В KUMA все группы которые участвуют в маппинге (нормализации) должны быть именованы, пример именования "priority" для группы: `(?P
Если группа не нужна в маппинге, то можно использовать не именованную группу, пример: `(?:\d|\d{2}|1[1-8]\d|19[01])`
Простейшие приемы, практику отработаем на тестовом сообщении: ``` Message from 127.0.0.1 (localhost): KUMA is the best SIEM in 2023! ``` ### Захватить строку KUMA `KUMA` *Ищется полное соответствие строке KUMA.* [](https://kb.kuma-community.ru/uploads/images/gallery/2023-10/oJYimage.png) ### Захватить строку содержащую только буквы `[A-Za-z]+` *Ищем группу (**\[\]**) символов с большими (**A-Z**) и маленькими (**a-z**) буквами от одной и более (**+**).* [](https://kb.kuma-community.ru/uploads/images/gallery/2023-10/sOYimage.png) ### Захватить строку содержащую только числа `\d+` *Ищем по токену **\\d**, что является эквивалентом **\[0-9\]** от одного и более вхождений (**+**).* [](https://kb.kuma-community.ru/uploads/images/gallery/2023-10/bf3image.png) ### Захватить строку внутри круглых скобок `\((\w+)\)` *Ищем по токену **\\w**, что является эквивалентом **\[a-zA-Z0-9\_\]** от одного и более вхождений (**+**), при этом экранируем круглые скобки с помощью обратного слеша **\\** и строку нашу определяем в группу круглыми скобками **()*** [](https://kb.kuma-community.ru/uploads/images/gallery/2023-10/mR9image.png) ### Захватить строку до двоеточия `^[^\:]+` *Ищем с начала строки **^**, далее захватываем в группе все кроме двоеточия (символ двоеточия экранирован) **\[^\\:\]** от одного и более вхождений (**+**)* [](https://kb.kuma-community.ru/uploads/images/gallery/2023-10/p5Ximage.png) ### Захватить строку после двоеточия `[^\:]+$` Такая, подобная предствленной выше, конструкция не подойдет, т.к. она будет очень емокой (633 шага). *Ищем все кроме двоеточия (символ двоеточия экранирован) **\[^\\:\]** от одного и более вхождений (**+**), но до конца строки **$*** [](https://kb.kuma-community.ru/uploads/images/gallery/2023-10/aPvimage.png) В нашем случае лучше использовать следующее *`\:(.*)$` Ищем в строке двоеточие **\\:**, далее захватываем все символы от нуля и более вхождений (**\***), и берем все что нам нужно в группу **()*** [](https://kb.kuma-community.ru/uploads/images/gallery/2023-10/cY9image.png) ### Захватить IP-адрес `\d+\.