Правила сбора и анализа данных (Data Mining)
Альтернативная концепция потоковой корреляции событий
В отличие от потоковой корреляции, работающей в режиме реального времени, Data Mining правила позволяют с помощью языка SQL и функций ClickHouse (примеры запросов, почти все возможно использовать) распознавать и анализировать события, сохраненных в хранилище KUMA (можно указать и конкретный спейс хранилища).
Принцип работы
Выполнение SQL-запросов к ClickHouse и приведение результатов к формату нормализованных событий KUMA происходит на уровне Core с помощью новой сущности DataMiningRule и встроенного механизма Scheduler. Полученные результаты преобразуются в события и распространяются по корреляторам через стандартный API, который также используется коллекторами.
Важно, что:
- запрос к ClickHouse выполняется строго один раз за указанный период расписания;
- сформированный результат может быть направлен одному или нескольким корреляторам, а также в другие подсистемы в будущем;
- корреляторы, получающие данные, могут принадлежать различным тенантам, что обеспечивает гибкость и масштабируемость архитектуры.
Таким образом, Data Mining правила открывают возможность выявлять долгие и сложные цепочки активности - те, которые невозможно или крайне трудно обнаружить только средствами потоковой корреляции.
Преимущества и недостатки
| Плюсы | Минусы |
|
Снижение нагрузки на корреляторы — отсутствует необходимость хранить большие объёмы временных данных в оперативной памяти |
Увеличение нагрузки на хранилище данных, для которого постоянные сложные запросы не являются целевой нагрузкой. |
|
Кросстенантное обнаружение — правило может передавать результаты нескольким корреляторам разных тенантов. |
Риск тяжелых запросов — неэффективный SQL может существенно нагрузить кластер. |
|
Гибкость создания правил — возможность строить корреляцию напрямую на основе SQL-запросов. |
Отложенное обнаружение — аналитика работает постфактум, поэтому алерт приходит позже, чем при потоковой корреляции. |
|
Распределённое выполнение запросов — нагрузка обрабатывается кластером хранилища, а не одним сервером корреляции. |
|
|
Поддержка поиска аномалий и долгих сценариев атак — отклонения от нормы, тренды, девиации, редкие последовательности. |
|
|
Устойчивость к задержкам и несинхронности событий — если события приходят с опозданием или в неправильном порядке (например, правила по Golden Ticket), анализ всё равно будет корректным. |
|
|
Сохранность состояния при рестарте — бакеты и промежуточные данные не сбрасываются при перезагрузке коррелятора. |
Кейсы использования правил
Использование Data Mining правил особенно актуально в ситуациях, когда классическая потоковая корреляция либо неэффективна, либо слишком ресурсоёмка. Рассмотрим основные практические сценарии:
- Когда нужно обработать много событий за период
Например, большое число неуспешных логинов за 5 минут или массовое сканирование портов.
Data Mining позволяет считать такие вещи в ClickHouse, не загружая корреляторы. - Когда нужно суммировать или усреднять значения
Можно использовать агрегирующие функции SQL:SUM(),AVG()и т.д.
Пример: средний объём исходящего трафика или количество DNS-запросов.
Алерт срабатывает при превышении порога. - Когда нужен сравнительный анализ
Например, сравнить количество событий за последний час с таким же периодом сутки назад. - Когда нужно работать со “скользящим” окном времени
Анализировать события за период, независимо от того, с какой задержкой они пришли. - Подсчет энтропии
Описание кейсов
Рассмотрим более подробно на парочке примеров:
1. Частые неуспешные попытки входа
Корреляционная логика, при которой требуется длительное накопление событий.
Например: более 10 неуспешных попыток аутентификации под пользователем root.
Берём окно поиска 15 минут и запускаем правило каждые 14 минут.
Так мы анализируем накопившиеся события и получаем результат без необходимости хранить все данные в памяти коррелятора.
2. Подсчёт исходящего сетевого трафика (12 слайд)
Простой пример, где нужно суммировать данные и обнаруживать превышение порога.
- Суммируем исходящий трафик (
SUM(bytes_out)) и группируем по адресу источника. - В поле «Глубина» оставляем пусто — тогда нижняя граница интервала определяется автоматически как конец предыдущего запроса + 1.
