Первичный Траблшут в KUMA (Troubleshoot)
Проверка статуса основных компонентов
Основные службы KUMA:
systemctl status kuma-collector-ID_СЕРВИСА.service
systemctl status kuma-correlator-ID_СЕРВИСА.service
systemctl status kuma-storage-ID_СЕРВИСА.service
systemctl status kuma-core.service
systemctl status kuma-clickhouse.service
systemctl status kuma-mongodb.service
systemctl status kuma-victoria-metrics.service
systemctl status kuma-grafana.serviceВ версии KUMA 3.2 сервис ядра изменил название на kuma-core-00000000-0000-0000-0000-000000000000.service
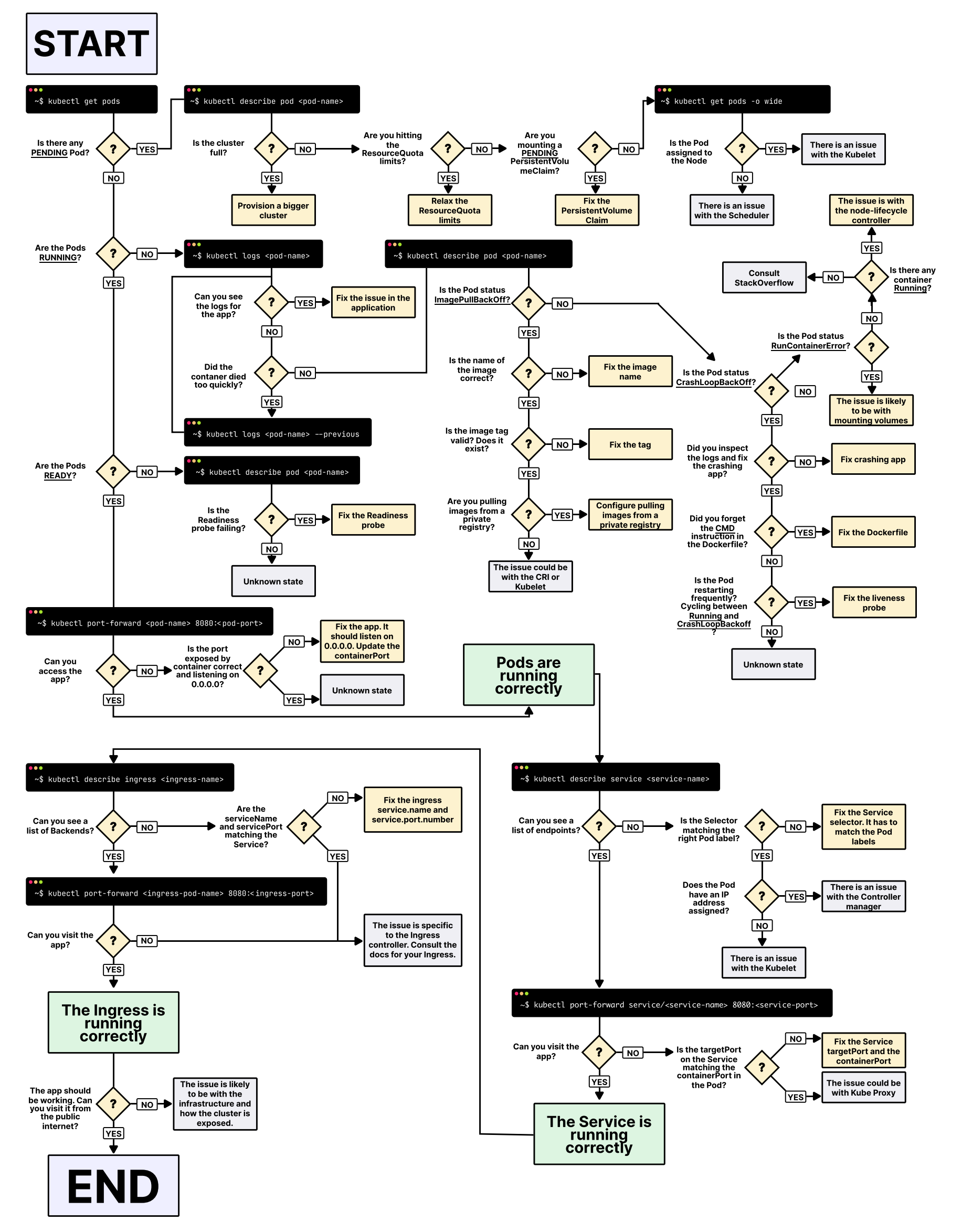
ID_СЕРВИСА можно скопировать в веб-интерфейсе системы, в разделе Активные сервисы, выделив в checkbox нужный сервис, затем нажав кнопку скопировать ID.