\d+\.\d+\.\d+` *Ищем числа от одного и более **\\d+**, с точкой и так 4 раза* [](https://kb.kuma-community.ru/uploads/images/gallery/2023-10/untitled.png) ### Захватить слова состоящие из 4 букв `\b[a-zA-Z]{4}\b` *Ищем группу 4 символов из букв и разграничиваем их (boundary) **\\b*** [](https://kb.kuma-community.ru/uploads/images/gallery/2023-10/cCVimage.png) ### Захватить слова состоящие от 3 до 4 букв `\b[a-zA-Z]{3,4}\b` *Ищем группу 4 символов из букв и разграничиваем их (boundary) **\\b*** [](https://kb.kuma-community.ru/uploads/images/gallery/2023-10/cOcimage.png) ### Захватить IPv4 адрес **`\b((2([0-4][0-9]|5[0-5])|[0-1]?[0-9]?[0-9])\.){3}((2([0-4][0-9]|5[0-5])|[0-1]?[0-9]?[0-9]))\b`** [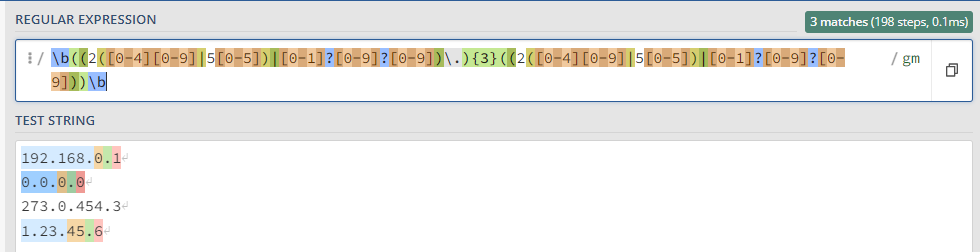](https://kb.kuma-community.ru/uploads/images/gallery/2023-11/Gioimage.png) Более ленивый вариант, но быстрый, без валидации: **`(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})`** [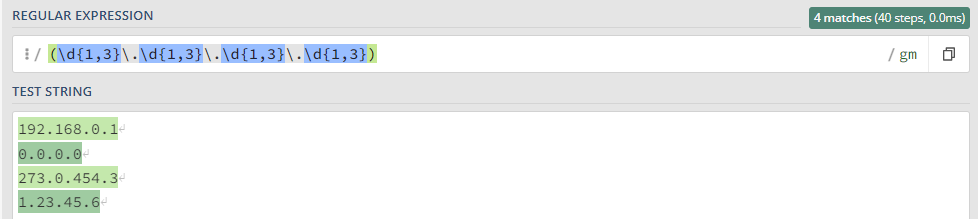](https://kb.kuma-community.ru/uploads/images/gallery/2023-11/XXgimage.png) ### Захватить IPv6 адрес **`(([a-fA-F0-9]{1,4}|):){1,7}([a-fA-F0-9]{1,4}|:) `** [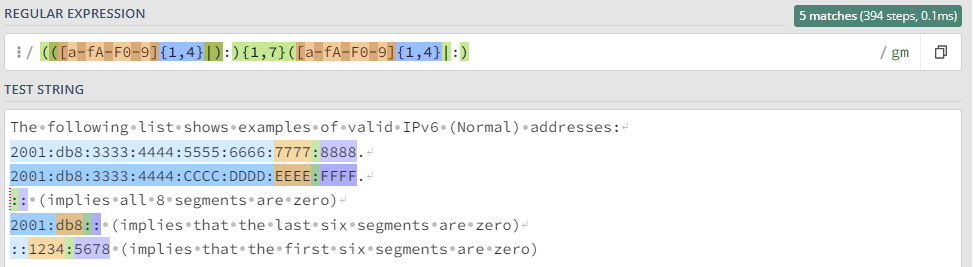](https://kb.kuma-community.ru/uploads/images/gallery/2023-11/huCimage.png) ### Захватить HASH сумму - MD **`^[a-fA-F0-9]{32}$`** - SHA1 **`^[a-fA-F0-9]{40}$`** - SHA256 **`^[a-fA-F0-9]{64}$`** - SHA512 **`^[a-fA-F0-9]{128}$`** ### Захватить URL адрес **`^((https?:\/\/)?([\da-z\.-]+\.[a-z\.]{2,6}|[\d\.]+)([\/:?=&#]{1}[\da-z\.-]+)*\S+)$ `** [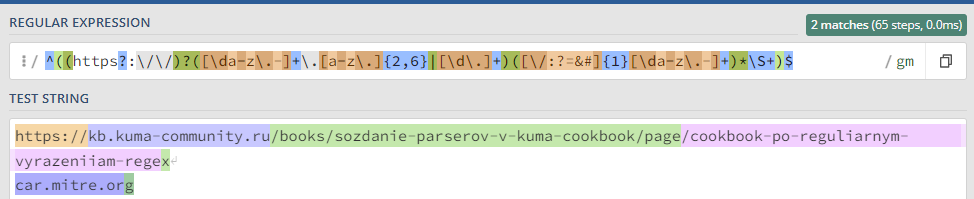](https://kb.kuma-community.ru/uploads/images/gallery/2023-11/p1Timage.png) ### Захватить EMAIL адрес Определяет почти все типы валидных адресов **`\b[\w\.\-\+\!\/\"\%]+@[\w\.-]+(\.\w{2,4})?\b`** [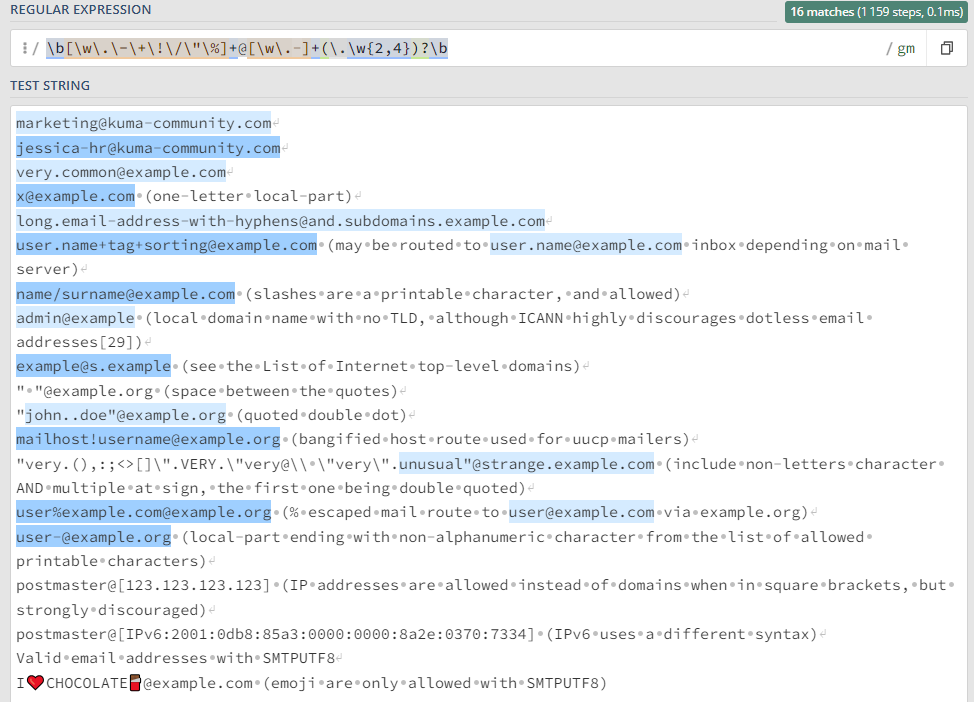](https://kb.kuma-community.ru/uploads/images/gallery/2023-11/uDRimage.png) ### Захватить CSV структуру Создаются группы по значениям из CSV **`(?:\s*(?:\"([^\"]*)\"|([^,]+))\s*,?)+?`** [](https://kb.kuma-community.ru/uploads/images/gallery/2023-11/Byyimage.png) ### Захватить Syslog структуру Разбираются сообщения по rfc [https://datatracker.ietf.org/doc/html/rfc5424](https://datatracker.ietf.org/doc/html/rfc5424) и [https://datatracker.ietf.org/doc/html/rfc3164](https://datatracker.ietf.org/doc/html/rfc3164) **`(?P