- В поле «Частота запуска» ставим минимальное значение — 1 минута.
В результате Scheduler каждую минуту запускает SQL-запрос с небольшим окном данных. Получается скользящее окно, которое постоянно обновляется и позволяет корректно работать даже при задержках в доставке событий и нарушении их порядка. Это как раз тот случай, когда Data Mining правила способны сделать то, с чем потоковая корреляция справиться не может.
Создание и настройка правила
ДляПроцесс работысоздания правила можно разделить на три этапа:
1 Этап. Создание непосредственно самого Data Mining правила
Создать правило можно двумя способами (из SQL-запроса в разделе Поиск по событиям):
Второй способ (создать правило как ресурс):
- В Ресурсах - Правила сбора и анализа данных Создать правило
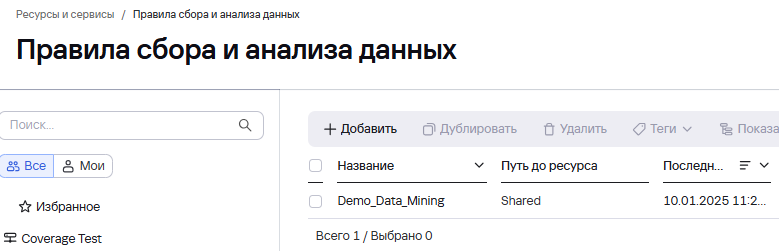
- В правиле указать:
-
- Интервал (частота) выполнения SQL-запроса можно указать в минутах, часах и днях (минимум 1 минута)
- SQL-запрос должен содержать функцию агрегации (примеры) и/или группировку (GROUP BY) данных c обязательным указанием ограничения LIMIT (от 1 до 10 000)
Каждое выполнение такого правила происходит в виде запроса в Хранилище, а это значит неосторожным движением в виде частого или тяжелого правила можно нагрузить базу больше чем хотелось бы
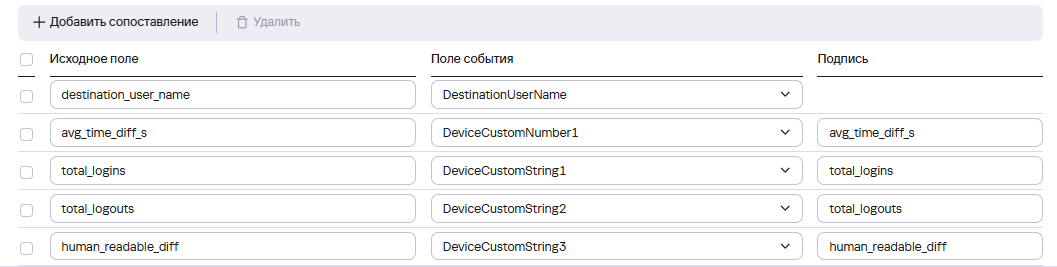
В примере рассматривается запрос на основе событий Windows по пользователям (DestinationUserName) событиям входа (EventID 4624) и выхода (EventID 4634) с расчетом среднего времени сесии пользователя за последние 24 часа.
