Приемы парсинга событий
Парсинг нестандартной даты
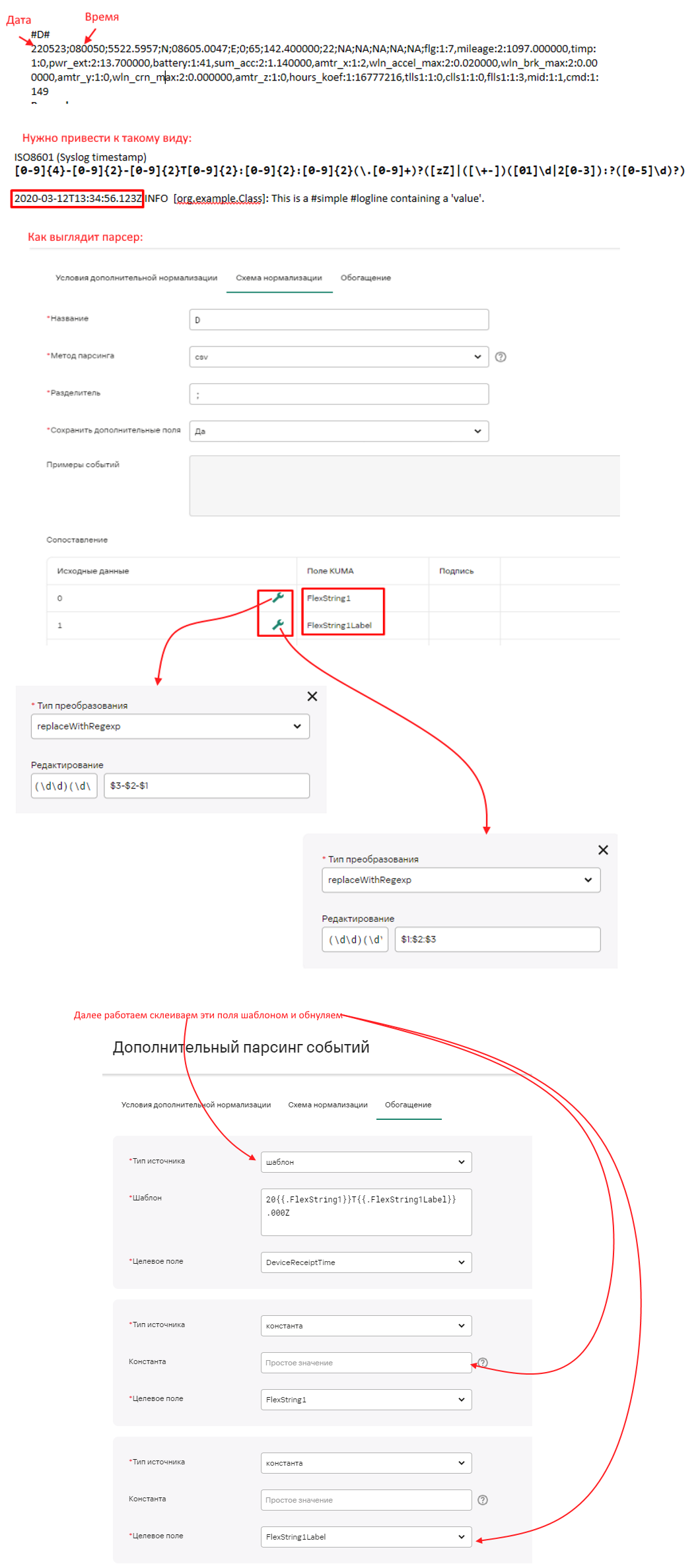
Ветвление событий от beats в зависимости от input типа
Даны следующие типы событий (содержимое тестового сообщения сокращено для лучшего понимания):
{"tags":["beats_input_raw_event"],"input":{"type":"filestream"}}
{"message":"I0130 14:38:47.090079 1837403 utils.go:187] ID: 544472 GRPC response: {}","input":{"type":"container"}}
{"journal":{"system":"true"},"tags":["beats_input_codec_plain_applied"],"input":{"type":"journald"}}
{"input":{"type":"journald"},"journal":{"system":"true"},"tags":["beats_input_codec_plain_applied"]}
{"journal":{"system":"true"},"input":{"type":"journald"},"tags":["beats_input_codec_plain_applied"]}Необходимо в парсинге разветлять (тк у каждого типа свой набор полей) парсинг в зависимости от типа input поля, мы имеем три типа в данном примере:
- "input":{"type":"container"}
- "input":{"type":"journald"}
- "input":{"type":"filestream"}
Причем, поле input может находиться как в начале, так и в середине, и в конце сообщения. Поэтому для ветвления в первом шаге парсинга будут использоваться регулярные выражения:
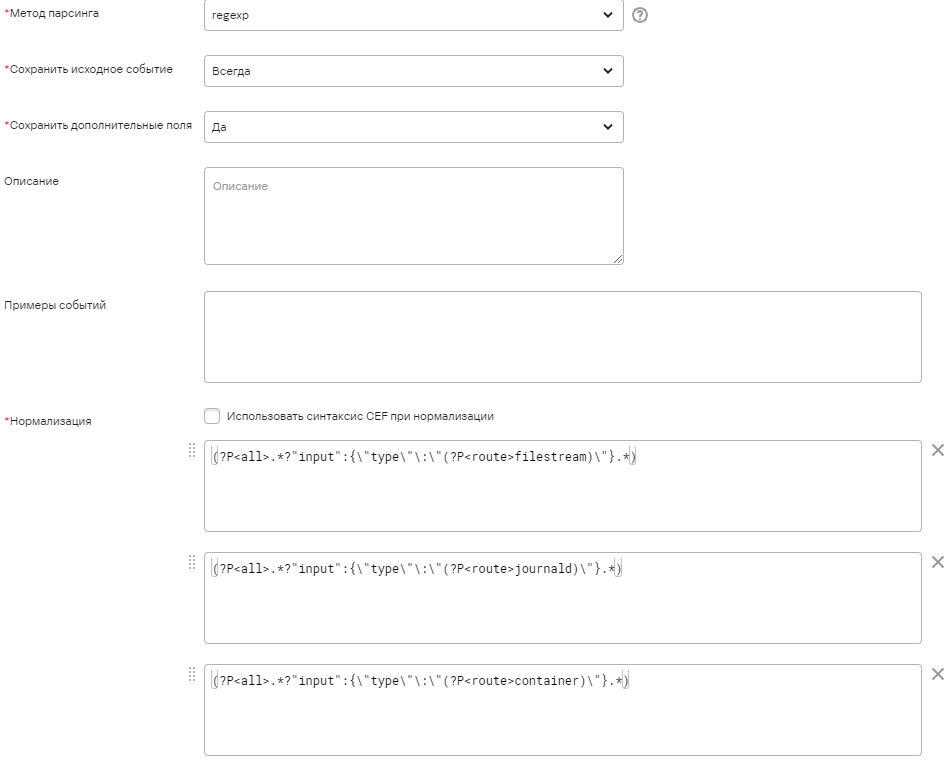
Поле из regex с наименованием route будет использоваться для маршрутизации по условию в нужный парсер, поле all необходимо для передачи полного содержимого в подпарсер. Структура парсера выглядит следующим образом:
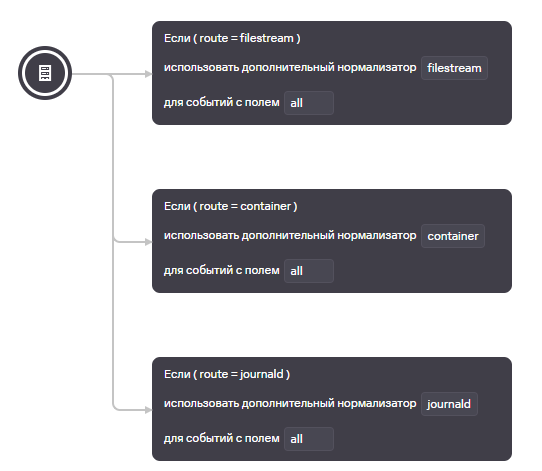
Рассмотрим один подпарсер, например, filestream:
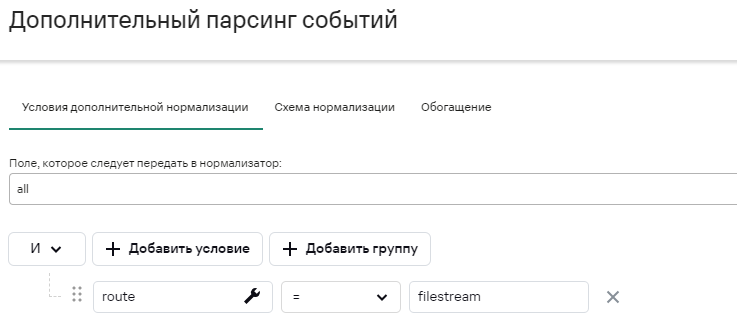
Тк общая структура сообщения формата JSON, используется соответсвующий коробочный парсер:

Парсинг массивов
Актуально для KUMA 3.0+
В KUMA 3.0.2 появилась возможность создания кастомных полей типа "массив" (SA, NA, FA), доступные для методов парсинг JSON и KV. Чтобы записать массив в дополнительное поле, достаточно его указать в маппинге:
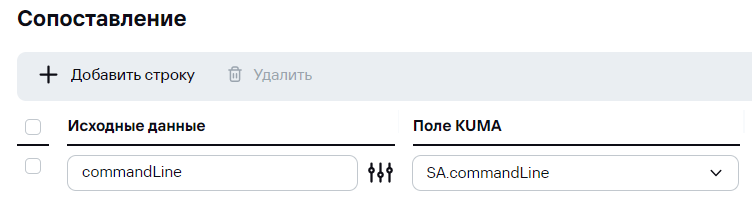
В событии это будет выглядеть следующим образом:
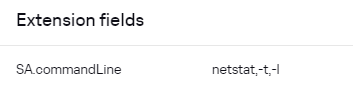
Если с массивом в таком случае работать не удобно и нужно все элементы из массива "склеить" через делиметр и записать в отдельное поле, можно воспользоваться обогащением. Для этого сначала массив мапится на строковое поле:
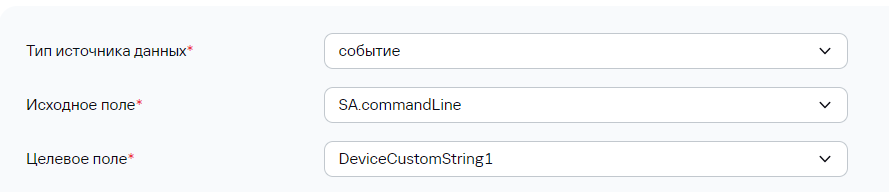
В таком случае в событии данное поле будет представлять собой массив переведенный в строку:

Чтобы привести ее в более "приятный" вид можно выполнить следующие преобразования:
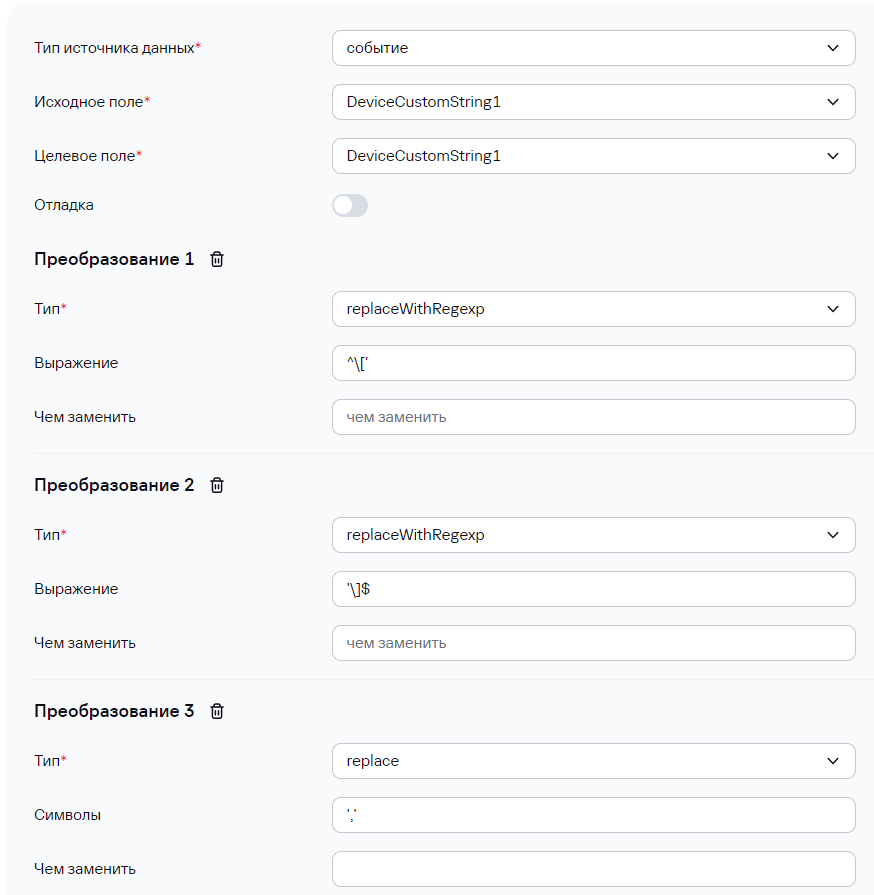
После этого в DeviceCustomString1 будут записаны все элементы массива через выбранный в последнем (3) преобразовании делиметр (в данном примере это "пробел"):

Передача сырого события в экстранормализатор, для доступа к элементам массива
Актуально для KUMA 3.0+
Для передачи «сырого» события в экстра-нормализатор необходимо:
- открыть нормализатор событий;
- перейти в меню «Условия дополнительной нормализации»;
- активировать параметр «Использовать сырое событие».
По умолчанию параметр «Использовать сырое событие» не активен.
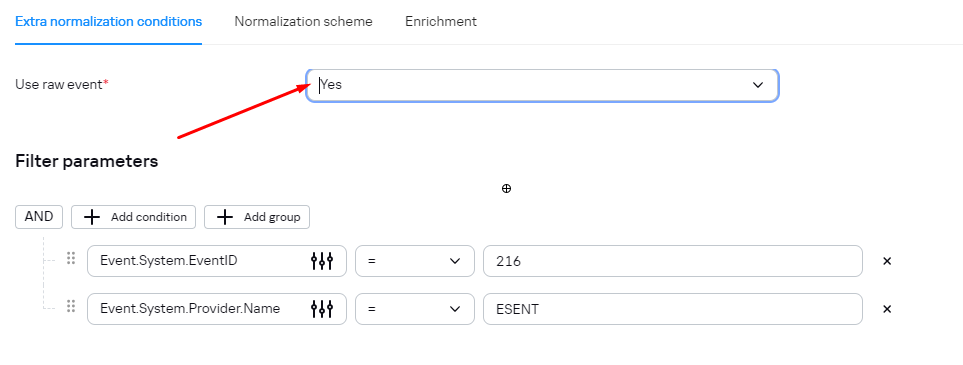
Рекомендуется активировать параметр «Использовать сырое событие» в нормализаторах типа «xml», «json».
