В KUMA все группы которые участвуют в маппинге (нормализации) должны быть именованы, пример именования "priority" для группы: `(?P
Если группа не нужна в маппинге, то можно использовать не именованную группу, пример: `(?:\d|\d{2}|1[1-8]\d|19[01])`
Простейшие приемы, практику отработаем на тестовом сообщении: ``` Message from 127.0.0.1 (localhost): KUMA is the best SIEM in 2023! ``` ### Захватить строку KUMA `KUMA` *Ищется полное соответствие строке KUMA.* [](https://kb.kuma-community.ru/uploads/images/gallery/2023-10/oJYimage.png) ### Захватить строку содержащую только буквы `[A-Za-z]+` *Ищем группу (**\[\]**) символов с большими (**A-Z**) и маленькими (**a-z**) буквами от одной и более (**+**).* [](https://kb.kuma-community.ru/uploads/images/gallery/2023-10/sOYimage.png) ### Захватить строку содержащую только числа `\d+` *Ищем по токену **\\d**, что является эквивалентом **\[0-9\]** от одного и более вхождений (**+**).* [](https://kb.kuma-community.ru/uploads/images/gallery/2023-10/bf3image.png) ### Захватить строку внутри круглых скобок `\((\w+)\)` *Ищем по токену **\\w**, что является эквивалентом **\[a-zA-Z0-9\_\]** от одного и более вхождений (**+**), при этом экранируем круглые скобки с помощью обратного слеша **\\** и строку нашу определяем в группу круглыми скобками **()*** [](https://kb.kuma-community.ru/uploads/images/gallery/2023-10/mR9image.png) ### Захватить строку до двоеточия `^[^\:]+` *Ищем с начала строки **^**, далее захватываем в группе все кроме двоеточия (символ двоеточия экранирован) **\[^\\:\]** от одного и более вхождений (**+**)* [](https://kb.kuma-community.ru/uploads/images/gallery/2023-10/p5Ximage.png) ### Захватить строку после двоеточия `[^\:]+$` Такая, подобная предствленной выше, конструкция не подойдет, т.к. она будет очень емокой (633 шага). *Ищем все кроме двоеточия (символ двоеточия экранирован) **\[^\\:\]** от одного и более вхождений (**+**), но до конца строки **$*** [](https://kb.kuma-community.ru/uploads/images/gallery/2023-10/aPvimage.png) В нашем случае лучше использовать следующее *`\:(.*)$` Ищем в строке двоеточие **\\:**, далее захватываем все символы от нуля и более вхождений (**\***), и берем все что нам нужно в группу **()*** [](https://kb.kuma-community.ru/uploads/images/gallery/2023-10/cY9image.png) ### Захватить IP-адрес `\d+\.\d+\.\d+\.\d+` *Ищем числа от одного и более **\\d+**, с точкой и так 4 раза* [](https://kb.kuma-community.ru/uploads/images/gallery/2023-10/untitled.png) ### Захватить слова состоящие из 4 букв `\b[a-zA-Z]{4}\b` *Ищем группу 4 символов из букв и разграничиваем их (boundary) **\\b*** [](https://kb.kuma-community.ru/uploads/images/gallery/2023-10/cCVimage.png) ### Захватить слова состоящие от 3 до 4 букв `\b[a-zA-Z]{3,4}\b` *Ищем группу 4 символов из букв и разграничиваем их (boundary) **\\b*** [](https://kb.kuma-community.ru/uploads/images/gallery/2023-10/cOcimage.png) ### Захватить IPv4 адрес **`\b((2([0-4][0-9]|5[0-5])|[0-1]?[0-9]?[0-9])\.){3}((2([0-4][0-9]|5[0-5])|[0-1]?[0-9]?[0-9]))\b`** [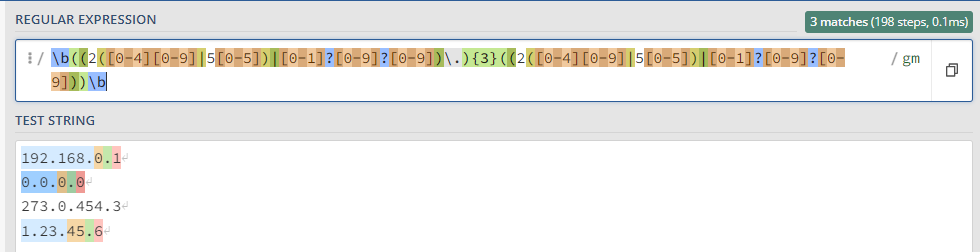](https://kb.kuma-community.ru/uploads/images/gallery/2023-11/Gioimage.png) Более ленивый вариант, но быстрый, без валидации: **`(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})`** [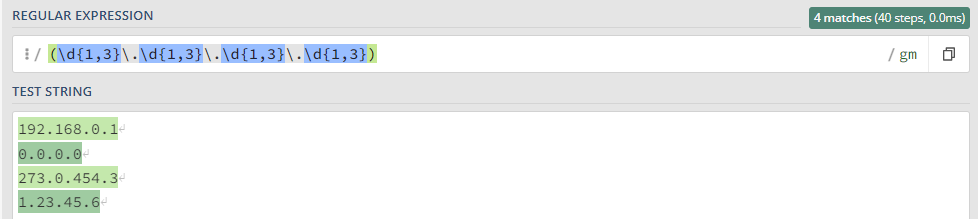](https://kb.kuma-community.ru/uploads/images/gallery/2023-11/XXgimage.png) ### Захватить IPv6 адрес **`(([a-fA-F0-9]{1,4}|):){1,7}([a-fA-F0-9]{1,4}|:) `** [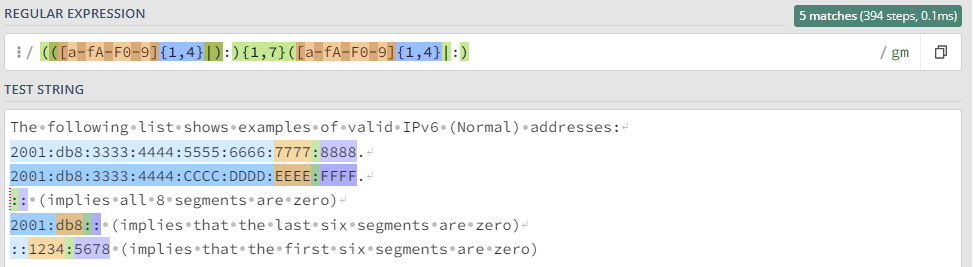](https://kb.kuma-community.ru/uploads/images/gallery/2023-11/huCimage.png) ### Захватить HASH сумму - MD **`^[a-fA-F0-9]{32}$`** - SHA1 **`^[a-fA-F0-9]{40}$`** - SHA256 **`^[a-fA-F0-9]{64}$`** - SHA512 **`^[a-fA-F0-9]{128}$`** ### Захватить URL адрес **`^((https?:\/\/)?([\da-z\.-]+\.[a-z\.]{2,6}|[\d\.]+)([\/:?=&#]{1}[\da-z\.-]+)*\S+)$ `** [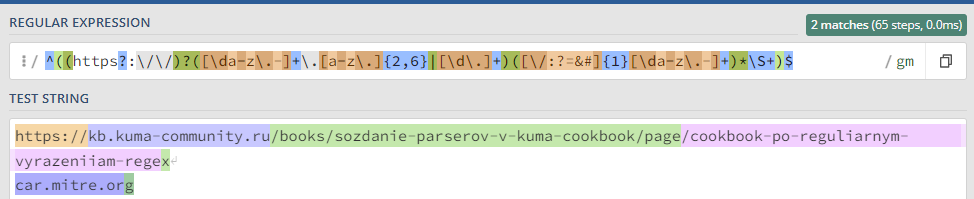](https://kb.kuma-community.ru/uploads/images/gallery/2023-11/p1Timage.png) ### Захватить EMAIL адрес Определяет почти все типы валидных адресов **`\b[\w\.\-\+\!\/\"\%]+@[\w\.-]+(\.\w{2,4})?\b`** [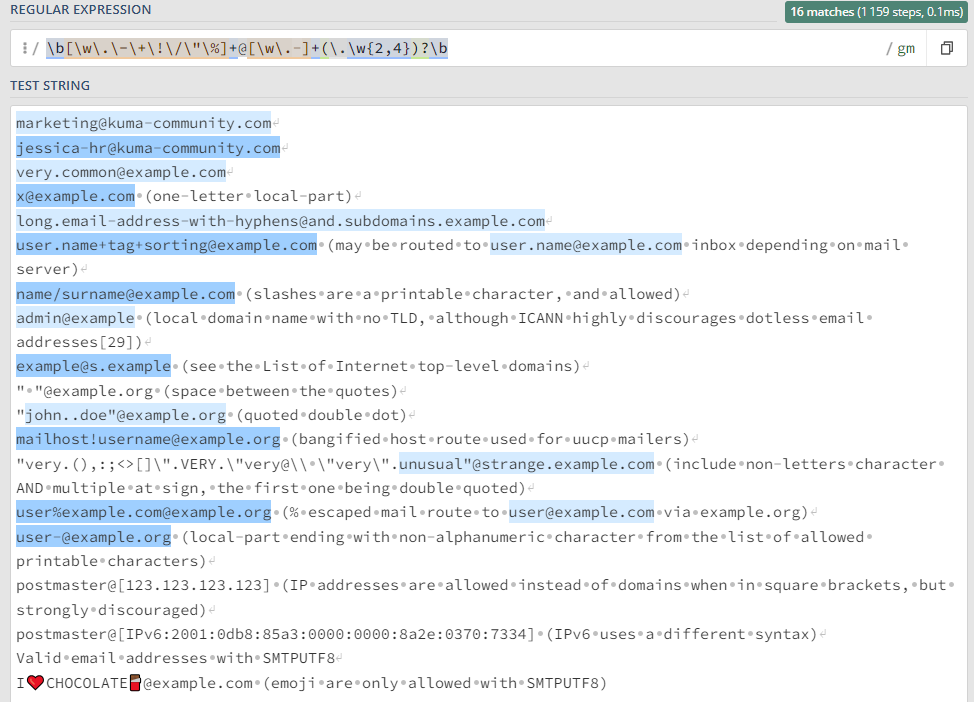](https://kb.kuma-community.ru/uploads/images/gallery/2023-11/uDRimage.png) ### Захватить CSV структуру Создаются группы по значениям из CSV **`(?:\s*(?:\"([^\"]*)\"|([^,]+))\s*,?)+?`** [](https://kb.kuma-community.ru/uploads/images/gallery/2023-11/Byyimage.png) ### Захватить Syslog структуру Разбираются сообщения по rfc [https://datatracker.ietf.org/doc/html/rfc5424](https://datatracker.ietf.org/doc/html/rfc5424) и [https://datatracker.ietf.org/doc/html/rfc3164](https://datatracker.ietf.org/doc/html/rfc3164) **`(?PАктуально для KUMA 3.0+