Посмотреть SQL запрос (пример)
SELECT
login_events.DestinationUserName AS destination_user_name,
round(AVG(logout_events.logout_time - login_events.login_time)/1000) AS avg_time_diff_s,
COUNT(DISTINCT login_events.login_time) AS total_logins,
COUNT(DISTINCT logout_events.logout_time) AS total_logouts,
concat(
toString(floor(avg_time_diff_s / 86400)), ' days, ',
toString(floor((avg_time_diff_s % 86400) / 3600)), ' hours, ',
toString(floor((avg_time_diff_s % 3600) / 60)), ' minutes, ',
toString(avg_time_diff_s % 60), ' seconds'
) AS human_readable_diff
FROM
(SELECT
DestinationUserName,
toUnixTimestamp(EndTime) AS login_time,
FlexString1 AS logon_id
FROM `events`
WHERE DeviceEventClassID = '4624'
AND EndTime >= now() - INTERVAL 24 HOUR
AND DestinationUserName NOT LIKE '%$%') AS login_events
INNER JOIN
(SELECT
DestinationUserName,
toUnixTimestamp(EndTime) AS logout_time,
FlexString1 AS logon_id
FROM `events`
WHERE DeviceEventClassID = '4634'
AND EndTime >= now() - INTERVAL 24 HOUR
AND DestinationUserName NOT LIKE '%$%') AS logout_events
ON login_events.DestinationUserName = logout_events.DestinationUserName
AND logout_events.logon_id = login_events.logon_id
WHERE logout_events.logout_time >= login_events.login_time
GROUP BY login_events.DestinationUserName
ORDER BY avg_time_diff_s DESC
LIMIT 100-
- Добавить маппинг (сопоставление) по полям запроса и модели KUMA
2 этап. Создание планировщика
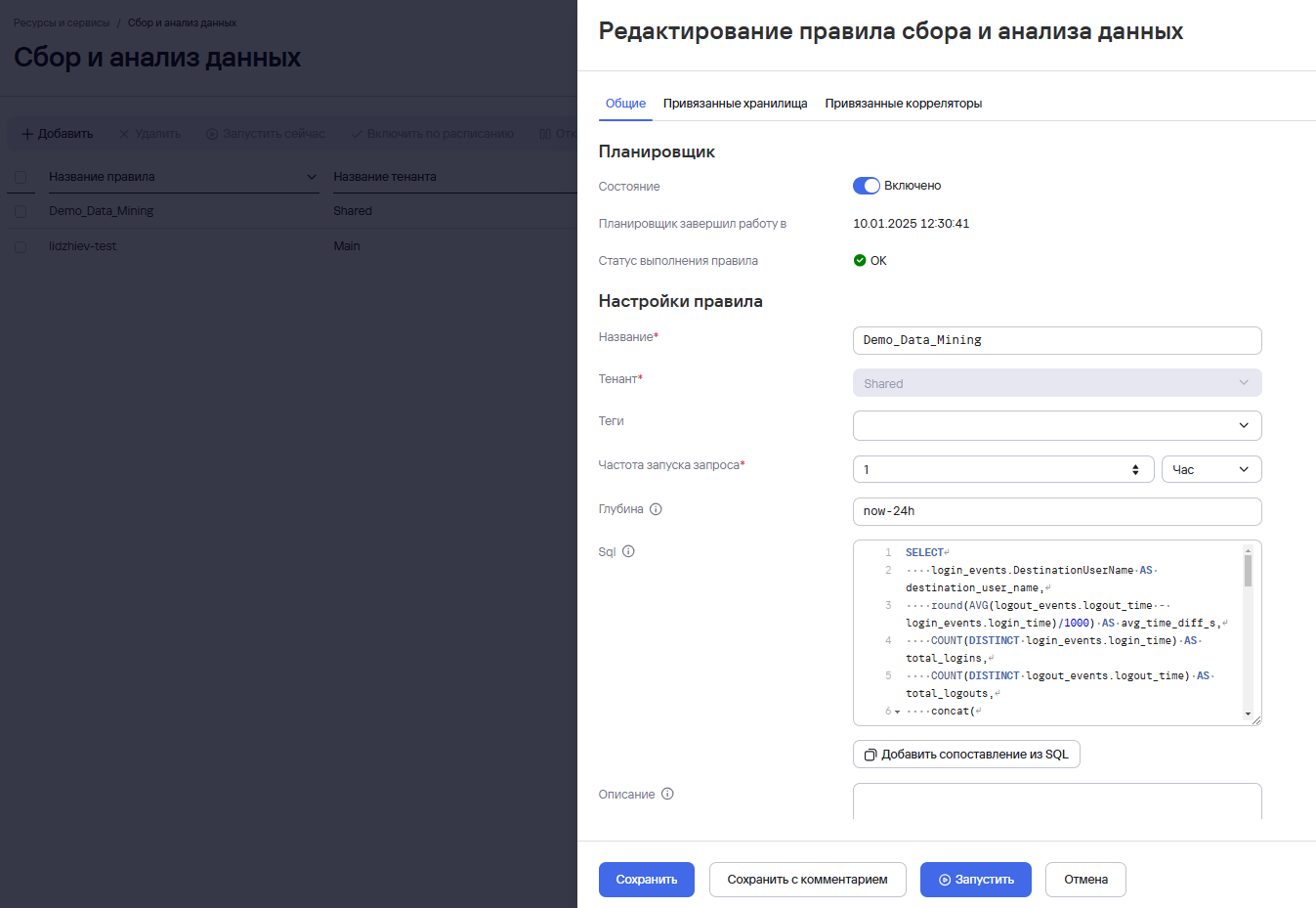
ВПерейти в разделРесурсахРесурсы - Сбор и анализ данных добавить планировщик по ранеесозданноесозданномуправилоправилу- Открыть правило и установить связи:
- Привязать хранилище по которому будет осуществляться поиск на вкладке Привязанные хранилища
- Привязать коррелятор с соответвующим правилом корреляции для сработки на вкладке Привязанные корреляторы
- Для ручного запуска нажмите кнопку Запустить
- По результатам запроса на выходе будут