Проверка журнала ошибок KUMA
/opt/kaspersky/kuma/<Компонент>/<ID_компонента>/log/<Компонент>
Пример:
/opt/kaspersky/kuma/storage/<ID хранилища>/log/storage
Для неактуальных версий (2.0 и ниже):
journalctl –xe- Журнал ошибок Click-House:
/opt/kaspersky/kuma/clickhouse/logs/clickhouse-server.err.log
Вывод ошибок сервиса в консоль
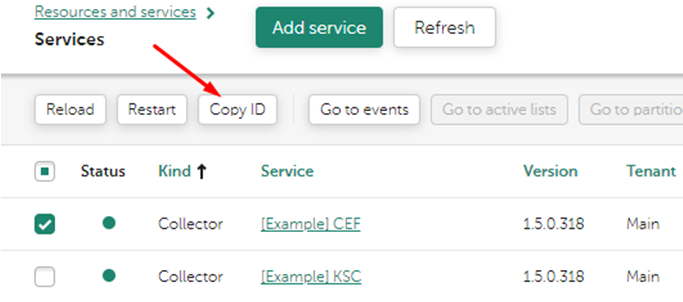
В случае отсутствия информации в журналах целесообразно вывести информацию в консоль. Проверяем статус сервиса и копируем его параметры запуска:
Останавливаем сервис и запускаем следующим образом, пример команды ниже:
sudo -u kuma /opt/kaspersky/kuma/kuma collector --id cef0527c-25ad-4490-a8ce-bf9ab2af71ee --core https://test-kuma.sales.lab:7210 --api.port 7276Пустые метрики
В случае если раздел метрик пустой (отсутствуют значения на дашбордах), то проверьте указан ли IP и hostname сервера KUMA в файле /etc/hosts, если нет то добавьте.
Перезапустите службы:
systemctl restart kuma-victoria-metrics.service
systemctl restart kuma-grafana.serviceЛибо присутствует конфликт со службой Cockpit на Oracle Linux.
Она слушает тот же порт 9090, что и Victoria Metrics. Останови Cockpit и посмотри, поднимутся ли метрики.
Либо проблема из-за наличия прокси между ядром и АРМом, с которого к вебке подключались.
Проверка прослушивания порта, например, 5144
netstat –antplu | grep 5144Работа с портами на МЭ (firewall-cmd)
Проверка открытых портов на МЭ:
firewall-cmd --list-portsДобавление порта 7210 на МЭ:
firewall-cmd --add-port=7210/tcp --permanentПрименение настроек:
firewall-cmd --reloadПроверка получения событий на порту 5144 в ASCII
tcpdump -i any port 5144 -AОтправка тестового события на порт 5144, для проверки работы коллектора
Для TCP:
nc 127.0.0.1 5144 <<< 'CEF:0|TESTVENDOR|TESTPRODUCT|1.1.1.1|TEST_EVENT|This is a test event|Low|message="just a test coming through"'Для UDP:
nc -u 127.0.0.1 5144 <<< 'CEF:0|TESTVENDOR|TESTPRODUCT|1.1.1.1|TEST_EVENT|This is a test event|Low|message="just a test coming through"'В случае наличия в сыром событии двух типов кавычек ' и ", то целесообразно отпралять событие из файла (для этого тестовое событие запишите в файл 1 строку).
cat test.txt | nc -u 127.0.0.1 5144Статус службы красный / Ошибка на компоненте
Переписать / перепроверить учетные данные (если используются) используемые в коннекторе на коллекторе. Проверить владельца папки службы, должно быть kuma:kuma
Посмотреть статус сервиса через консоль ssh. В случае если он запущен остановить:
systemctl stop kuma-collector-ID_СЕРВИСА.serviceзапустить вручную (--api.port выбирайте любой свободный), и посмотреть есть ли ошибки при запуске:
/opt/kaspersky/kuma/kuma collector --id ID_СЕРВИСА --core https://FQDN_KUMA:7210 --api.port 7225Если будут ошибки, они явно отразятся в консоли.
