Настройка отказоустойчивости компонентов KUMA
Отказоустойчивость реализована встроенным функционалом KUMA для компонентов: Коррелятор и Хранилище (подробнее про кластер Хранилища). Для компонента Коллектор отказоустойчивость системы достигается за счёт комбинации наложенных средств HAProxy, Агента KUMA или другого балансировщика.
Отказоустойчивость компонентов KUMA можно обеспечить на уровне виртуализации
Отказоустойчивость Коррелятора и Хранилища
Детальнее про устройство кластера хранилища и комопонет keeper - тут
Предварительно устанавливается дублирующий компонент на отдельных от первого ресурсах (процесс установки не будет показан в этой инструкции). Ниже будет показан пример настройки для Коррелятора, для Хранилища процесс аналогичный.
В Точках назначения добавляется второй компонент Коррелятора с его API портом для работы.
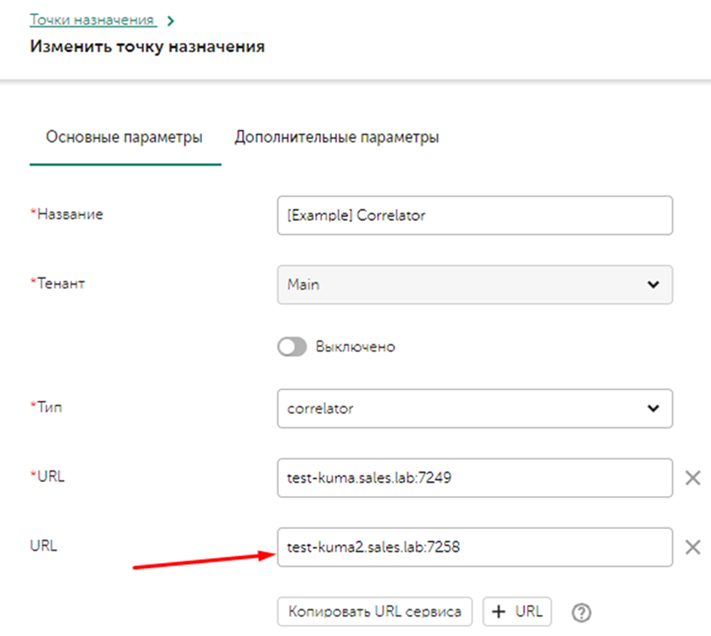
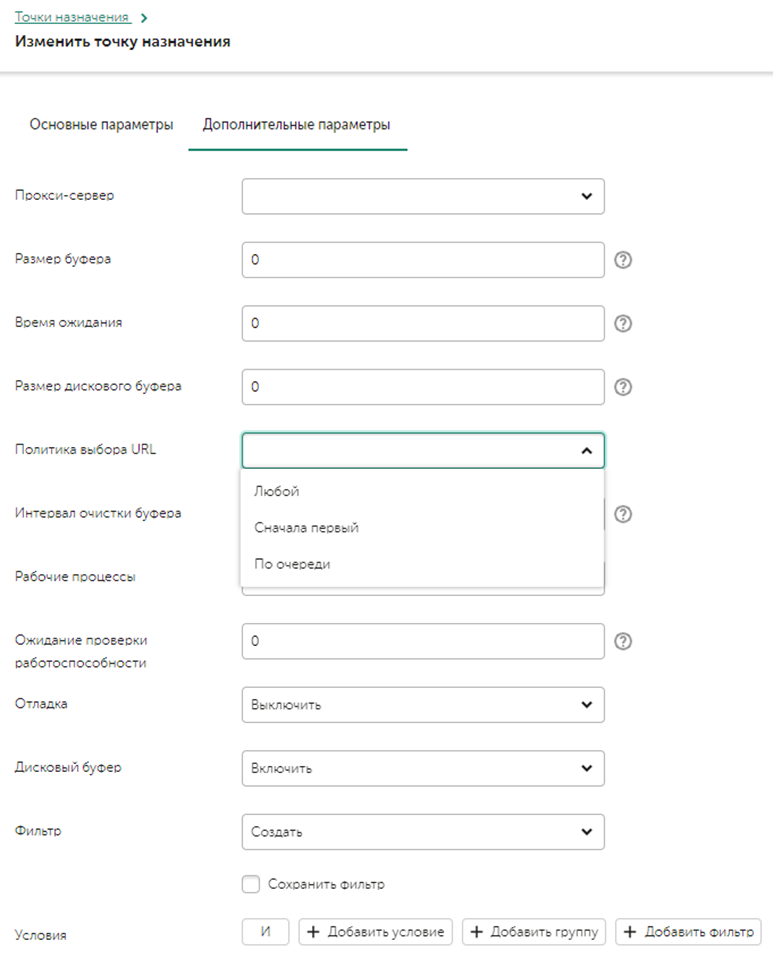
Далее необходимо перейти во вкладку дополнительные параметры, нас интересует параметр Политика выбора URL (URL selection policy), ниже описаны детали каждого метода:
- Любой (Any) - выбор любого доступного узла для отправки событий. Если в начале был выбран узел URL1, то события будут лететь в него до тех пор, пока он доступен, в случае выхода его из строя - будет выбран узел URL2, который тоже будет получать события пока сам не выйдет из строя. И так пока не закончатся активные узлы.
- Сначала первый (Prefer First) (рекомендуется для корреляторов) - события отправляются в URL1 до тех пор, пока сервис (URL1) живой. Если он выйдет из строя, события полетят в URL2. Когда URL1 снова станет активным, поток снова направится в него.
- По очереди (Round robin) (рекомендуется для хранилищ и агента KUMA для балансировки коллекторов) – отправляются события не по одному, а пачками. Количество событий в пачке почти всегда будет уникальным - пачка формируется, либо когда достигнут лимит ее размера, либо когда сработает таймер. Каждый URL получит равное количество пачек.
Параметр Ожидание проверки работоспособности (Health check timeout) – задает периодичность запросов Health check.
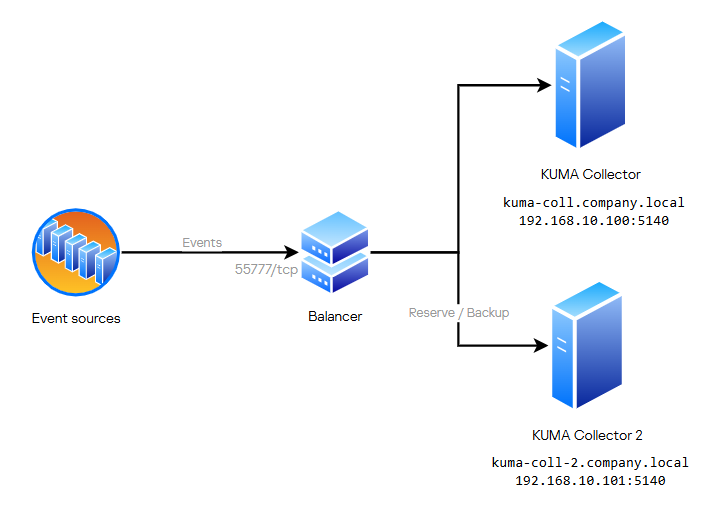
Отказоустойчивость Коллектора
Предварительно устанавливается на отдельную машину в качестве наложенного средства балансировщик HAProxy для своей версии ОС (процесс установки не будет показан в этой инструкции). Для Oracle Linux 8.x пакет установки HAProxy можно загрузить по ссылке - https://rpmfind.net/linux/RPM/centos/8-stream/appstream/x86_64/Packages/haproxy-1.8.27-5.el8.x86_64.html
Также можно использовать агента KUMA для балансировки трафика, подробнее тут.
Настроим балансировку потока событий для двух коллекторов:

Конфигурация HAproxy будет следующая (путь файла конфигураций по умолчанию - /etc/haproxy/haproxy.cfg):
defaults
timeout connect 5s
timeout client 1m
timeout server 1m
listen collectorTEST
bind *:55777
mode tcp
balance roundrobin
server tcp1 <IP_КОЛЛЕКТОРА_1>:5577 check
server tcp2 <IP_КОЛЛЕКТОРА_2>:5577 backup checkБалансировщик прослушивает порт 55777, вы можете поменять конфигурацию порта на свое.
Опция backup используется для того, чтобы использовать этот (сервер с этой опицей) сервер в случае отказа первого.
Для запуска HAproxy:
haproxy -D -f /etc/haproxy/haproxy.cfg -p /var/run/haproxy.pid -sf $(cat /var/run/haproxy.pid)Для остановки HAproxy:
pkill haproxyДля типа коннектора SQL прокси не подойдет и потребуется написание скрипта для реализации следующего:
- создано 2 микросервиса коллектора SQL с одним конфигом
- установлены на сервера Coll-A и Coll-B
- один микросервис включен, второй - выключен
- у каждого из них сервисов в точке монтирования какая-то сетевая папка /opt/kaspersky/kuma/collector/<ID>/sql/ т.е. стейт (состояния) с позициями, которые уже были загружены из базы будут общими
- скрипт произаодит мониторинг за событиями аудита KUMA и если "микросервис перешел из зеленого в красный" и как только один SQL коллектор на сервере A стал красным - запускаем скриптом микросервис на сервере B и он начнет читать из базы из того же места (где остановился сервис А)
Отказоустойчивость за счет Rsyslog: Управление потоком событий с помощью rsyslog (kaspersky.com)
На всех комопнентах, где присутсвует точка назначения возможно настроить буферизацию (ОЗУ и на диске), в случае если точка назначения недоступна.
При накоплении буфера и если realtime поток событий от источника большой, то, например, коллектор подмешивает к потоку события в точку назначения из дискового буфера в соотношении 70% realtime + 30% из дискового буфера
Отказоустойчивое ядро
HA ядра доступно для версии KUMA 2.1 и выше
Подробные детали по этой теме можно прочитать тут:
- https://kb.kuma-community.ru/books/ustanovka-i-obnovlenie/page/ustanovka-kuma-versii-ot-21x-s-otkazoustoicivym-iadrom
- https://kb.kuma-community.ru/books/ustanovka-i-obnovlenie/page/ustanovka-kuma-s-otkazoustoicivym-iadrom-raft
В случае выхода из строя ядра, остальные компоненты будут продолжать корректно функционировать, тк у них в памяти сохраняется конфигурация от ядра (если не перезагружать компоненты).
Т.к. в НА ядра, что в RAFT и Kubernetes (Control Plane) кластер нормально работает пока живы (n+1)/2 компонентов и в случае острой необходимости отказо- и катастрофо- устойчивости для двух ЦОДов, рекомендуется применять, мы это называем "3-й глаз":
3-й глаз / голос (witness / tie-breaker), где добавляется третий участник кворума (с минимальными ресурсами), который:
- не является полноценным ЦОДом
- Это:
- небольшой VM в облаке
- отдельная площадка
- Lightweight-node
- машина "3-й глаз" должна быть очень стабильной по сети
Отказоустойчивые балансировщики
- Ручное резервирование LB (Load Balancer). можно создать клон виртуальной машины с LB или скопировать конфигурацию на резервный "железный" сервер и в случае необходимости переключить трафик на резерв руками или с помощью какой-либо автоматизации. Возможны длительные задержки с момента обнаружения проблемы с LB до момента переключения трафика на резервный LB. FQDN и IP LB при этом переносятся на резервный хост;
- Можно использовать службу keepalived, позволяющая использоватьVRRP, пример настройки: https://docs.oracle.com/en/operating-systems/oracle-linux/6/admin/section_sm3_svy_4r.html. В качестве tcp балансировщиков могут выступать машины с nginx или haproxy. Переключение на резервный балансировщик при этом осуществляется автоматически. Такой подход может оказаться неприменим при размещении хостов с tcp балансировщиками в разных data-центрах, т.к. они использует VRRP;
- Для Nginx можно использовать коммерческую версию, пример - https://www.nginx.com/products/nginx/high-availability/;
- Отказоустойчивость компонентов также можно обеспечить функционалом систем виртуализации;
- Использование GSLB или других DNS-based балансировщиков "поверх" tcp LB, при такой схеме можно не покупать коммерческий Nginx.
No comments to display
No comments to display