Установка KUMA с отказоустойчивым ядром - RAFT
Информация, приведенная на данной странице, является разработкой команды pre-sales и/или community KUMA и НЕ является официальной рекомендацией вендора. Официальная документация по данному разделу приведена в Онлайн-справке на продукт: продукт.
Кластер RAFT поддерживается в KUMA с версии 4.0 и позволяет обеспечить доступность компонентов ядра KUMA, в случае сбоя работы одного из компонентов. Допустимо развертывать только нечетное количество сервисов Ядра KUMA.
Теория
В кластере Raft каждый из серверов в каждый момент времени находится в одном из трёх состояний:
- Leader (лидер) – обрабатывает все клиентские запросы, является source of truth всех данных в логе, поддерживает лог фоловеров.
- Follower (фоловер) – пассивный сервер, который только «слушает» новые записи в лог от лидера и редиректит все входящие запросы от клиентов на лидера. По сути, является hot-standby репликой лидера.
- Candidate (кандидат) – специальное состояние сервера, возможное только во время выбора нового лидера.
Во время нормальной работы в кластере только один сервер является лидером, все остальные – его фоловеры.
Например, в случае 3 компонентов ядра из строя может выйти толкьо 1 компонент, для иного количества компонентов - пока работает формула n+1/2. Полезная ссылка:ссылка для понимания механизма работы: https://thesecretlivesofdata.com/raft/
Расширение ядра до кластера в Raft
Сценарии установки с установкой Ядра в кластере Raft смотреть можно тут
Данный сценарий реализуется, если KUMA уженаходится в инсталяцииинсталяции, All-in-one.где одно ядро (standalone). Для этого необходимо подготовить дополнительные целевые машины для установки сервисов, а также на контрольной машинке настроить обмен SSH ключами.
После скопироватьсоздать файлкопию файла на контрольной машинкемашине (с которой предполагается развертывание) expand.inventory.yml.template ииз создатьраспакованного егоархива копиюKUMA
cp expand.inventory.yml.template expand.inventory.yml
Далее отредактировать файл expand.inventory.yml (разворачиваем дополнительные ядра 2 и 3):
Например, только для распределения ядра:
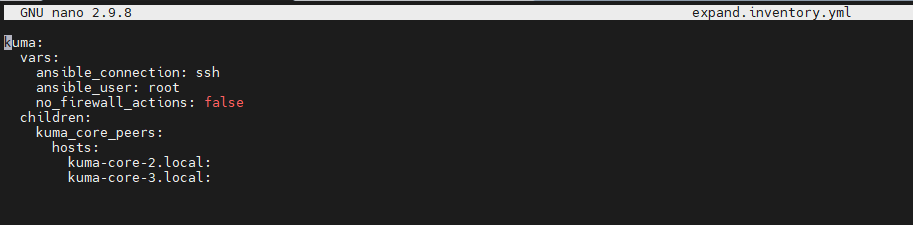
В хостах указываем FQDN и проверяем их доступность с контрольной машины, а также на всех компонентах ядра должно быть единое время, настройте на всех машинах NTPNTP.