Для передачи «сырого» события в экстра-нормализатор второго, третьего и более глубоких уровней вложенности необходимо последовательно включить параметра «Использовать сырое событие» в каждом экстра-нормализаторе по пути следования события в целевой экстра-нормализатор и непосредственно в целевом экстра-нормализаторе.
В качестве примера работы данной функции вы можете обратиться к нормализатору Microsoft Products для KUMA 3.0.1: параметр «Использовать сырое событие» включен последовательно в экстра-нормализаторах «AD FS» и «424».
В качестве примера, событие:
<Event xmlns='http://schemas.microsoft.com/win/2004/08/events/event'><System><Provider Name='ESENT'/><EventID Qualifiers='0'>216</EventID><Level>4</Level><Task>3</Task><Keywords>0x80000000000000</Keywords><TimeCreated SystemTime='2024-01-20T20:06:07.144730300Z'/><EventRecordID>870234</EventRecordID><Channel>Application</Channel><Computer>COMPANY.COM</Computer><Security/></System><EventData><Data>lsass</Data><Data>724,R,98</Data><Data></Data><Data>C:\Windows\NTDS\ntds.dit</Data><Data>\\?\GLOBALROOT\Device\HarddiskVolumeShadowCopy50\Windows\NTDS\ntds.dit</Data></EventData></Event>
При парсинге ID события 216:
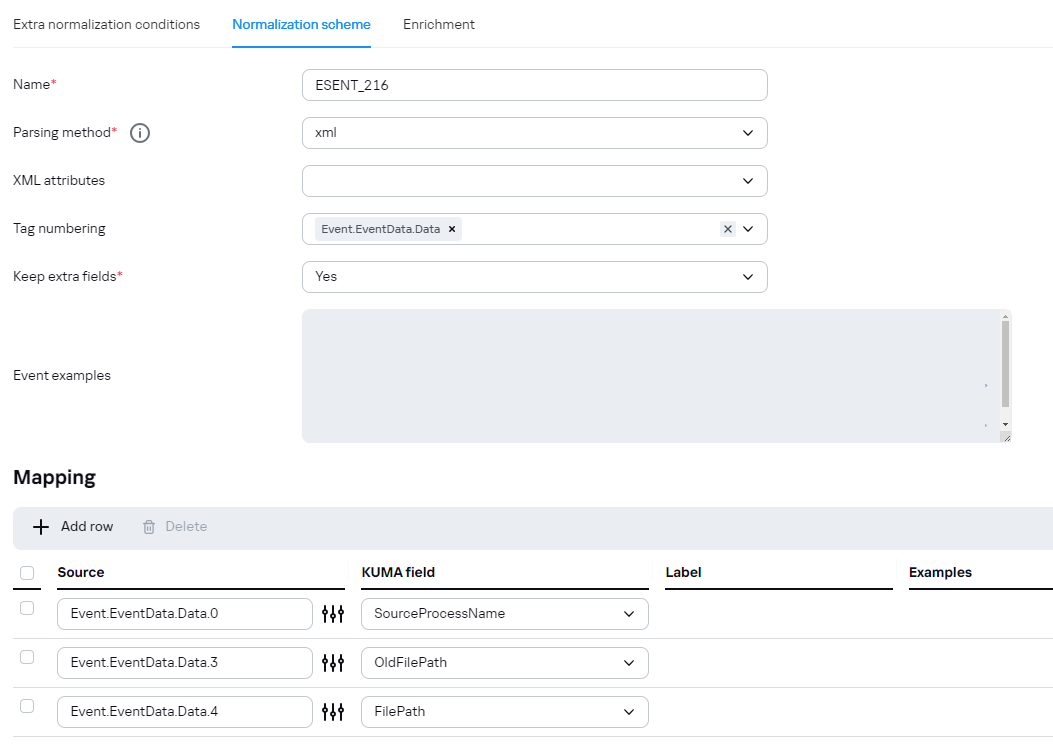
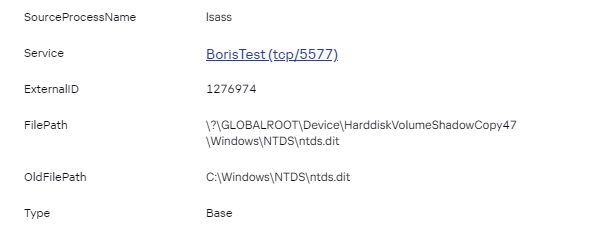
Будет корректно разбираться:
Смена порядка следования экстранормализаторов
Материал был предостален пользователем комьюнити ❤️
По умолчанию в GUI KUMA отсутствует возможность перемещать экстранормализаторы внутри правила нормализации и менять их местами. Однако, в ряде случаев данная операция всё же требуется. Например, когда нужно добавить блок с экстранормализатором выше уже существующих, так как они проверяются последовательно. Через веб-интерфейс это сделать проблематично, т.к. потребуется удаление и пересоздание заново всех блоков экстранормализаторов идущих ниже.