Для сервисов без ID, сначала смотрим параметры запуска службы, например:
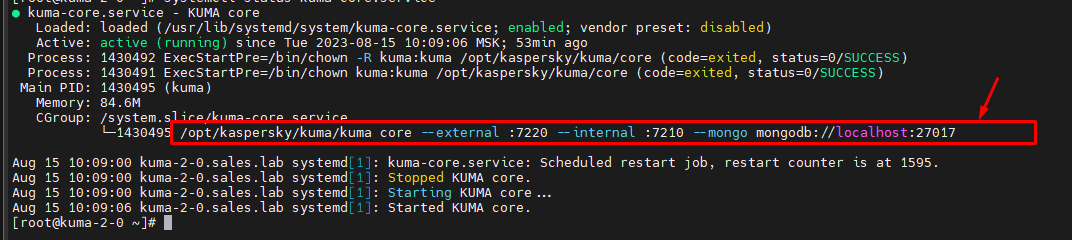
Затем делаем стоп службы и запускаем строку запуска от пользователя KUMA:
sudo -u kuma /opt/kaspersky/kuma/kuma core --external :7220 --internal :7210 --mongo mongodb://localhost:27017Ручная очистка пространства хранилища
Если место на сервере хренения заканчивается, но еще не закончилось.
Выберите в активных сервисах - сервис хранилища (storage) и нажмите на кнопку смотреть разделы. Удаляйте наиболее старые партиции.
Далее (чтобы в будущем не заполнялось):
Закончилось дисковое пространство
Если место уже закончилось.
на серверах хранения остановить сервис kuma-storage очистить файлы журналов rm -rf /opt/kaspersky/kuma/storage//logs/ Запустить сервис systemctl start kuma-storage Залогиниться в web консоль KUMA, удалить лишние партиции (см. предыдущий пункт траблшута)
Далее (чтобы в будущем не заполнялось) в KUMA с версии 3.2:
В Параметры - Мониторинг сервисов - Хранилище, выставьте нужные значения по оповещениям.
Создание сервисов в случае их отсутствия
Если в разделе Ресурсы – Активные сервисы отсутствуют что-либо, то необходимо создать необходимые службы.
Создаем сервис хранилища
Перейдите в Ресурсы – Хранилища затем нажать на кнопку Добавить хранилище придумайте название и затем укажите количество дней хранения событий и событий аудита (от 365 дней срок хранения аудита), затем нажмите Сохранить.
Публикуем созданный сервис Ресурсы – Активные сервисы затем выбрать созданный ранее сервис и нажать на кнопку Создать сервис.
Скопируйте идентификатор сервиса:

Выполните команду в консоли:
/opt/kaspersky/kuma/kuma storage --id <ВАШ_ИДЕНТИФИКАТОР> --core https://<FQDN/ИМЯ_ХОСТА_СЕРВЕРА_ЯДРА>:7210 --api.port 7230 --installВ разделе Ресурсы – Активные сервисы убедитесь, что служба работает более 30 секунд с «зеленым» статусом индикатора:

Далее создадим точку назначения, которая используется в маршрутизации событий, перейдите в Ресурсы – Точки назначения, затем нажмите на кнопку Добавить точку назначения. Придумайте название и затем в поле URL укажите FQDN и порт службы хранилища, например: kuma-1-5-1.sales.lab:7230, затем нажмите Сохранить.
Аналогичные действия понадобятся для установки остальных компонентов, только в интерфейсе будет доступна команда, которую необходимо будет выполнить для установки службы.