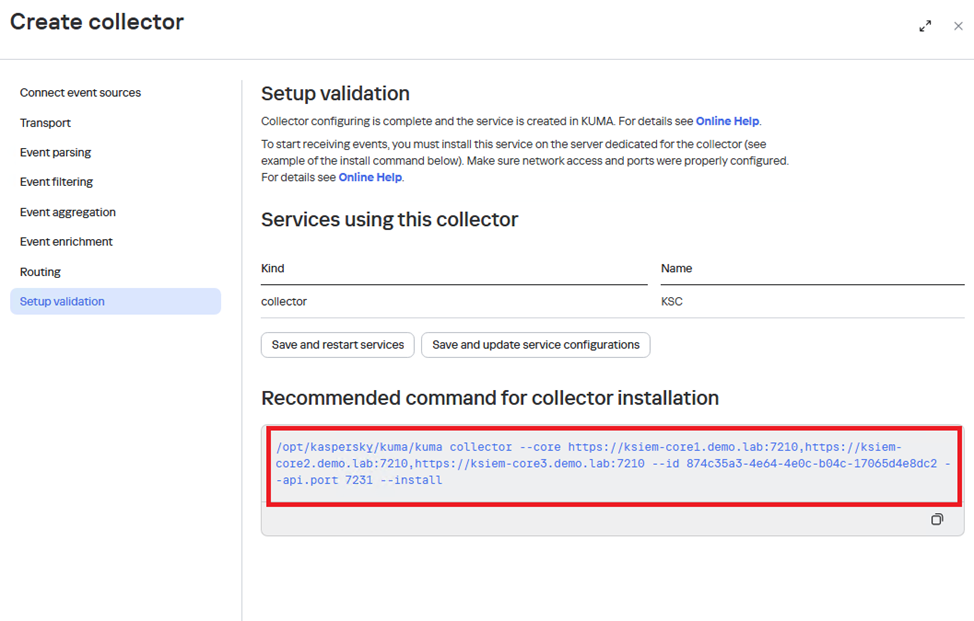
Далее на контрольной машине с доступом root из папки с распакованным установщиком (скриншот выше) выполните следующую команду для начала установки:
./expand.sh expand.inventory.ymlВ результате выполнения команды на каждой целевой машине, указанной в файле инвентаря expand.inventory.yml, появятся файлы для создания и установки дополнительных сервисов Ядра KUMA, для этого проверьте наличие директории /opt/kaspersky/kuma/kuma
Создание клиентской части сервиса Ядра KUMA в веб-интерфейсе на контрольной машине
В разделе Ресурсы → Активные сервисы нажмите Добавить и в раскрывающемся списке выберите Добавить сервис Ядро.
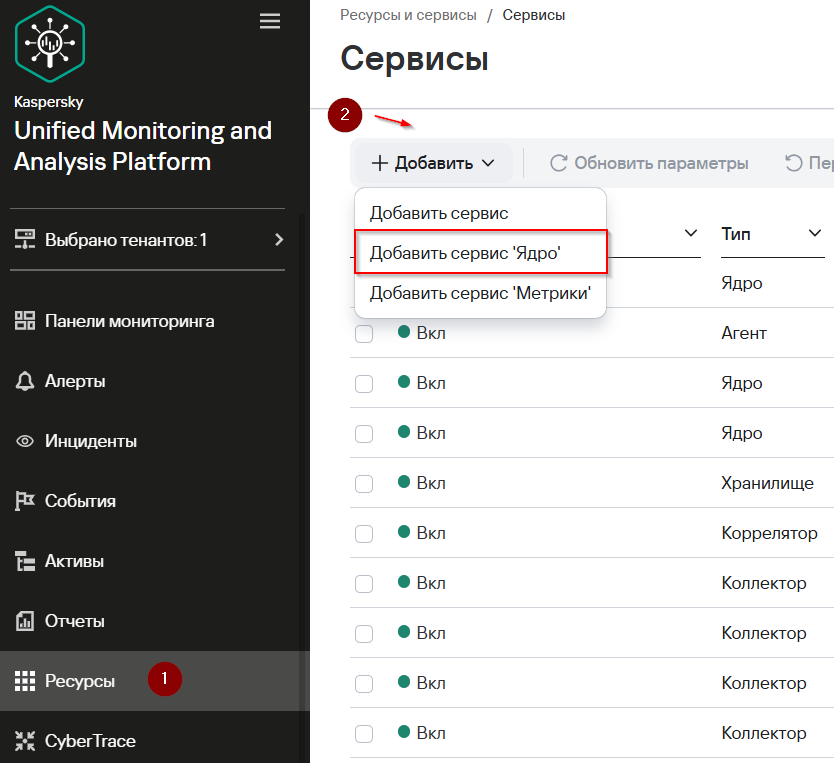
В открывшемся окне Добавить сервис Ядро укажите имя сервиса в поле Имя сервиса Ядро и нажмите Добавить.Добавить. Добавленный сервис появится в списке Сервисы.Сервисы.

Установите флажок рядом с добавленным сервисом Ядра KUMA и на панели инструментов нажмите  , в открывшемся меню нажмите Копировать
, в открывшемся меню нажмите Копировать идентификатор.идентификатор. Идентификатор сервиса Ядра KUMA понадобится для установки сервиса на сервере.