В KUMA 3.0.2 появилась возможность создания кастомных полей типа "массив" (SA, NA, FA), доступные для методов парсинг JSON и KV. Чтобы записать массив в дополнительное поле, достаточно его указать в маппинге: 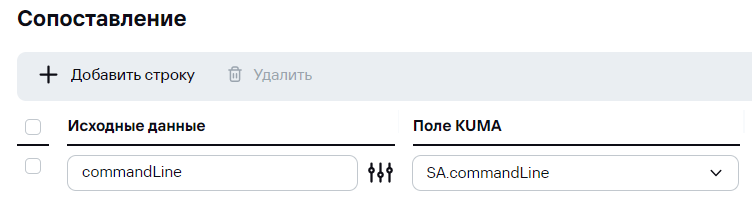 В событии это будет выглядеть следующим образом: 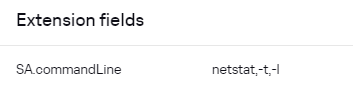 Если с массивом в таком случае работать не удобно и нужно все элементы из массива "склеить" через делиметр и записать в отдельное поле, можно воспользоваться обогащением. Для этого сначала массив мапится на строковое поле: 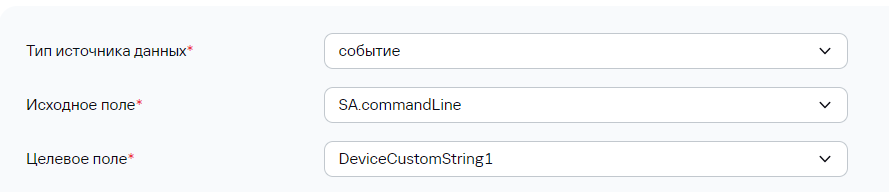 В таком случае в событии данное поле будет представлять собой массив переведенный в строку:  Чтобы привести ее в более "приятный" вид можно выполнить следующие преобразования: 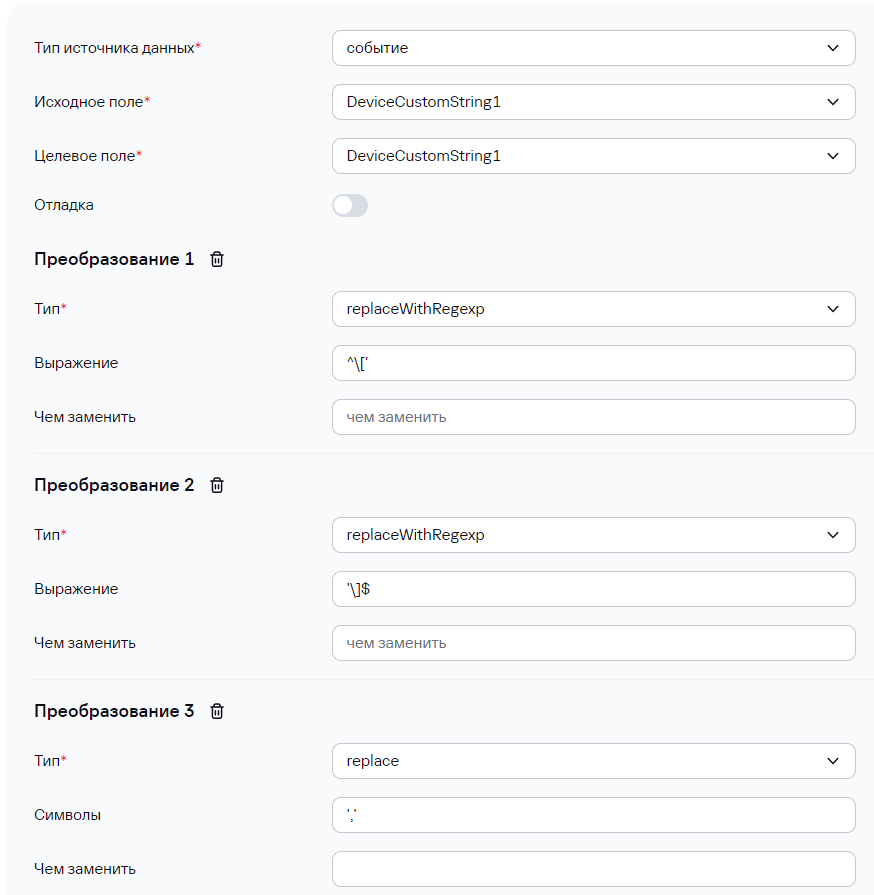 После этого в DeviceCustomString1 будут записаны все элементы массива через выбранный в последнем (3) преобразовании делиметр (в данном примере это "пробел"):  --- ### Передача сырого события в экстранормализатор, для доступа к элементам массиваАктуально для KUMA 3.0+
Для передачи «сырого» события в экстра-нормализатор необходимо: - открыть нормализатор событий; - перейти в меню «Условия дополнительной нормализации»; - активировать параметр «Использовать сырое событие».По умолчанию параметр «Использовать сырое событие» не активен.