Создаем сервис коррелятора
Развернем коррелятор, перейдите в Ресурсы – Корреляторы, нажмите на кнопку Добавить коррелятор и затем пройдите по мастеру настроек, на шаге добавления маршрутизации добавьте точку назначения ранее созданного хранилища:
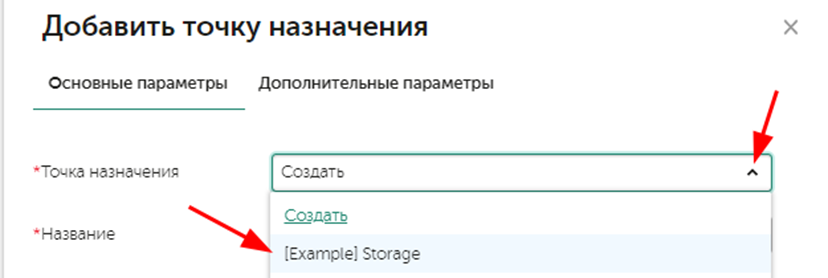
На последнем шаге нажмите кнопку Сохранить и создать сервис, в случае отсутствия ошибок появится командная строка для установки службы, скопируйте ее и выполните по ssh.

Аналогично по мастеру создаются коллекторы для приема или получения событий с источников.
Ошибка скрипта при установке - ipaddr
Если при установке возникает следующая ошибка (пишется в конце исполнения скрипта):
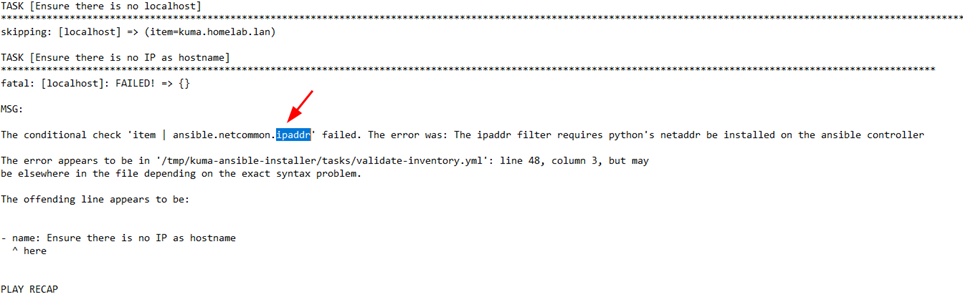
То попробуйте установить нужную библиотеку для python, это было в требованиях https://support.kaspersky.com/KUMA/1.6/ru-RU/231034.htm, в случае отсутствия возможности это сделать то закомментируйте (вставьте # перед строками) следующие строки в файле kuma-ansible-installer/tasks/validate-inventory.yml:
#- name: Ensure there is no IP as hostname
# loop: "{{ groups.all }}"
# when: item | ansible.netcommon.ipaddr
# fail:
# msg: |
# host: {{ item }}
# error: Hostname expectedСлушать на 514 порту (порты < 1024)
По умолчанию это невозможно, так работает Linux. Для обхода этого в описании сервиса:
/usr/lib/systemd/system/kuma-collector-<ID>Добавьте значение ниже тега [Service]
AmbientCapabilities=CAP_NET_BIND_SERVICEЗатем запустите команду ниже для обновления параметров сервиса
systemctl daemon-reloadНе запускается хранилище после перезагрузки в версии от 2.1
Прописать следующую команду в SSH консоли:
sudo -u kuma touch /opt/kaspersky/kuma/clickhouse/data/flags/force_restore_dataОшибка БД ClickHouse Table read only replicas
Ошибка в логах хранилища выглядит так: 
Зайдите в клиент ClickHouse:
/opt/kaspersky/kuma/clickhouse/bin/client.shВыполните команду:
system restart replica on cluster kuma kuma.events_local_v2Для выхода из клиента нажмите Ctrl+D.
