CookBook по регулярным выражениям (REGEX)
Проверка работы ругулярок (выставить флаги gm):
Простейшие приемы, практику отработаем на тестовом сообщении:
Message from 127.0.0.1 (localhost): KUMA is the best SIEM in 2023!Захватить строку KUMA.KUMA
KUMA Ищется полное соответствие строке KUMA.

Захватить строку содержащую только буквы.буквы
[A-Za-z]+ Ищем группу ([]) символов с большими (A-Z) и маленькими (a-z) буквами от одной и более (+).

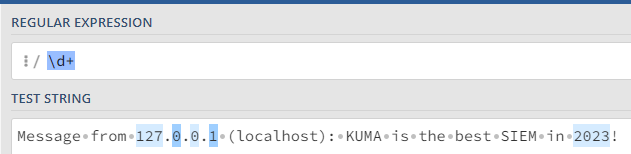
Захватить строку содержащую только числа.числа
\d+ Ищем по токену \d, что является эквивалентом [0-9] от одного и более вхождений (+).

Захватить строку содержащие только числа.
\d+ Ищем по токену \d, что является эквивалентом [0-9] от одного и более вхождений (+).
Захватить строку внутри круглых скобок.скобок
\((\w+)\) Ищем по токену \w, что является эквивалентом [a-zA-Z0-9_] от одного и более вхождений (+), при этом экранируем круглые скобки с помощью обратного слеша \ и строку нашу определяем в группу круглыми скобками ()

Захватить строку до двоеточия
^[^\:]+ Ищем с начала строки ^, далее захватываем в группе все кроме двоеточия (символ двоеточия экранирован) [^\:] от одного и более вхождений (+)

Захватить строку после двоеточия
[^\:]+$ Такая, подобная предствленной выше, конструкция не подойдет, т.к. она будет очень емокой (633 шага). Ищем все кроме двоеточия (символ двоеточия экранирован) [^\:] от одного и более вхождений (+), но до конца строки $

В нашем случае лучше использовать следующее
\:(.*)$ Ищем в строке двоеточие \:, далее захватываем все символы от нуля и более вхождений (*), и берем все что нам нужно в группу ()