[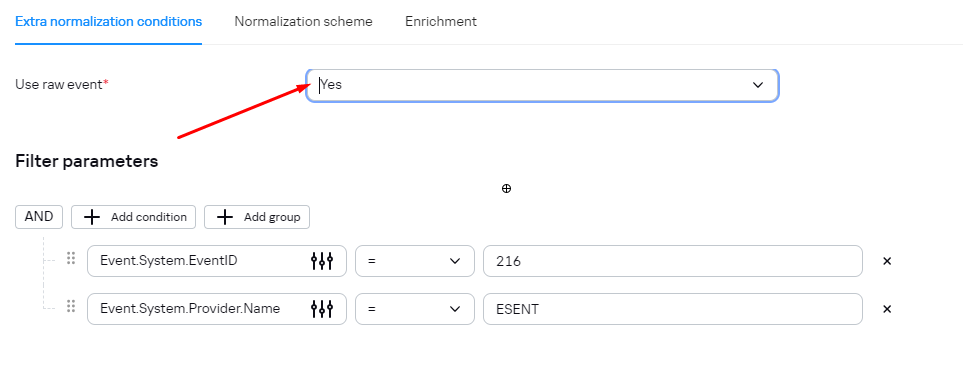](https://kb.kuma-community.ru/uploads/images/gallery/2024-03/lU1image.png) Рекомендуется активировать параметр «Использовать сырое событие» в нормализаторах типа **«xml», «json»**. Для передачи «сырого» события в экстра-нормализатор второго, третьего и более глубоких уровней вложенности необходимо последовательно включить параметра «Использовать сырое событие» в каждом экстра-нормализаторе по пути следования события в целевой экстра-нормализатор и непосредственно в целевом экстра-нормализаторе. В качестве примера работы данной функции вы можете обратиться к нормализатору Microsoft Products для KUMA 3.0.1: параметр «Использовать сырое событие» включен последовательно в экстра-нормализаторах «AD FS» и «424». В качестве примера, событие: *<Event xmlns='http://schemas.microsoft.com/win/2004/08/events/event'><System><Provider Name='ESENT'/><EventID Qualifiers='0'>216</EventID><Level>4</Level><Task>3</Task><Keywords>0x80000000000000</Keywords><TimeCreated SystemTime='2024-01-20T20:06:07.144730300Z'/><EventRecordID>870234</EventRecordID><Channel>Application</Channel><Computer>COMPANY.COM</Computer><Security/></System><EventData><Data>lsass</Data><Data>724,R,98</Data><Data></Data><Data>C:\\Windows\\NTDS\\ntds.dit</Data><Data>\\\\?