Создание
Далее серверной части сервиса Ядра KUMA
Нана целевой машине выполнитенеобходимо следующуюустановить команду.службу специальным образом:
sudo /opt/kaspersky/kuma/kuma core --raft.join <FQDN хоста из секции kuma_core, где запущен первый сервис Ядра KUMA>:7210 --id <идентификатор сервиса Ядра KUMA, скопированный в веб-интерфейсе> --installПовторите создание клиентской и серверной части сервиса Ядра KUMA для каждого хоста из группы kuma_core_peers.
На каждом хосте может быть установлен только один сервис Ядра KUMA.
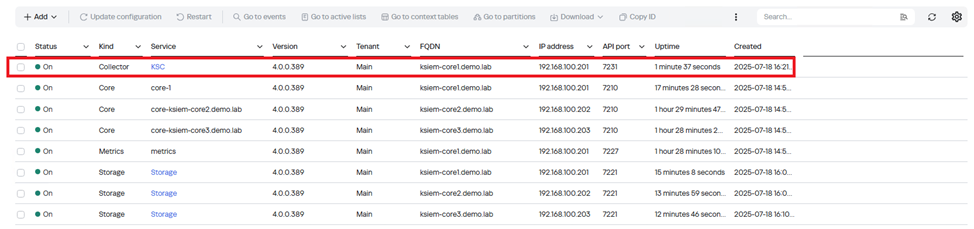
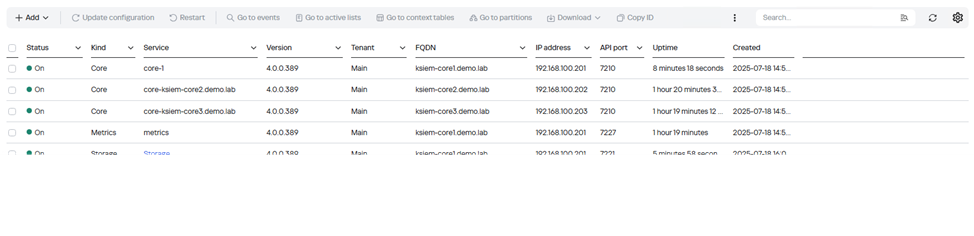
После успешной установки в веб-интерфейсе KUMA, вы увидеть статус сервисов Вкл

Если ведущий узел выходит из строя, сервер будет следовать за новым ведущим, обеспечивая непрерывный доступ к интерфейсу SIEM или API.
Журналы Ядра KUMA хранятся в директории /opt/kaspersky/kuma/core/<идентификатор сервиса Ядра KUMA>/log/core.
Вариант 1. Установка балансировщика - nginx
Установим балансировщик нагрузки nginx для удобства работы с кластером Raft, а именно обращение по единому hostname / IP-адресу.
Когда одна из нод кластера отказывает, балансировщик перенаправляет запросы на активные ноды
Для установки балансировщика поднимем отдельный сервер и на него установим nginx, далее необходимо отредактировать файл /etc/nginx/nginx.conf и добавить конфиг в конец файла
stream {
upstream raft_backend {
server kuma-test.local:7220 max_fails=1 fail_timeout=5s;
server kuma-core-2.local:7220 backup;
server kuma-core-3.local:7220 backup;
}
server {
listen 443;
proxy_pass raft_backend;
ssl_preread on;
}
}Далее перезапустить сервис systemctl restart nginx.service
Для проверки работоспособности отключаем сервис ядра на kuma-test командой systemctl stop kuma-core-<идентификатор-ядра>.service. В браузере вводим https://<ip-балансировщика>, появится форма входа в интерфейс.
Далее нужно перейти в "Ресурсы" -> "Активные сервисы". Увидим, что сервис ядра отключен, но независимые компоненты имеют Статус: "Вкл"
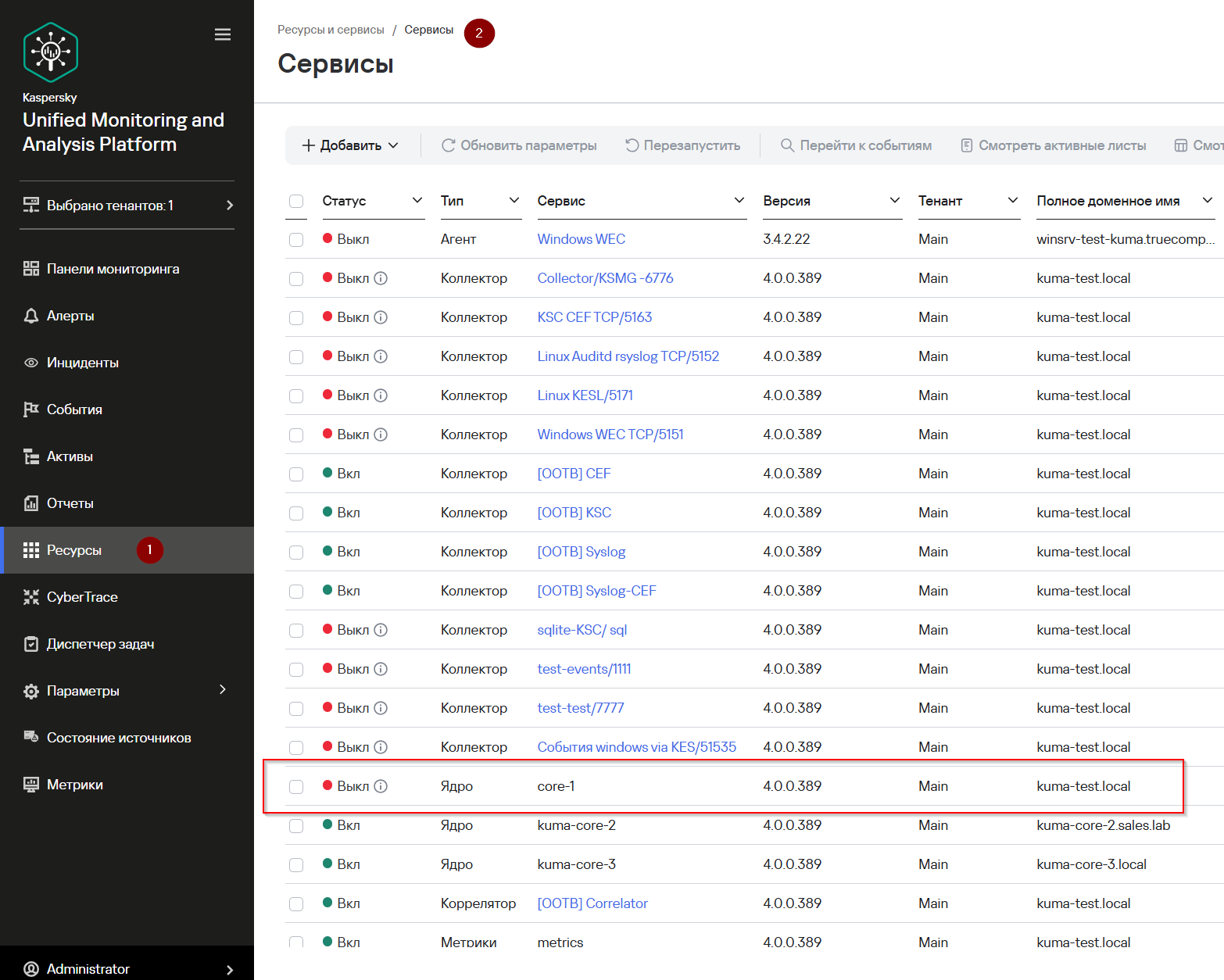
Не забудьте запустить службу отключенного компонента, ядра systemctl start kuma-core-<идентификатор-ядра>.service
В данном случае в кластере всего три ноды, и больше одного выведенного из строя компонента ядра нельзя себе позволить, поскольку с менее чем 2 рабочими нодами теряется доступ к системе и перестает работать кластер
В основу алгоритма Raft заложено понятие кворум - минимальное количество нод, необходимое для принятия решений, или большинство. При большинстве рабочих нод в кластере можно проводить голосование, выбирать лидера и принимать изменения
В нашем случае, если останется 1 живая нода - не сработает. Нода не образует кворум, а если захочет стать лидером, это никто не подтвердит.
Возможные ошибки кластера ядра:
Если вы столкнулись с ошибками после установки балансировщика, примеры:
request dropped as the cluster is not ready
failed to lookup: can't serve requests, not enough healthy nodes
Убедитесь, что у вас достаточное количество рабочих нод в кластере для его работы.
ВариантАльтернатива 2.балансировщику - Установка, использующая параметрустановка keepalived
В основу данного способа заложена интеграция виртуального IP-адреса (VIP) с использованием функции keepalived для предоставления единой точки доступа. Такая конфигурация обеспечивает автоматическое переключение между узлами при отказе. На каждом запускается скрипт для мониторинга состояния соответствующей службы ядра. Все узлы обслуживают веб-интерфейс через собственные полные доменные имена (FQDN), но VIP обеспечивает унифицированный и стабильный доступ, обеспечивая доступность без вмешательства пользователя. 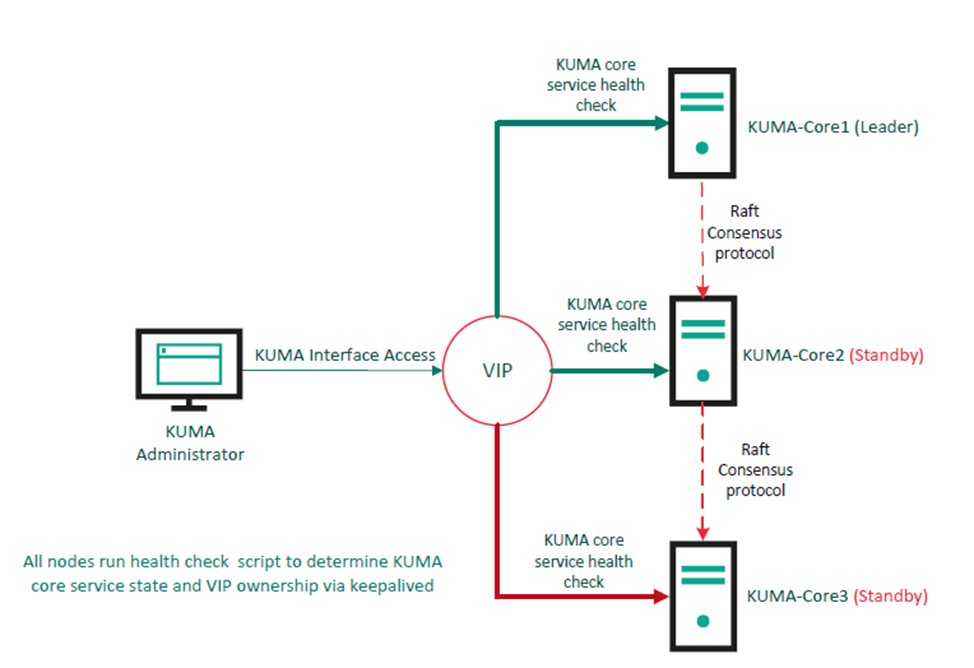
Детализация демонстрационных машин

Мы также рекомендуем предоставлять отдельный сервера для каждого компонента.
После подготовки файла distributed.inventory.yml, необходимо сконфигурировать VIP для всех нод
Установка Keepalived на все основные узлы:
dnf install -y keepalived
Для каждого узла требуется собственный скрипт для мониторинга локальной службы KUMA Core. Сохраните скрипт как /etc/keepalived/check_kuma.sh.
Пример для Core1 (ksiem-core1):
#!/bin/bashifbash
if systemctl is-active --quiet kuma-core-00000000-0000-0000-0000-000000000000; then
exit 0else0
else exit 1fi1
fi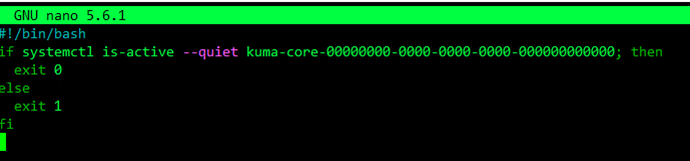
Настройте имя службы для каждого узла (каждый имеет уникальное имя). Вы можете найти основную службу KUMA, выполнив команду на каждом узле:
systemctl list-units --type=service | grep kuma-core
Сделайте скрипт исполняемымисполняемым:
chmod +x /etc/keepalived/check_kuma.sh
далееДалее настройте keepalived. Создайте или отредактируйте файл /etc/keepalived/keepalived.conf на каждом узле. Ниже представлена адаптированная конфигурация.
Core -1
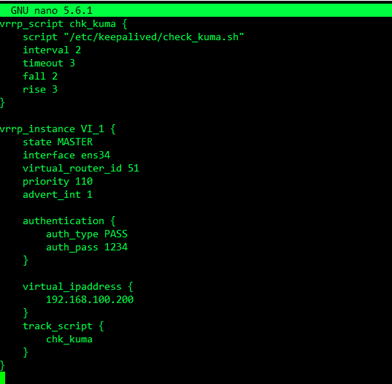
vrrp_script chk_kuma {
script "/etc/keepalived/check_kuma.sh"
interval 2
timeout 3
fall 2
rise 3
}
vrrp_instance VI_1 {
state MASTER
interface ens34 #необходимо поменять в соотетсвии со своей конфигурацией
virtual_router_id 51
priority 110
advert_int 1
authentication {
auth_type PASS
auth_pass secretpass
}
virtual_ipaddress {
192.168.100.200
}
track_script {
chk_kuma
}
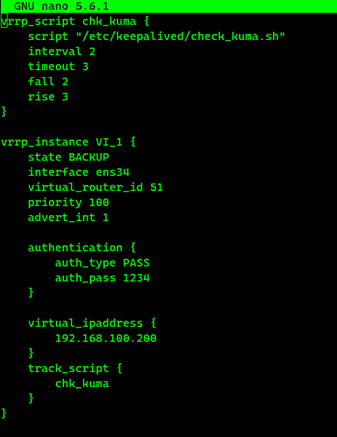
} Core -2
vrrp_script chk_kuma {
script "/etc/keepalived/check_kuma.sh"
interval 2
timeout 3
fall 2
rise 3
}
vrrp_instance VI_1 {
state BACKUP
interface ens34 #поменяйте в соответcвии со своими параметрами
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass secretpass
}
virtual_ipaddress {
192.168.100.200
}
track_script {
chk_kuma
}
}
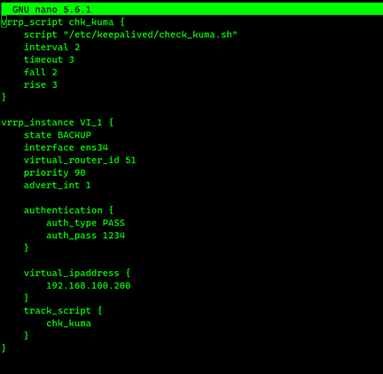
Core - 3
vrrp_script chk_kuma {
script "/etc/keepalived/check_kuma.sh"
interval 2
timeout 3
fall 2
rise 3
}
vrrp_instance VI_1 {
state BACKUP
interface ens34 #поменяйте в соответcвии со своими сетевыми параметрами
virtual_router_id 51
priority 90
advert_int 1
authentication {
auth_type PASS
auth_pass secretpass
}
virtual_ipaddress {
192.168.100.200
}
track_script {
chk_kuma
}
}
Далее выполните команды
systemctl enable keepalived
systemctl start keepalivedsystemctl start keepalived
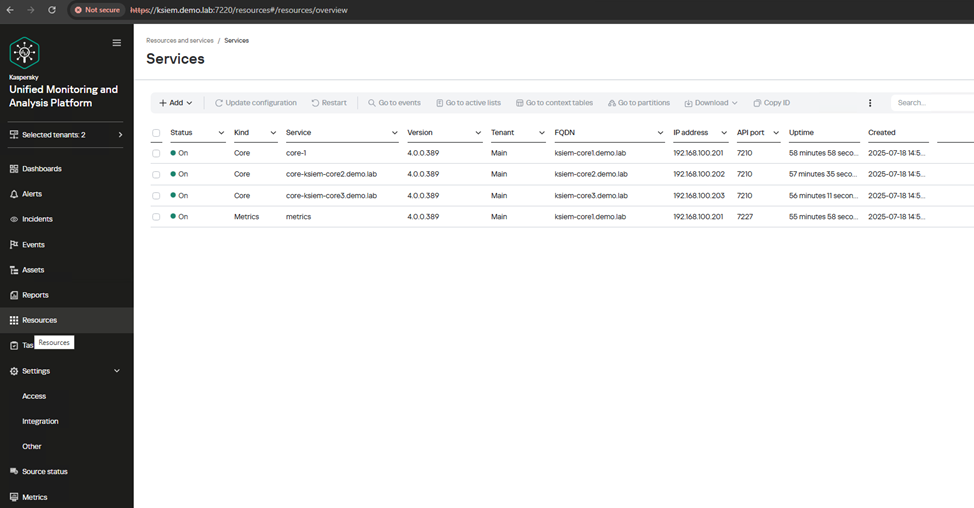
Зайдите в веб-интерфейс KUMA через VIP FKDN (ksiem.demo.lab) активируйте KUMA и убедитесь, что все ноды сервисов установлены и их статус “зеленый”"зеленый"
Возможные проблемы: проблемы
Проблема 1
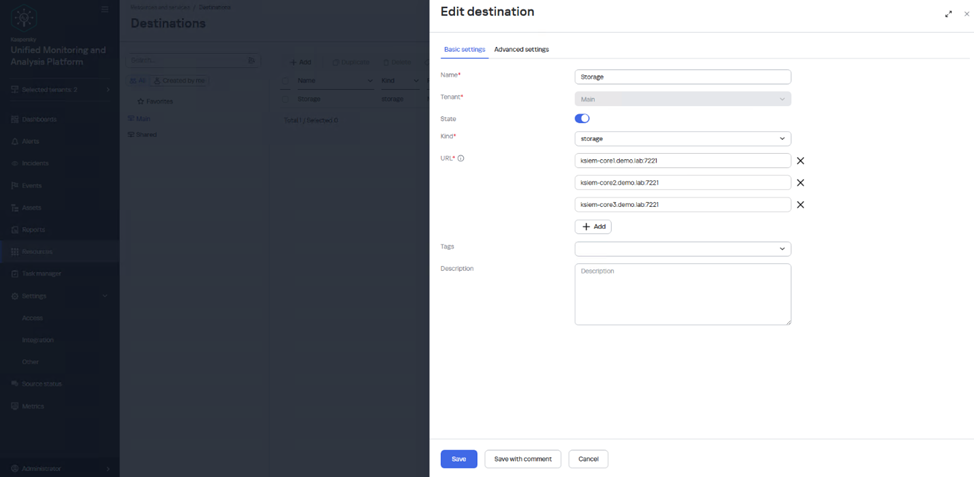
Когда устанавливается сервис хранилища или другие ноды хранилища, необходимо указать все FQDN ядер в команде, ниже представлен пример того, как установить хранилище в Raft -е ( 2 replica и 3 keeper)
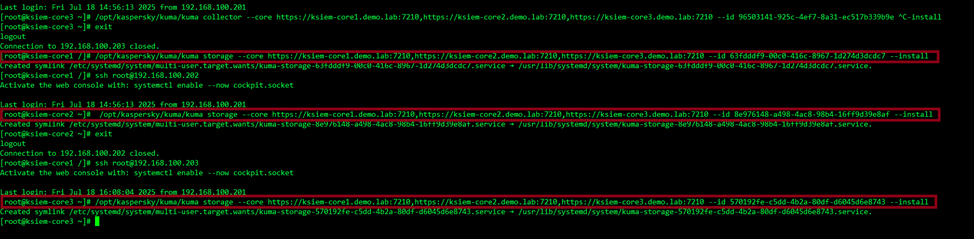
Добавляем хранилища в destination
Проблема 2. Как коллектор и коррелятор будут работать в этом режиме?
Когда вы создаете коллектор или коррелятор, все 3 ноды автоматически добавятся в скрипт, запустите этот скрипт на сервере (коллектора или коррелятора), в этом случае, если core1 упадет, то вы все равно будете иметь доступ к настройкам коррелятора или коллектора