строке двоеточие \:, далее захватываем все символы от нуля и более вхождений (*), и берем все что нам нужно в группу ()

Захватить IP-адрес
\d+\.\d+\.\d+\.\d+ Ищем числа от одного и более \d+, с точкой и так 4 раза

Захватить слова состоящие из 4 букв
\b[a-zA-Z]{4}\b Ищем группу 4 символов из букв и разграничиваем их (boundary) \b

Захватить слова состоящие от 3 до 4 букв
\b[a-zA-Z]{3,4}\b Ищем группу 4 символов из букв и разграничиваем их (boundary) \b

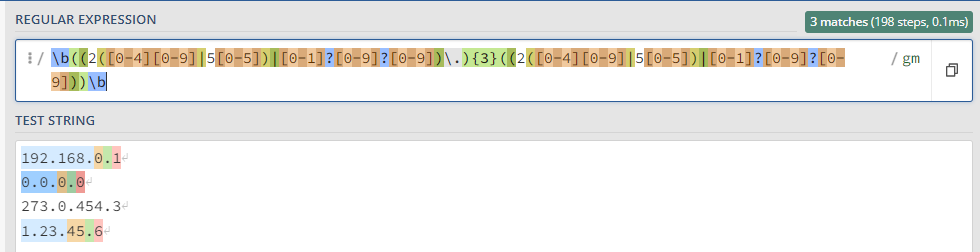
Захватить IPv4 адрес
\b((2([0-4][0-9]|5[0-5])|[0-1]?[0-9]?[0-9])\.){3}((2([0-4][0-9]|5[0-5])|[0-1]?[0-9]?[0-9]))\b
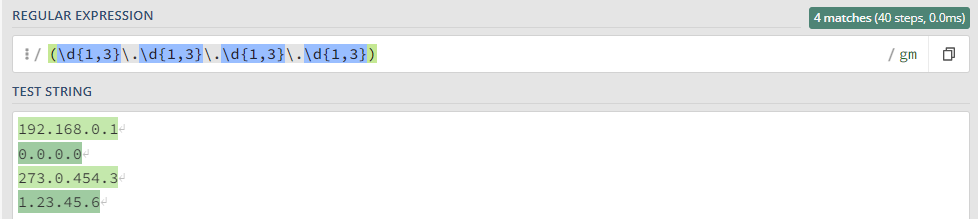
Более ленивый вариант, но быстрый, без валидации:
(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})
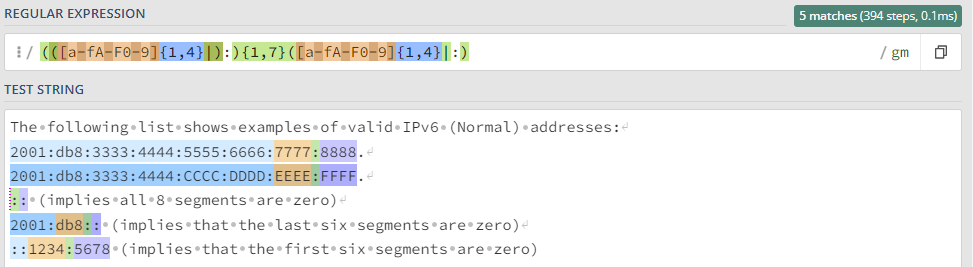
Захватить IPv6 адрес
(([a-fA-F0-9]{1,4}|):){1,7}([a-fA-F0-9]{1,4}|:)
Захватить HASH сумму
- MD
^[a-fA-F0-9]{32}$ - SHA1
^[a-fA-F0-9]{40}$ - SHA256
^[a-fA-F0-9]{64}$ - SHA512
^[a-fA-F0-9]{128}$
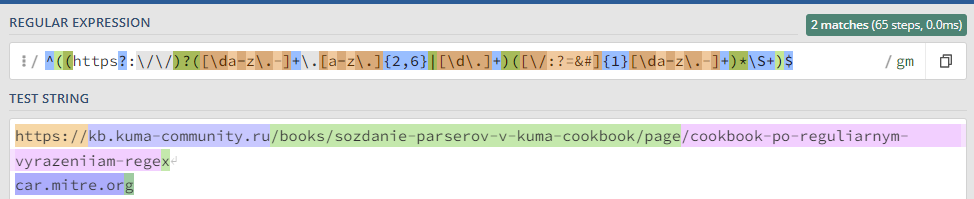
Захватить URL адрес
^((https?:\/\/)?([\da-z\.-]+\.[a-z\.]{2,6}|[\d\.]+)([\/:?=&#]{1}[\da-z\.-]+)*\S+)$
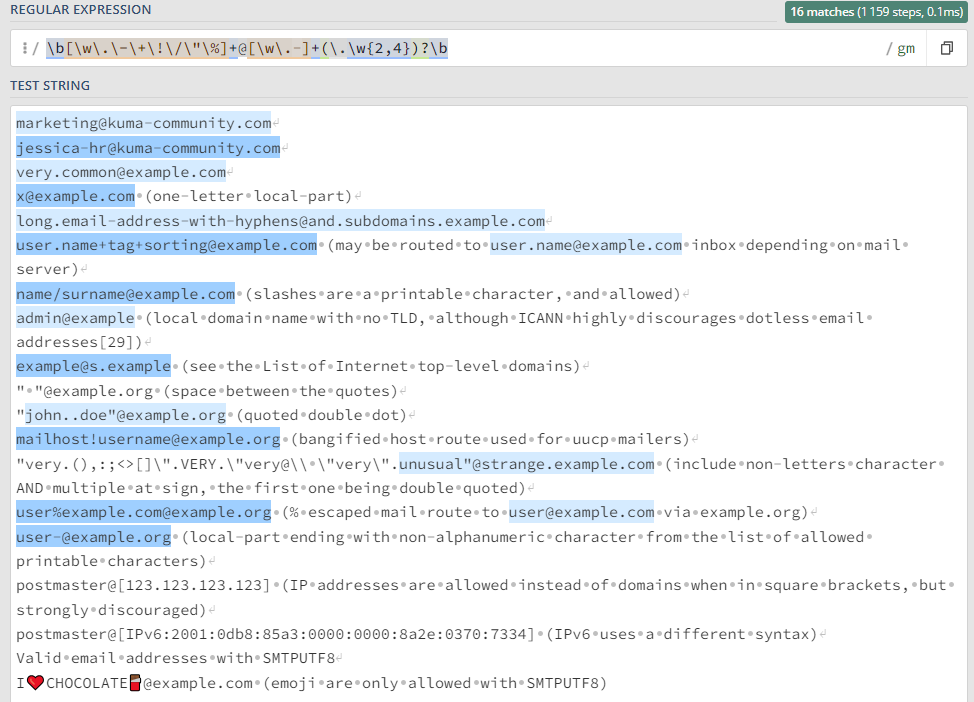
Захватить EMAIL адрес
Определяет почти все типы валидных адресов
\b[\w\.\-\+\!\/\"\%]+@[\w\.-]+(\.\w{2,4})?\b
Захватить CSV структуру
Создаются группы по значениям из CSV
(?:\s*(?:\"([^\"]*)\"|([^,]+))\s*,?)+?