какие-тосформированыданные,базовые события, которые не будутнигдесохранены.сохраняться,Далеенонеобходимо создать простое правило корреляции, чтобы создать корреляционное событие и алерт нанихданноеможнособытиенастроитьи привязать правилокорреляции.к нужным корреляторам
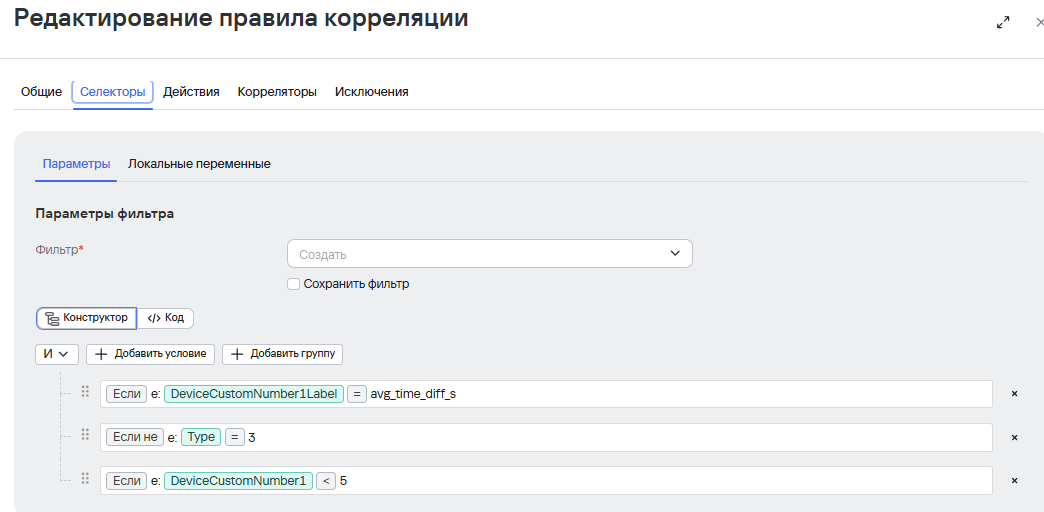
3 этап Создание simple правила на результат
В нашем случае правило ловит события, где время сессии меньше 5 секунд:
Корреляционное событие выглядит следующим образом:
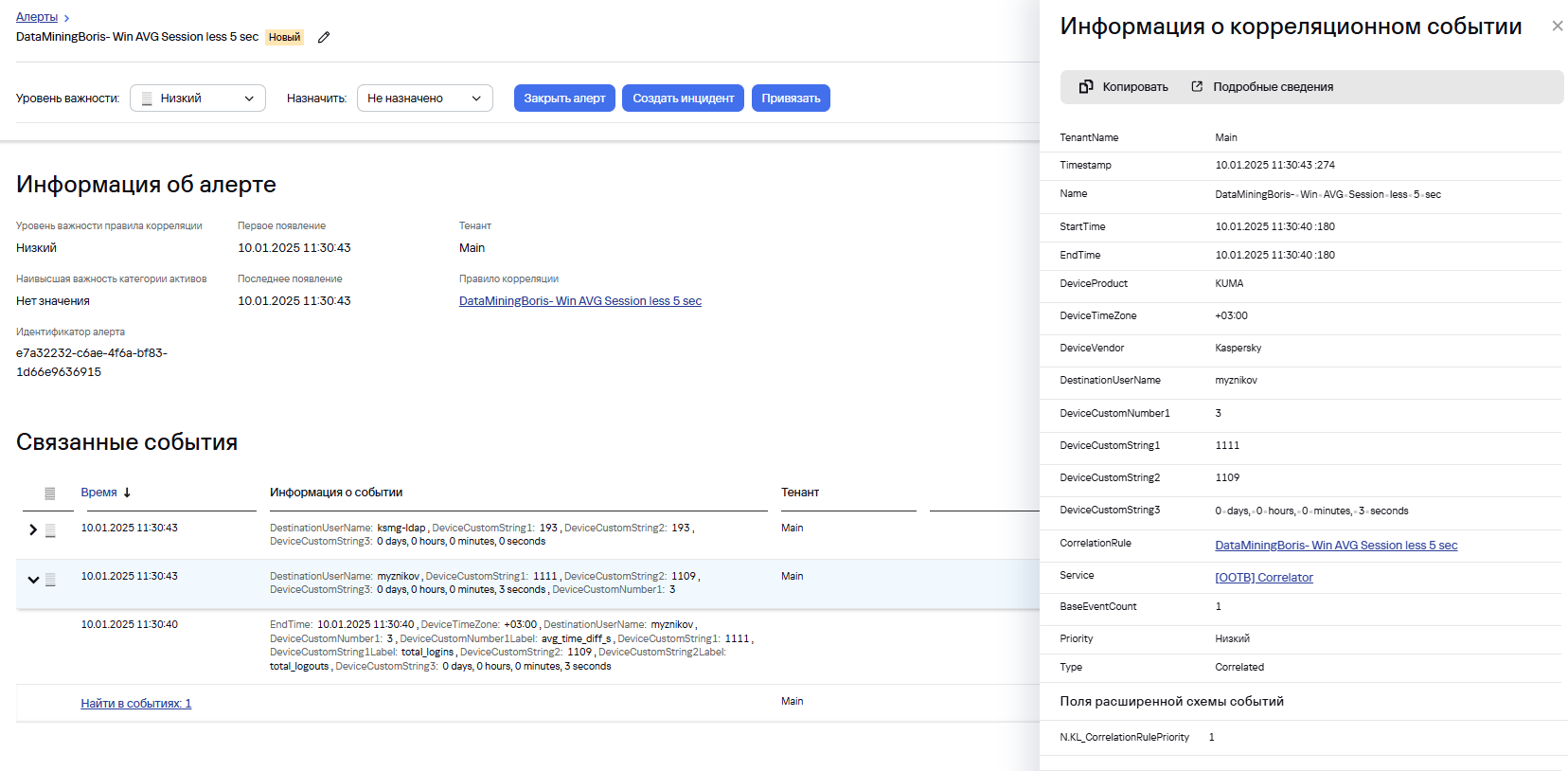
А событие на основе которого произошла сработка:
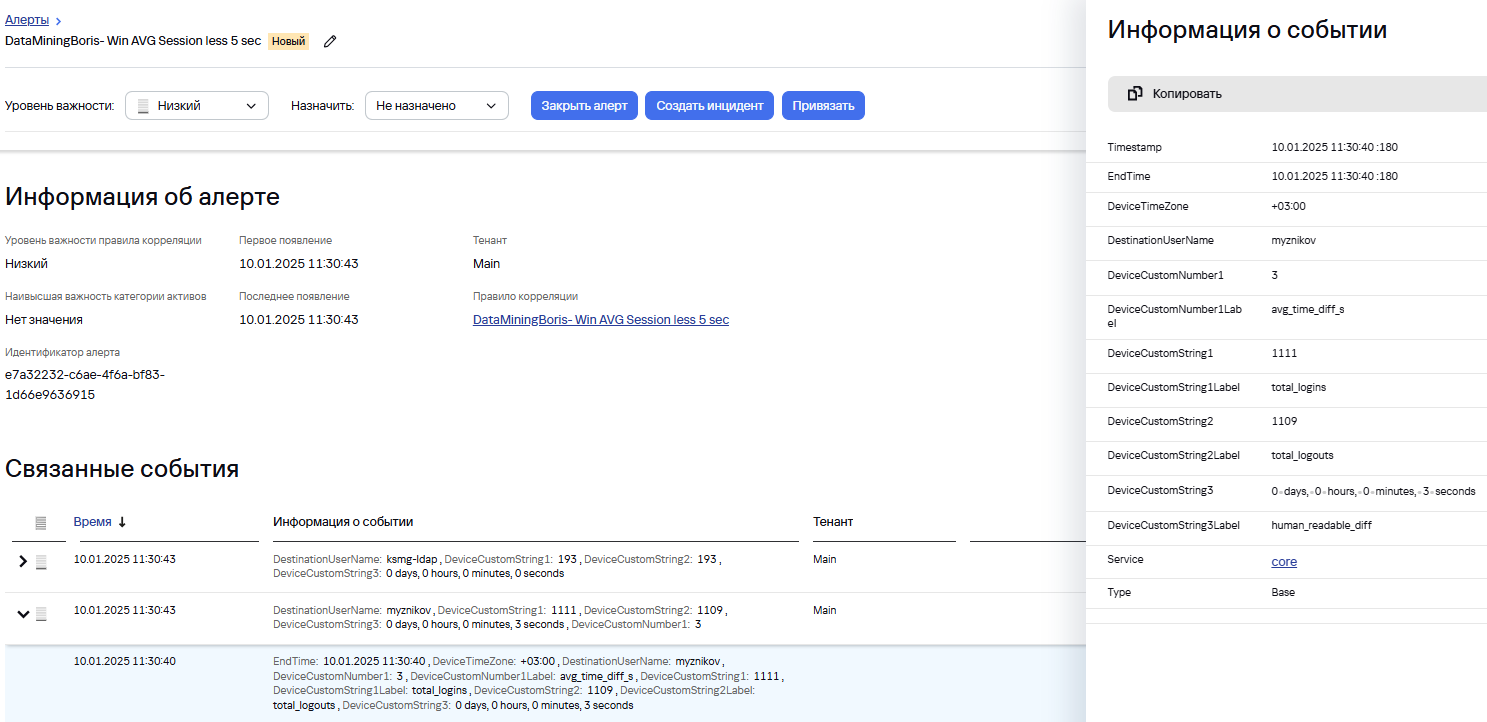
Еще пример:
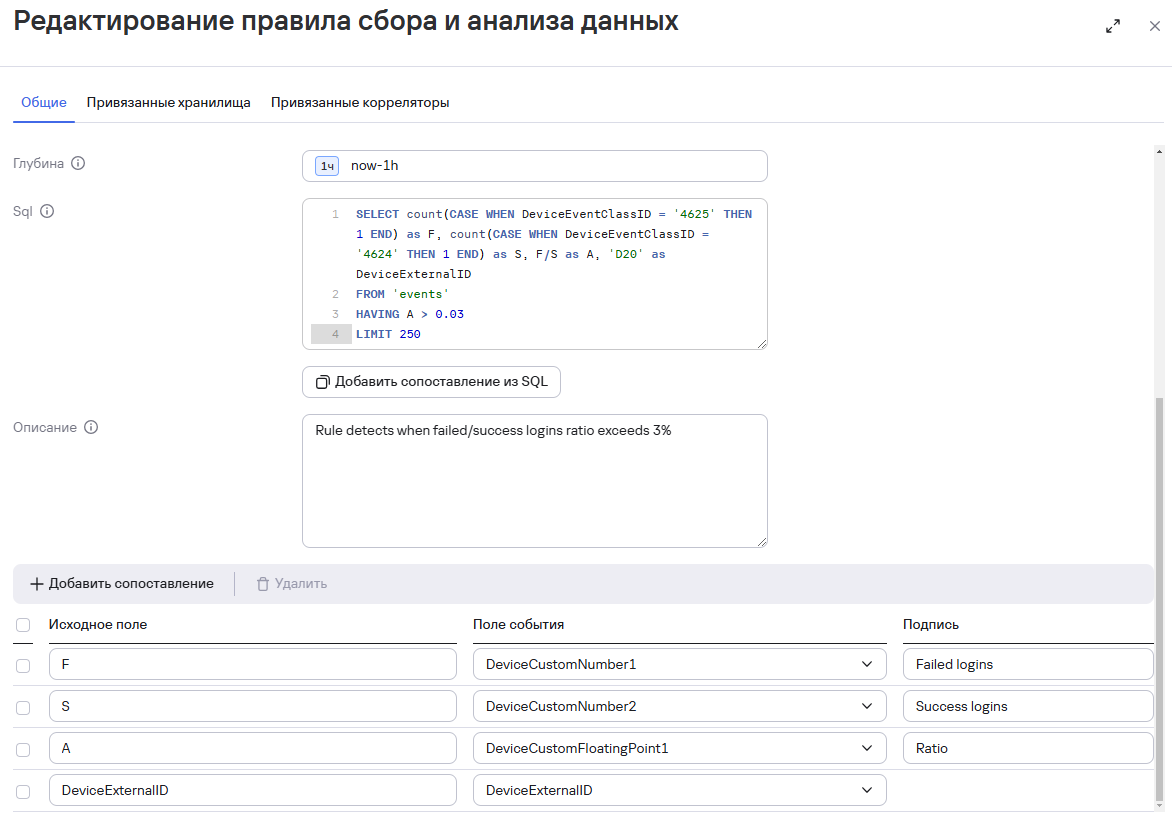
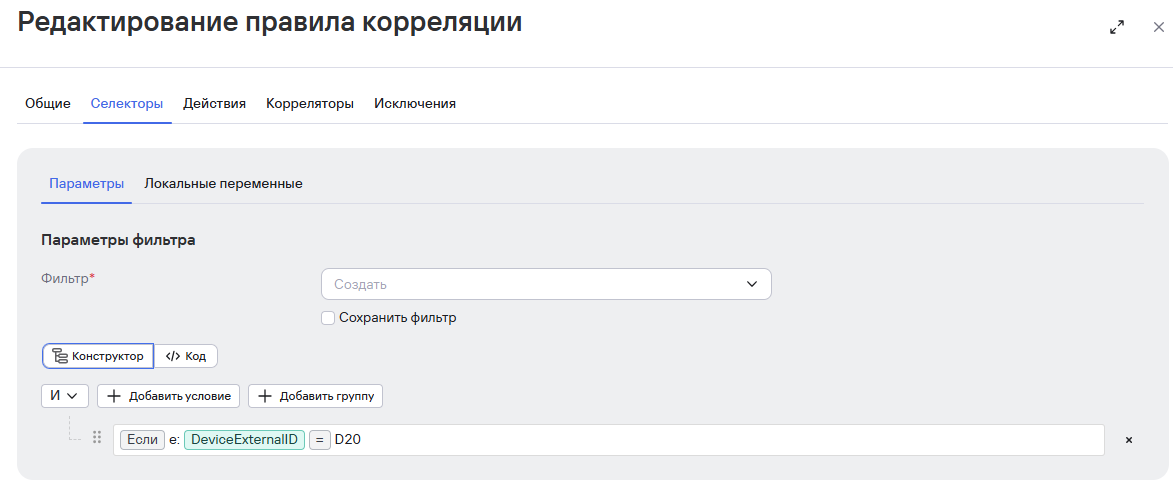
Работу правил можно отслеживать с помощью метрик в разделе KUMA Core:
Примеры готовых правил
Правила:
Пакет ресурсов Data Mining правил: Shared_20251113_231513_DMRules
Пароль к ресурсу: !QAZ2wsx#EDC_!QAZ2wsx#EDC_
Часто используемые функции SQL и лайфхаки
Здесь перечислены самые часто встречающиеся функции, которые используются в запросах:
arrayStringConcat - объединяет элементы массива в строку
arrayCompact - удаляет последовательные дублирующиеся элементы из массива
distinct - уникальные значения
groupUniqArray - собирает значения в массив
arraySort - сортирует массив
arrayMap - применяет выражение к каждому элементу массива и возвращает новый массив с результатами