Ошибка ZooKeeper - KEEPER_EXCEPTION
Убедиться, что ipv6 включен:
ping ::1Убедиться, что у вас корректное содержимое в /etc/hosts, смотрите этап подготовки п. 8
Очистить Coordination Zookeeper и наработки хранилища (удаляет все события):
systemctl stop kuma-storage-<ID>.service
rm -rf /opt/kaspersky/kuma/storage/<ID>/data/*
rm -rf /opt/kaspersky/kuma/storage/<ID>/tmp/*
rm -rf /opt/kaspersky/kuma/clickhouse/coordination/*
systemctl start kuma-storage-<ID>.serviceИногда требуется (в случае если ошибка остаеся):
sudo -u kuma touch /opt/kaspersky/kuma/clickhouse/data/flags/force_restore_dataЛибо:
/opt/kaspersky/kuma/clickhouse/bin/client.sh
system restore replica on cluster kuma kuma.events_local_v2Признаки нехватки выделенных ресурсов
Описание метрик доступно тут: https://kb.kuma-community.ru/books/kuma-how-to/page/opisanie-metrik-v-kuma
Универсальный показатель Load

Мощностей не хвататет, если на нодах высокий LA (Load average), утилизация CPU доходит до 100%, нагрузка зависит не только от потока (EPS) зависит, но и от профиля использования (количество обогащений, интеграций, используемых правил и т.д.). Средние значения нагрузки (Load averages):
- Если значения равны 0.0, то система в состоянии простоя
- Если среднее значение для 1 минуты выше, чем для 5 или 15, то нагрузка растёт
- Если среднее значение для 1 минуты ниже, чем для 5 или 15, то нагрузка снижается
- Если значения нагрузки выше, чем количество (виртуальных) процессоров, то могут быть проблемы с производительностью (в зависимости от ситуации)
