Обработка многострочных событий в KUMA
Введение
В данной статье будет рассмотрен процесс обработки многострочных событий на примере AuditD.
Сразу нужно заметить пару нюансов:
1) Пачка событий = 2 EPS
2) Нет Raw, при необходимости собирать сырые события нужно будет создать дополнительный коллектор, который будет за это отвечать
3) После склейки, все будет записано в поле Extra/Message, из-за чего нужно будет переписать имеющиеся правила корреляции, либо добавить коллектор, который будет склеенное событие мапить на поля KUMA
4) Данный метод применим только к тем событиям, которые можно агрегировать, подробнее по ссылке: https://kb.kuma-community.ru/books/sozdanie-parserov-v-kuma-cookbook/page/princip-raboty-pravila-agregacii-sxematicno
Принцип работы
Ниже представлена схема работы склейки многострочного события:
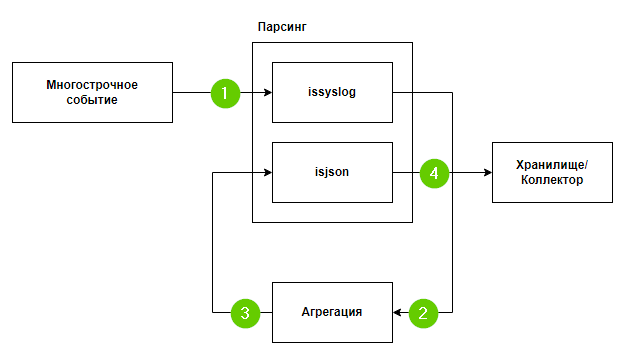
Рассмотрим этот алгоритм:
1) На первом шаге в коллектор поступает событие, где происходит проверка, был ли отправлен syslog или json, в условиях экстранормализации, соответственно, выполняется проверка формата сообщения.
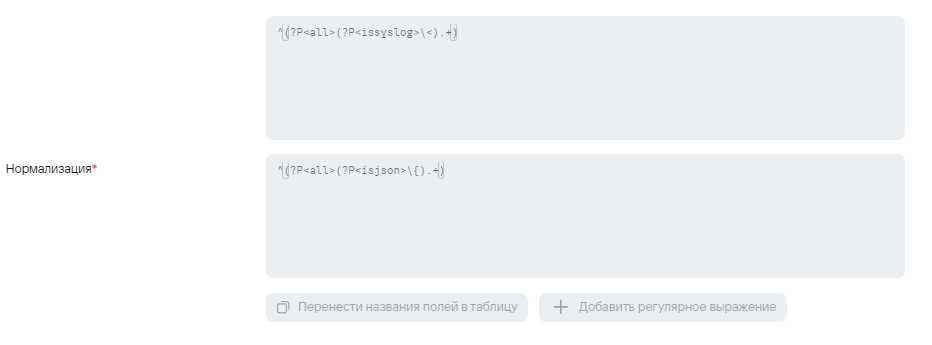
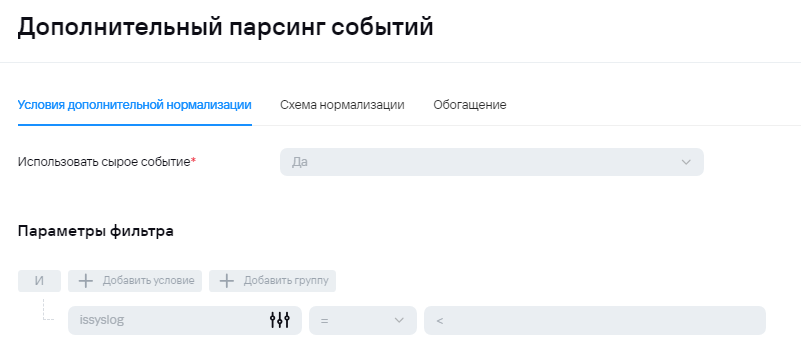
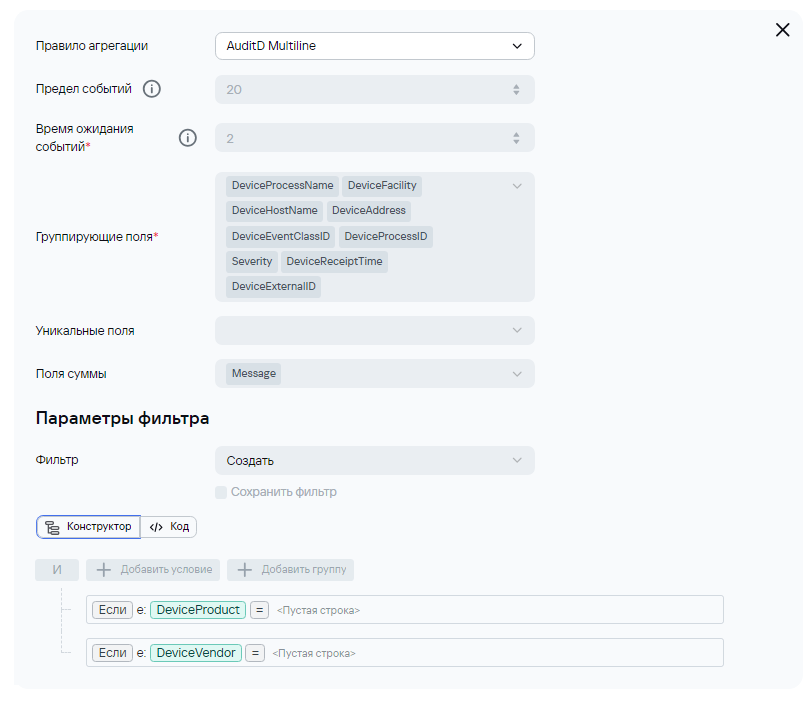
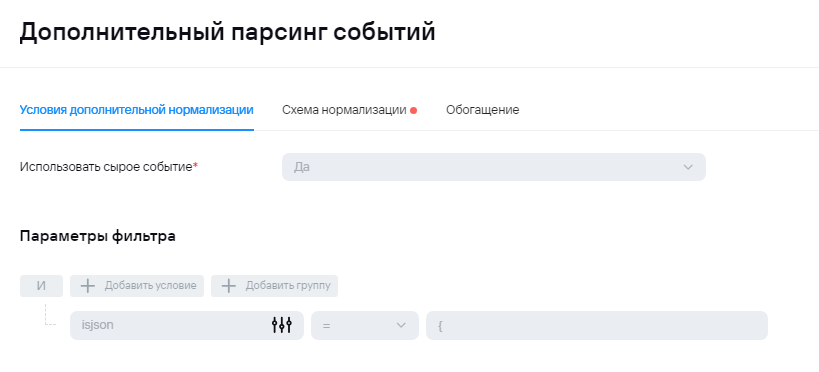 2) В случае отправки syslog'а на этапе нормализации не будет происходит обогащения полями DeviceProduct и DeviceVendor, поэтому их можно будет добавить в условие для агрегации. Ниже приведен пример для агрегации событий AuditD:
2) В случае отправки syslog'а на этапе нормализации не будет происходит обогащения полями DeviceProduct и DeviceVendor, поэтому их можно будет добавить в условие для агрегации. Ниже приведен пример для агрегации событий AuditD:
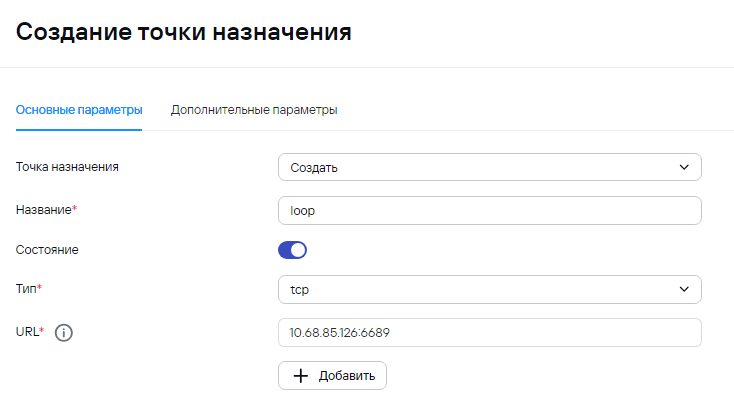
3) После агрегации происходит маршрутизация, где идет проверка типа событий loop - для Type=2 (агрегированные события) и Storage for AuditD для Type=1 (базовые события). Обратите внимание, что при создании точки loop, нужно будет указать выходной формат json:
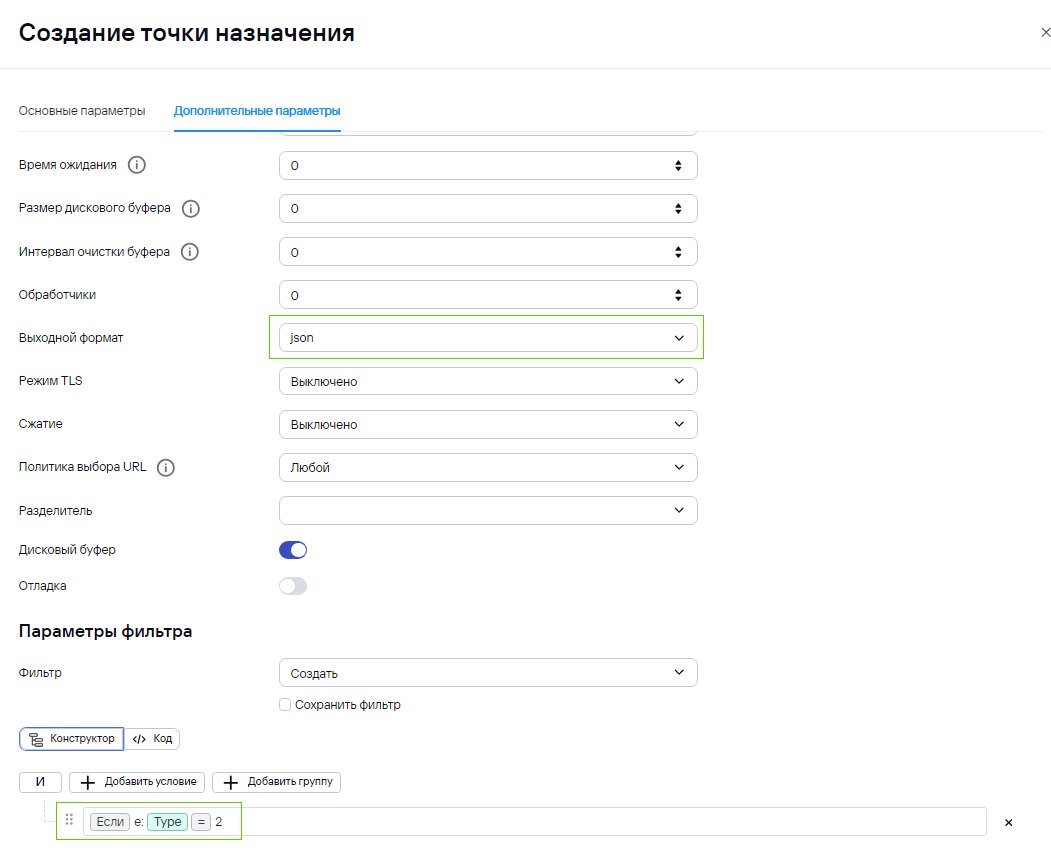
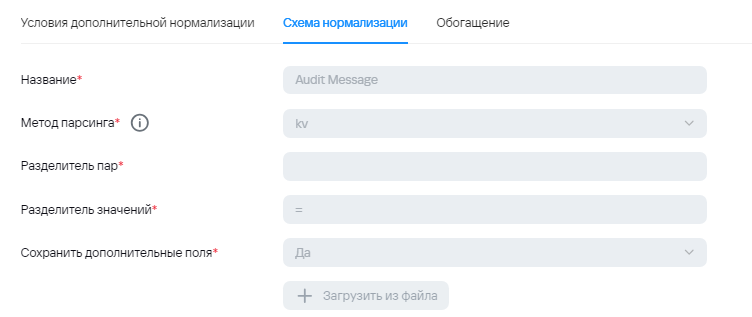
4) После отработки loop, коллектор получает json, где уже происходит обогащение, а также вынос информации из Message в Extra. Это событие уже не будет считаться агрегированным из-за чего будет отправка в другую точку назначения.
Ссылки
Пример парсера (пароль для импорта ресурса q123123Q!): https://box.kaspersky.com/f/b44b00074feb4bf8b268/?dl=1 Принцип работы правила агрегации (схематично): https://kb.kuma-community.ru/books/sozdanie-parserov-v-kuma-cookbook/page/princip-raboty-pravila-agregacii-sxematicno