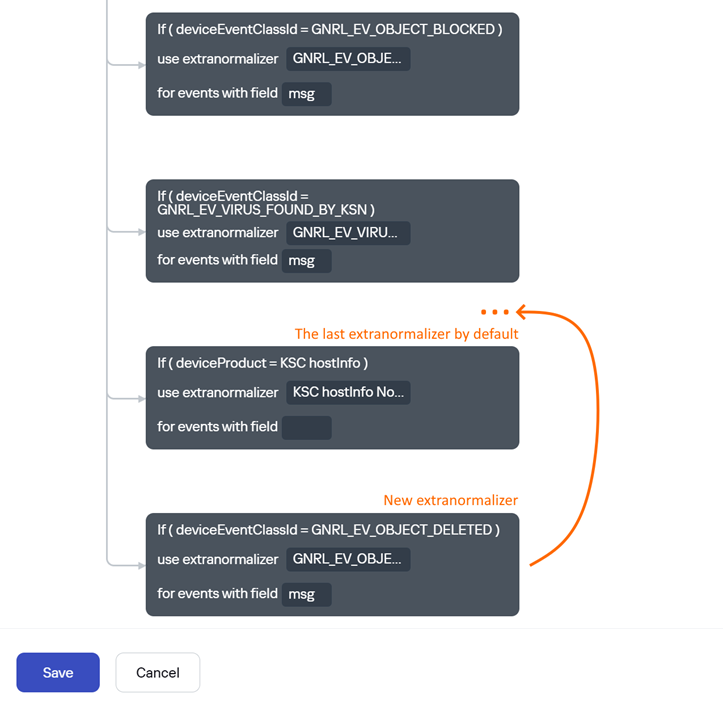
Ниже описан workaround, который позволяет получить нужное правило нормализации в виде JSON файла из MongoDB и отредактировать его, задав нужную последовательность экстранормализаторов.
Необходимые меры предосторожности:
1. Все действия по подготовке нужного правила настоятельно рекомендуется выполнять на тестовом стенде (не на продуктовой инсталляции), так как предполагается прямой доступ и запись данных в MongoDB (основную базу настроек KUMA). Нельзя исключать риск нарушения работы инсталляции KUMA из-за возможных ошибок.
2. Предварительно рекомендуется сделать выгрузку контента и бэкап самой базы: средствами kuma tools (old), по API или через утилиту mongodump.
1. Разместить на стенде KUMA правило нормализации, которое будет подлежать редактированию. Открыть его в браузере и скопировать его UUID из строки URL.
Необходимые утилиты под вашу ОС можно загрузить отсюда: https://www.mongodb.com/try/download/database-tools
2. C помощью встроенной консольной утилиты mongoexport выполнить подключение к базе kuma и экспорт нужного правила нормализации в файл:
/opt/kaspersky/kuma/mongodb/bin/mongoexport --db=kuma --collection=resources --query='{"_id": "your_normalizer_id"}' > normalizer.json