Проблема с производительностью диска на хранилище по метрикам
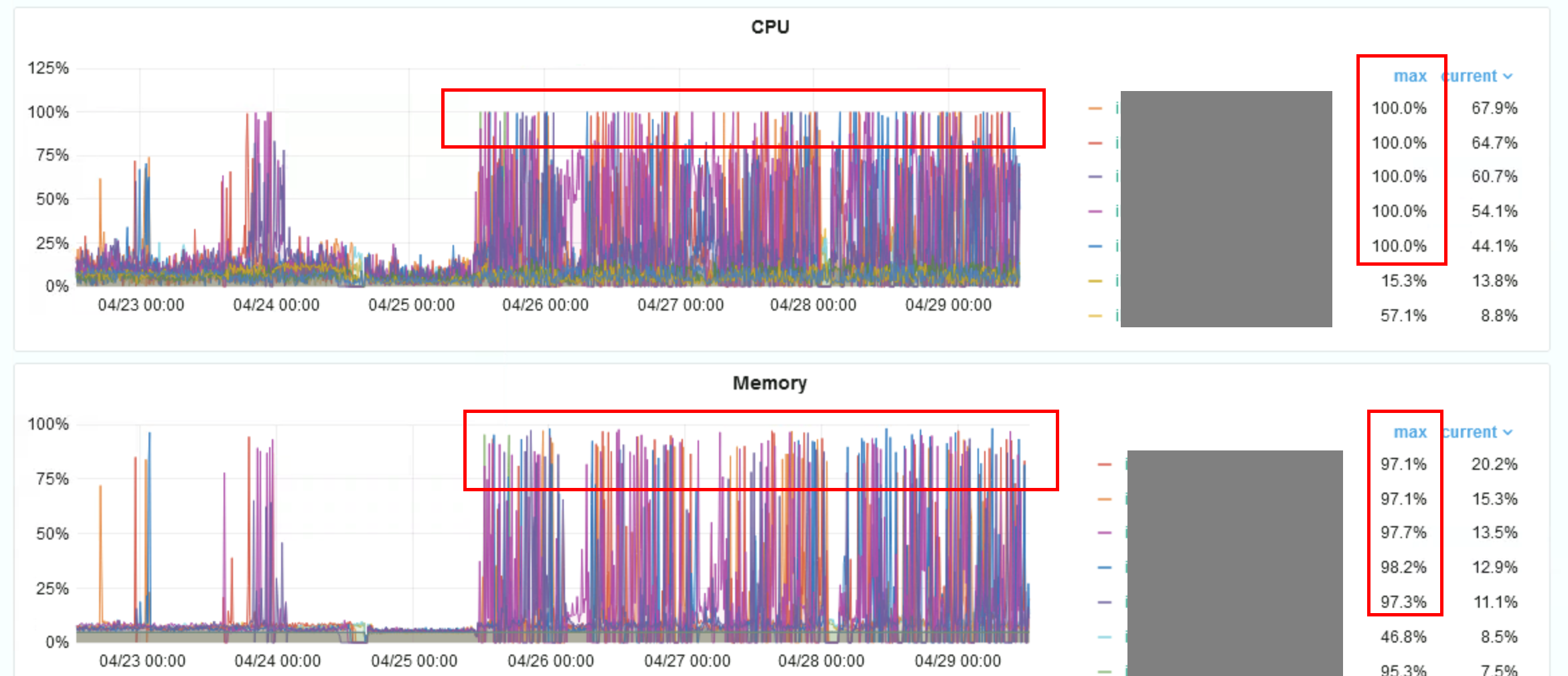
Накапливается буфер в точках назначения, на рисунке ниже хранилище не справляется с потоком, в норме буфер не накапливается при доступности хранилища:

Загрузка CPU и RAM доходит до 100% или близко к этому значению:
В случае использования кластера хранилищ растут очереди распределенных запросов и мерджи:
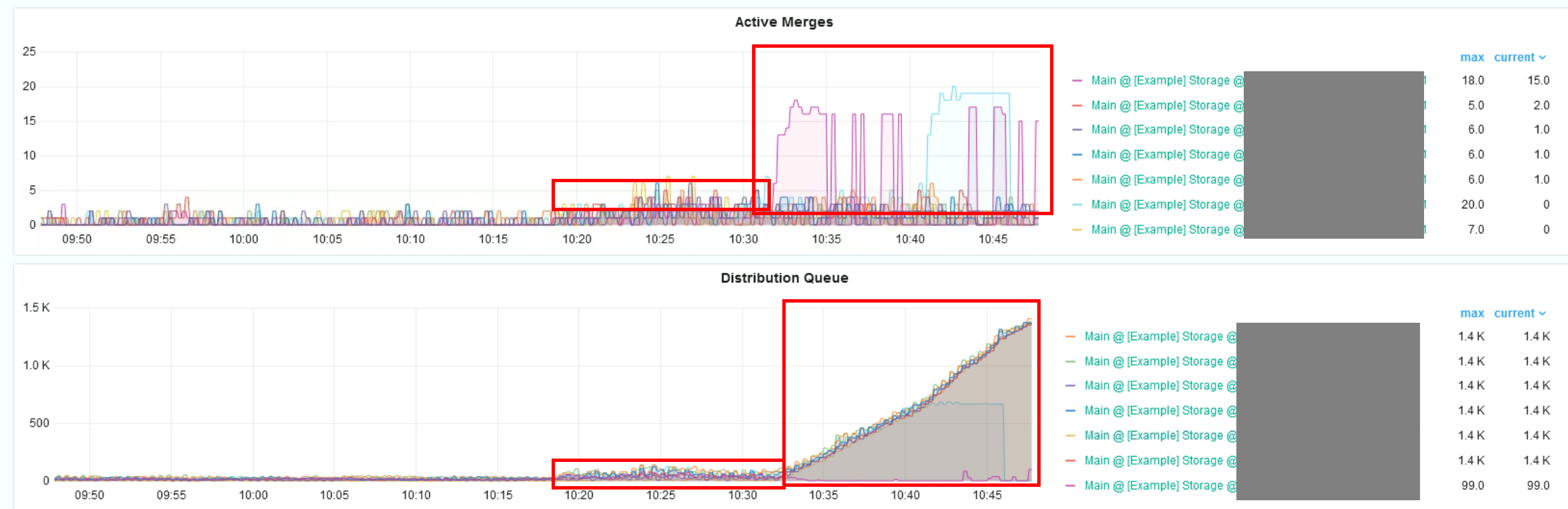
Хранилища выпадают в режим только для чтения:
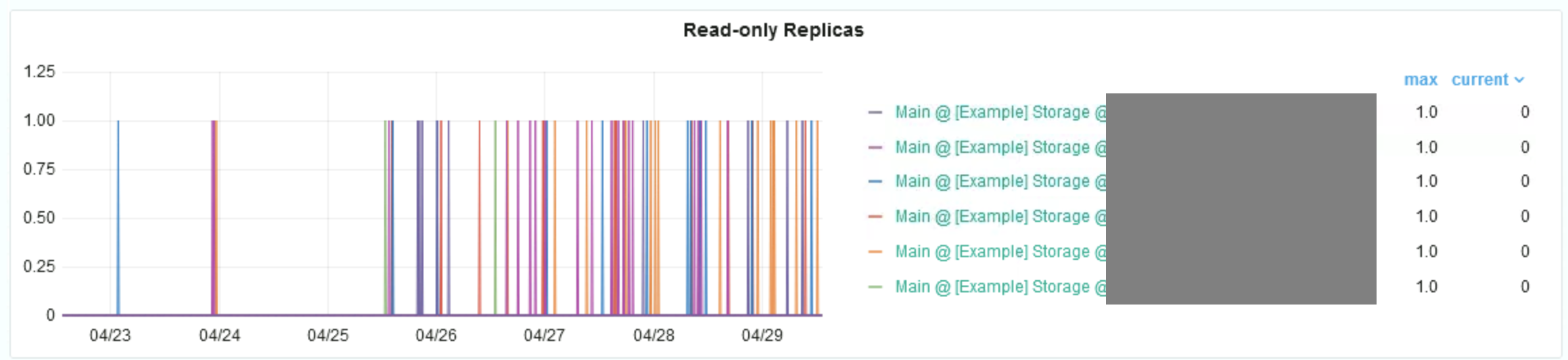
Может быть полезно для хранилища при нагрузках:
- Вынесение и использование отдельных машин с ролью keeper
- Использование более производительного RAID массива
- Использование более производительного дискового носителя
- Работа с объемом буфера для записи в хранилище и временем ожидания
- Использование дополнительного шарда для повышения производительности
Также оценить нагрузку на диск можно командой top в ОС Linux, отслеживая параметр wa (wa: io wait cpu time (or) % CPU time spent in wait on disk) — показывает процент операций, готовых быть выполненных процессором, но находящихся в состоянии ожидания от диска. Допустимое значение < 0.5, в идеале 0.
Требования к хранилищу - тут
Устройство кластера хранилищ - тут
Мониторинг работы ядра в кластере Kubernetes
Посмотреть логи сервисов KUMA:
k0s kubectl logs -f -l app=core --all-containers -n kumaНа хосте контроллера можно посмотреть какие сервисы запущены:
k0s kubectl get pods --all-namespacesПо команде выше, в столбце NAMESPACE нам интересна строка kuma, в этой строке берем значение столбца NAME для просмотра конфигурации используем команду:
k0s kubectl get pod core-deployment-984fd44df-5cfk5 -n kuma -o yaml | lessПолучить список рабочих узлов:
k0s kubectl get nodesПолучить расширенную инфу по рабочему узлу, в т.ч. потребление:
k0s kubectl describe nodes kuma-4.localЗайти в командную строчку пода core-*:
k0s kubectl exec --stdin --tty core-deployment-984fd44df-gqzlx -n kuma -- /bin/shПотребление ресурсов контейнеров внутри пода:
k0s kubectl top pod core-deployment-984fd44df-gqzlx -n kuma --containersДля более удобного управления кластером используйте утилиту k9s - https://github.com/derailed/k9s
После установки ядра в кластере в папке установки прописывается конфиг, например, /root/kuma-ansible-installer/artifacts/k0s-kubeconfig.yml. Его надо “скормить” k9s командой: export KUBECONFIG=/root/kuma-ansible-installer/artifacts/k0s-kubeconfig.yml
Для персистентности переменной KUBECONFIG, необходимо выполнить команду:
echo "KUBECONFIG=/root/kuma-ansible-installer/artifacts/k0s-kubeconfig.yml" >> /etc/environmentПроверить переменные окружения можно командой:
export -pДалее можно запустить утилиту (ее можно загрузить отсюда) просто указав на исполняемый файл ./k9s

Небольшие подсказки по горячим клавишам k9s:
?— Посмотреть хелп по командамShift+F— Настроить порт форвардинг (например, для longhorn-ui):— для ручного ввода команд, ESC для выхода:events— Смотреть события кубера:pods— Смотреть поды кубера (стандартное отображние)
Общий подход по траблшутингу k8s: