Производительность правил корреляции
Написание правил
В правилах корреляции очередность условий в селекторах имеет значение, НЕ актуально для Коррелятора 2.0 (Correlator-NG)
Уникальные условия надо поднимать вверх в правиле корреляции, чем раньше условие «провалится», тем лучше:
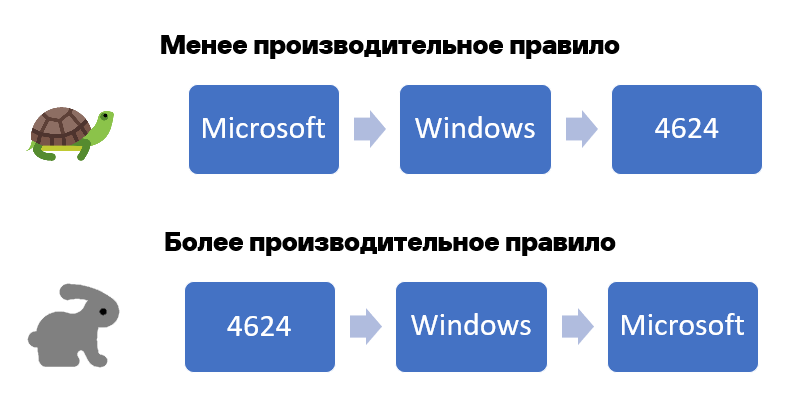
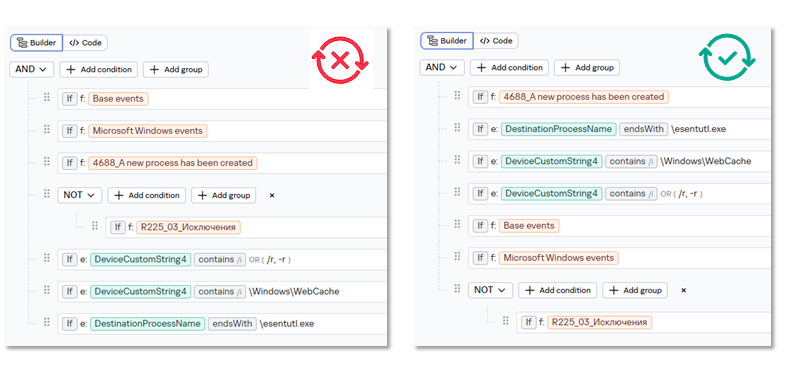
В случае несколльких селекторов, в начале лучше указать жесткое условие (например с "=") с полем из стандартной модели данных (не композитных полей S. или N. и т.д.), а затем условия где используются операторы contains или regex.
Операционные правила должны идти вначале:
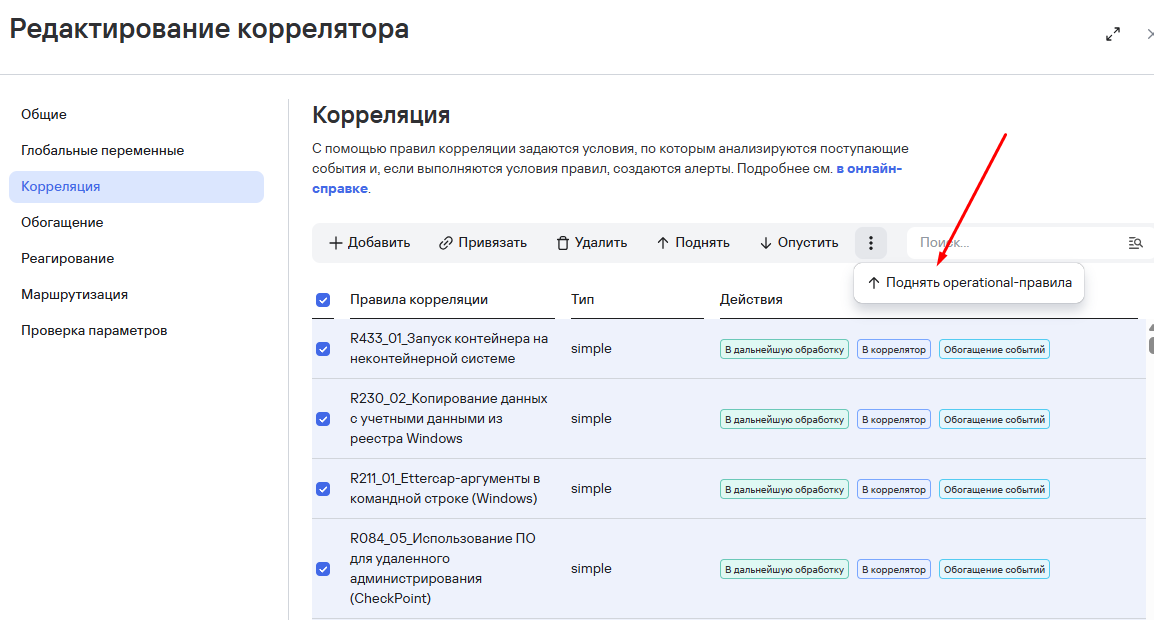
Еще, например, есть правило, в котором в переменную кладется значение из активного листа, а затем эта переменная сравнивается в условии. Так вот в этом случае очередность условий имеет большое значение, так как поменяв условия местами и отодвинув проверку по активному листу в конец, в метриках количество OPS с активным листом уменьшилось со 100000 OPS до 1,1 OPS.