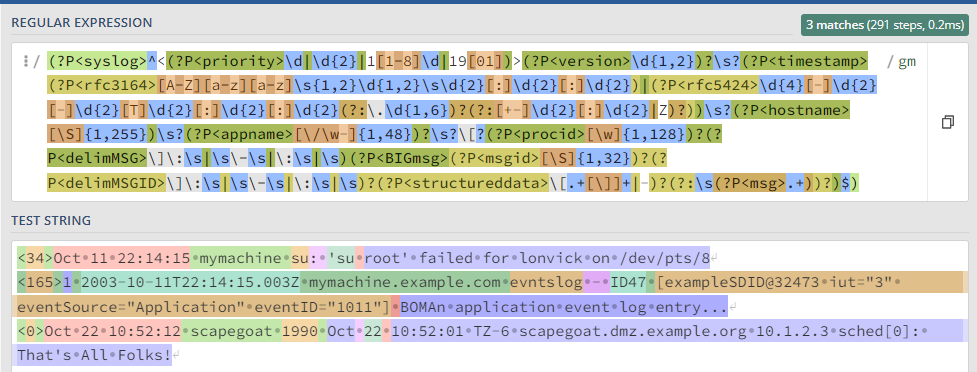
Захватить Syslog структуру
Разбираются сообщения по rfc https://datatracker.ietf.org/doc/html/rfc5424 и https://datatracker.ietf.org/doc/html/rfc3164
(?P<syslog>^<(?P<priority>\d|\d{2}|1[1-8]\d|19[01])>(?P<version>\d{1,2})?\s?(?P<timestamp>(?P<rfc3164>[A-Z][a-z][a-z]\s{1,2}\d{1,2}\s\d{2}[:]\d{2}[:]\d{2})|(?P<rfc5424>\d{4}[-]\d{2}[-]\d{2}[T]\d{2}[:]\d{2}[:]\d{2}(?:\.\d{1,6})?(?:[+-]\d{2}[:]\d{2}|Z)?))\s?(?P<hostname>[\S]{1,255})\s?(?P<appname>[\/\w-]{1,48})?\s?\[?(?P<procid>[\w]{1,128})?(?P<delimMSG>\]\:\s|\s\-\s|\:\s|\s)(?P<BIGmsg>(?P<msgid>[\S]{1,32})?(?P<delimMSGID>\]\:\s|\s\-\s|\:\s|\s)?(?P<structureddata>\[.+[\]]+|-)?(?:\s(?P<msg>.+))?)$)
Захватить символы (не буквы и не цифры)
[^\w \xC0-\xFF]

Работа с многострочным сообщением
В regexp существуют следующие флаги:
i- нечувствителен к регистру (по умолчанию false)m- многострочный режим, ^ и $ соответствуют строке начала/конца в дополнение к тексту начала/конца (по умолчанию false)s- позволяет.(точке) совпадать с\n(по умолчанию false)U- не жадный режим, меняет местами значения x* и x*?, x+ и x+? и т. д. (по умолчанию false)
Синтаксис флага: xyz (установить) или -xyz (очистить) или xy-z (установить xy, очистить z).
Устанавливаем флаг s
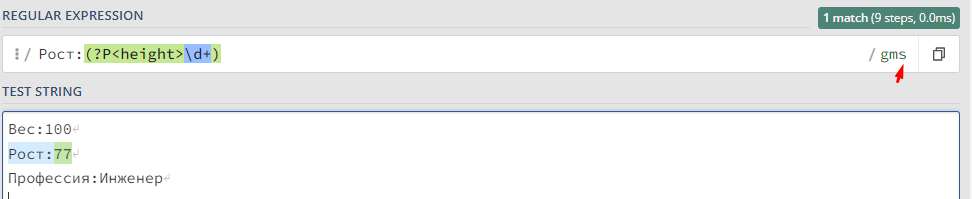
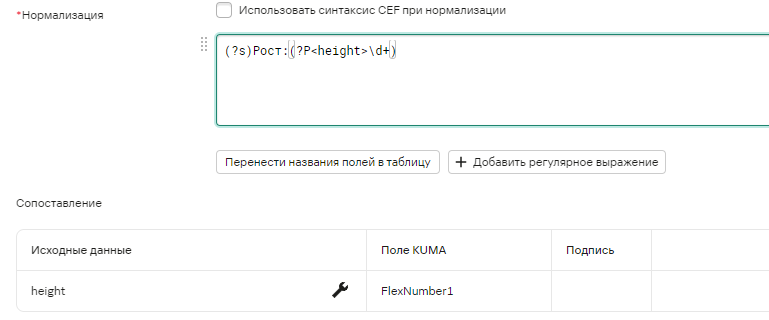
Использование в KUMA:

Замена разделителя в структуре KV
Иногда в структуре KV разделитель пробел создает нам проблемы, пример такого события:
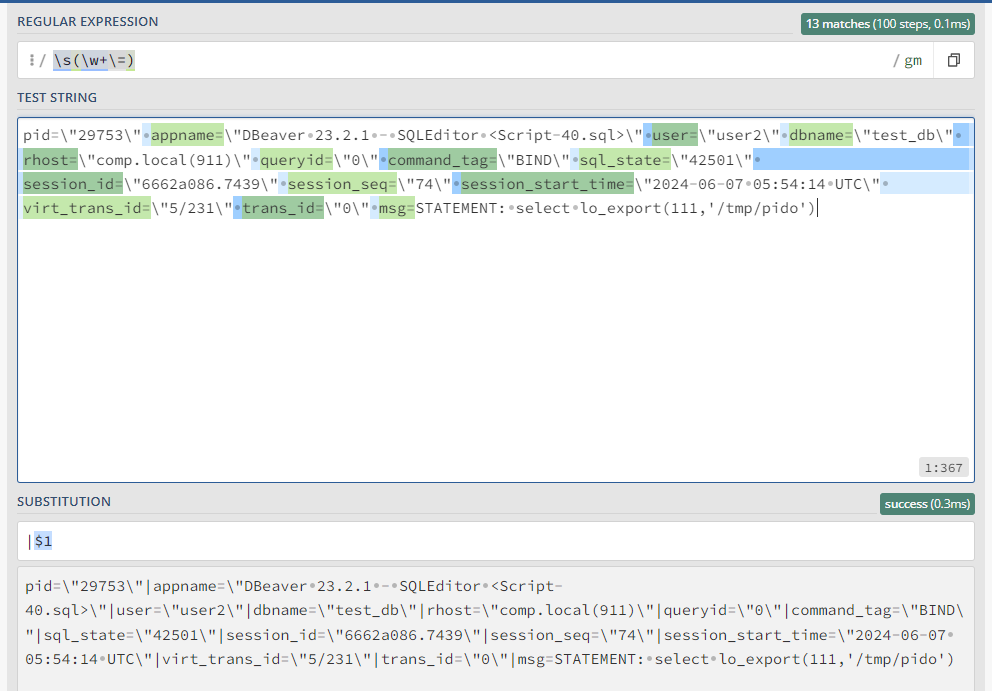
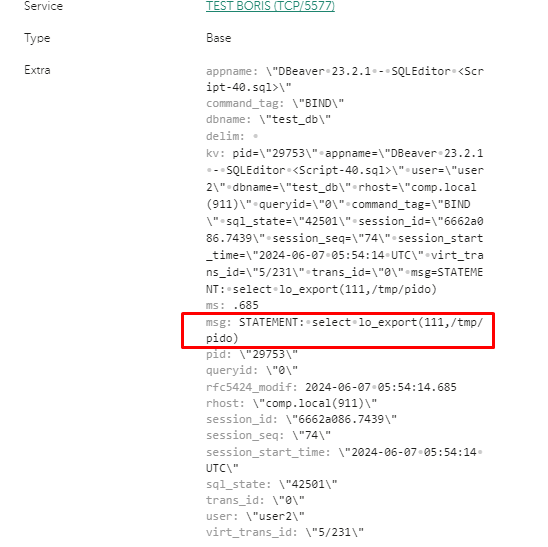
pid=\"29753\" appname=\"DBeaver 23.2.1 - SQLEditor <Script-40.sql>\" user=\"user2\" dbname=\"test_db\" rhost=\"comp.local(911)\" queryid=\"0\" command_tag=\"BIND\" sql_state=\"42501\" session_id=\"6662a086.7439\" session_seq=\"74\" session_start_time=\"2024-06-07 05:54:14 UTC\" virt_trans_id=\"5/231\" trans_id=\"0\" msg=STATEMENT: select lo_export(111,'/tmp/pido')В примере значение по ключу msg без кавычек, и оно будет некорректно парситься, поэтому можно, либо заменами добавить эти кавычки, либо воспользоваться приемом полегче и сделать разделитель, например |
Для этого используем функцию replaceWithRegexp:
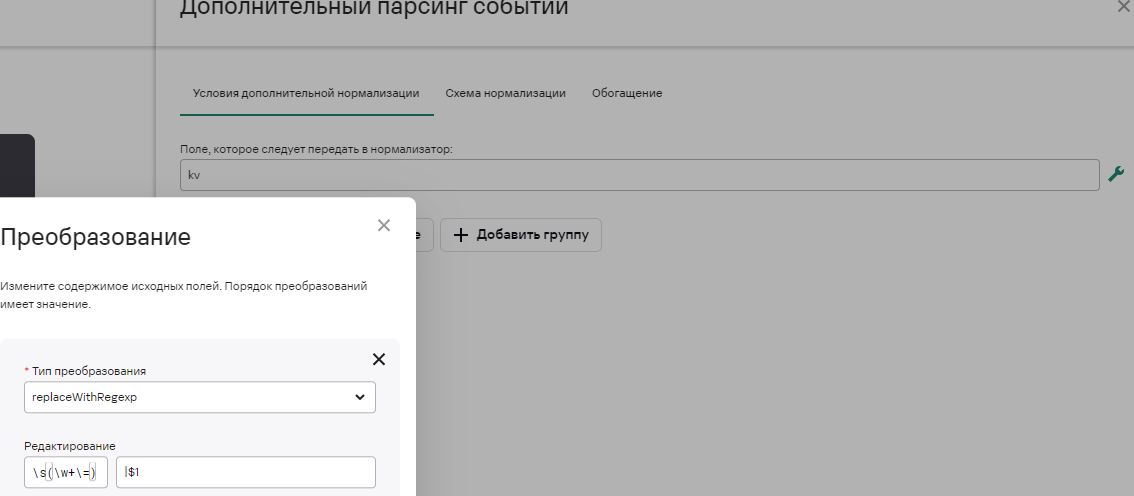
Вот как выглядит будет замена:
Вот как это выглядит в KUMA:
Общая шпаргалка

No comments to display
No comments to display