Все поля модели данных ищутся с одинаковой скоростью, а поля *Extra, S, SA, N, NA, F, FA работают медленнее
Значение переменной в селекторе высчитывается в момент, когда событие доходит до этого условия с переменной. Если переменная в группирующих полях, то переменная высчитывается после прохождения всех условий селектора.
При наличии условия с листами, словарями и т.д., отодвигайте их в конец.
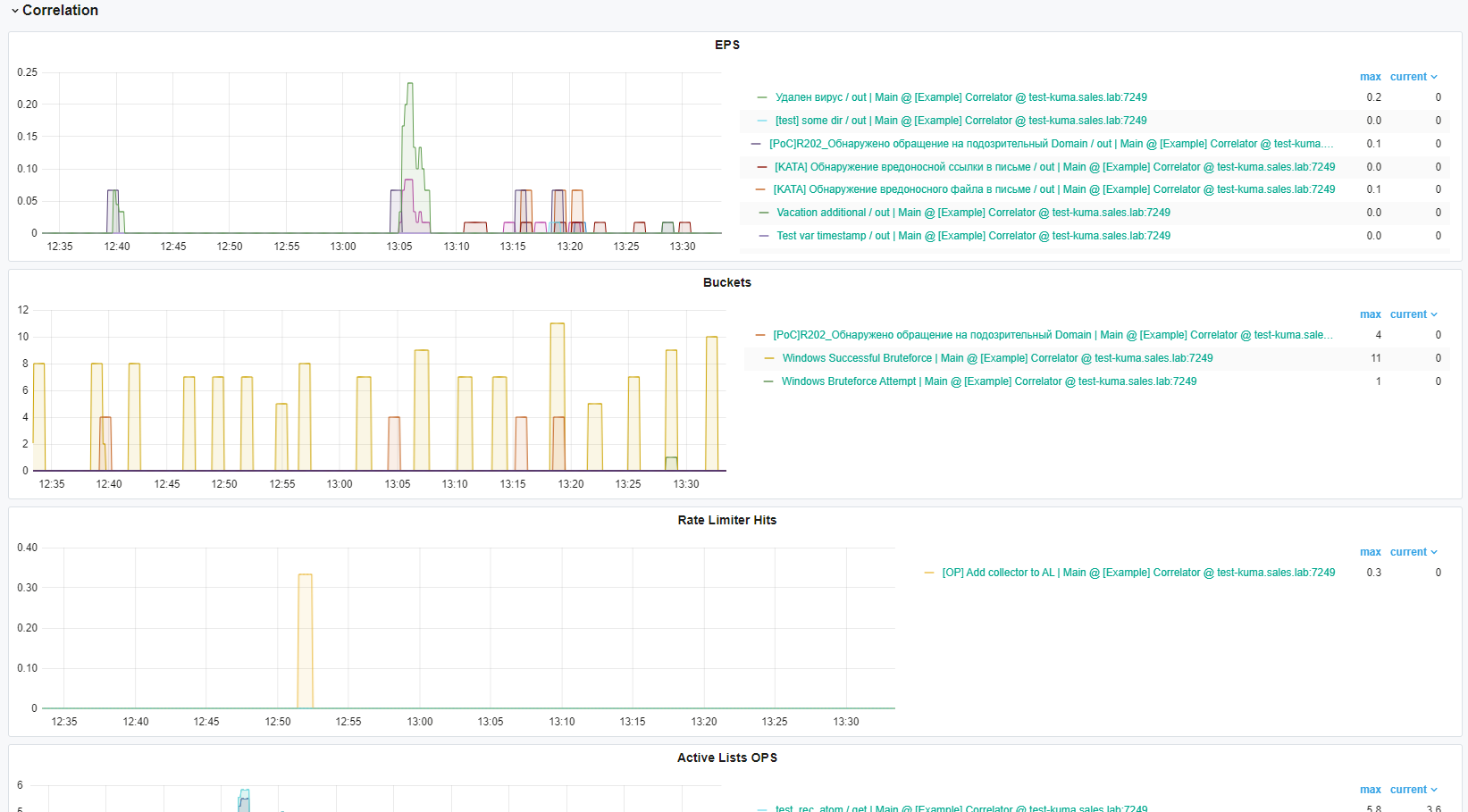
Мониторинг произвоительности
Для мониторинга производительности по корреляции есть метрики, градации веса по операциям в продукте нет, все выполняется быстро благодаря GoLang. Метрики по правилам можно увидеть в разделе метрики, нажав на название “KUMA Collectors” затем выбрав “KUMA Correlators”:
Пример метрик по корреляции:
No comments to display
No comments to display