\\GLOBALROOT\\Device\\HarddiskVolumeShadowCopy50\\Windows\\NTDS\\ntds.dit</Data></EventData></Event>* При парсинге ID события 216: [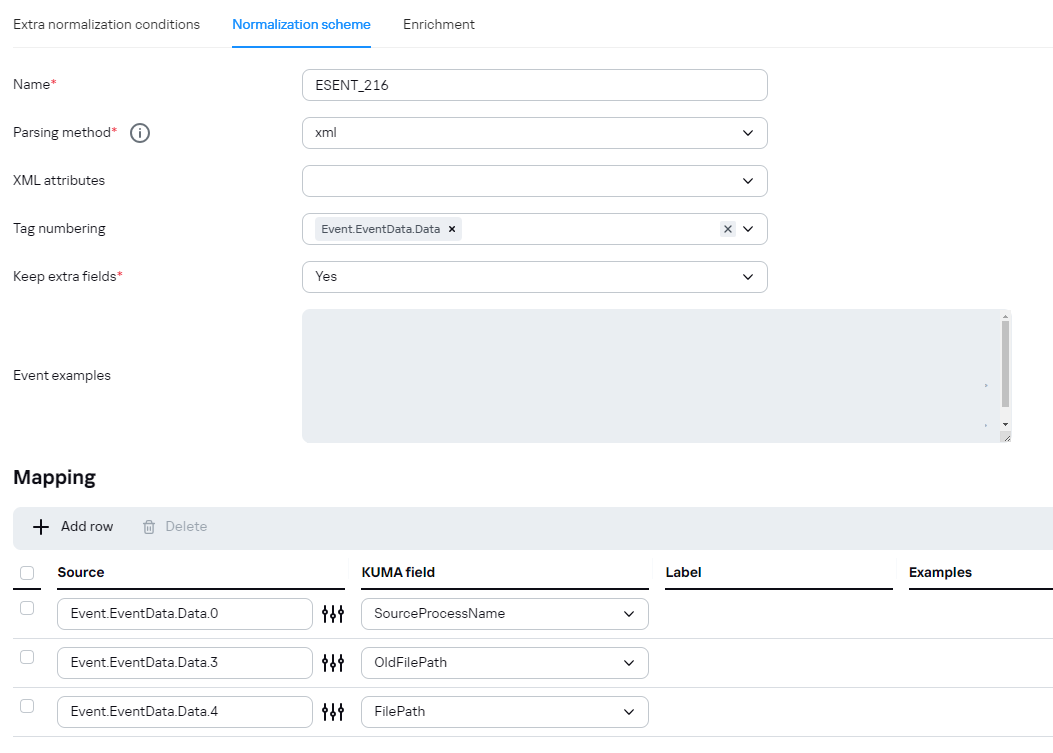](https://kb.kuma-community.ru/uploads/images/gallery/2024-03/6ssimage.png) Будет корректно разбираться: [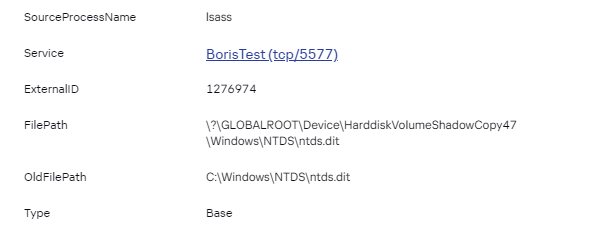](https://kb.kuma-community.ru/uploads/images/gallery/2024-03/Wizimage.png) --- ### Смена порядка следования экстранормализаторовМатериал был предостален пользователем комьюнити ❤️
По умолчанию в GUI KUMA отсутствует возможность перемещать экстранормализаторы внутри правила нормализации и менять их местами. Однако, в ряде случаев данная операция всё же требуется. Например, когда нужно добавить блок с экстранормализатором выше уже существующих, так как они проверяются последовательно. Через веб-интерфейс это сделать проблематично, т.к. потребуется удаление и пересоздание заново всех блоков экстранормализаторов идущих ниже. 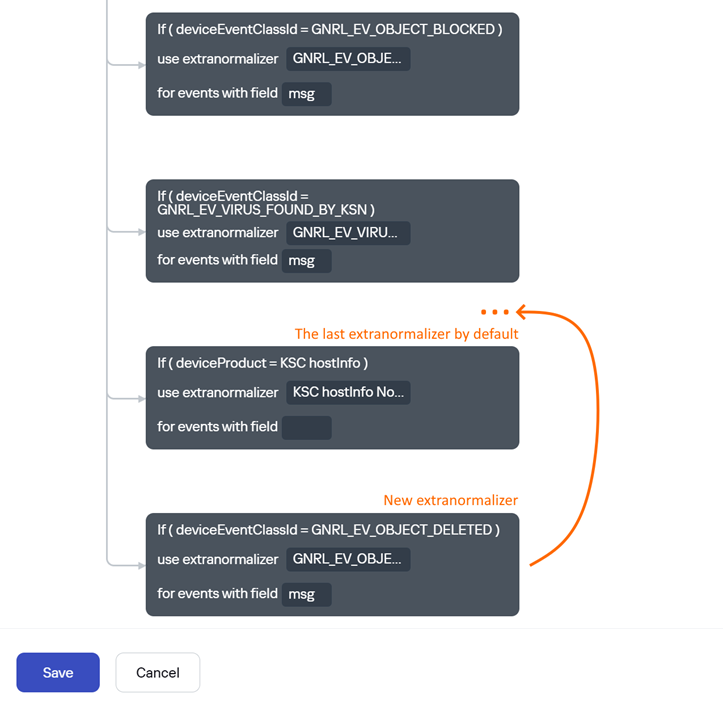 Ниже описан workaround, который позволяет получить нужное правило нормализации в виде JSON файла из MongoDB и отредактировать его, задав нужную последовательность экстранормализаторов.**Необходимые меры предосторожности**: 1. Все действия по подготовке нужного правила настоятельно рекомендуется выполнять на тестовом стенде (не на продуктовой инсталляции), так как предполагается прямой доступ и запись данных в MongoDB (основную базу настроек KUMA). Нельзя исключать риск нарушения работы инсталляции KUMA из-за возможных ошибок. 2. Предварительно рекомендуется сделать выгрузку контента и бэкап самой базы: средствами kuma tools (old), по API или через утилиту mongodump.
1\. Разместить на стенде KUMA правило нормализации, которое будет подлежать редактированию. Открыть его в браузере и скопировать его UUID из строки URL. 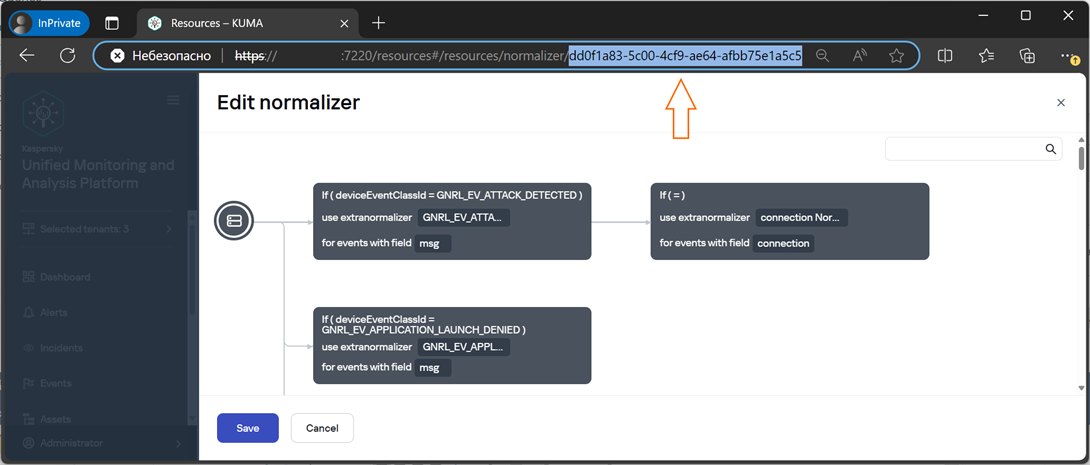Необходимые утилиты под вашу ОС можно загрузить отсюда: [https://www.mongodb.com/try/download/database-tools](https://www.mongodb.com/try/download/database-tools) Документация по утилитам: [https://www.mongodb.com/docs/v4.2/reference/program/](https://www.mongodb.com/docs/v4.2/reference/program/)
2\. C помощью встроенной консольной утилиты mongoexport выполнить подключение к базе kuma и экспорт нужного правила нормализации в файл: ```bash /opt/kaspersky/kuma/mongodb/bin/mongoexport --db=kuma --collection=resources --query='{"_id": "your_normalizer_id"}' > normalizer.json ``` Пример успешного экспорта:  3\. Открыть полученный JSON файл в редакторе, поддерживающим форматирование JSON и работу с объектами (например, Notepad++ c плагином JSTool). ― Сразу поменять uuid в полях "\_id", "exportID", "id" на новый. Он должен быть уникальным в рамках всех остальных ресурсов KUMA для успешного импорта правила обратно. Сгенерировать UUID: cat /proc/sys/kernel/random/uuid ― Сразу поменять значение поля "name", задав новое название правила или его версию. ― Найти в структуре файла блок "extra", содержащий экстранормализаторы. Развернуть его и выполнить поиск нужного блока экстранормализации который требуется переместить. 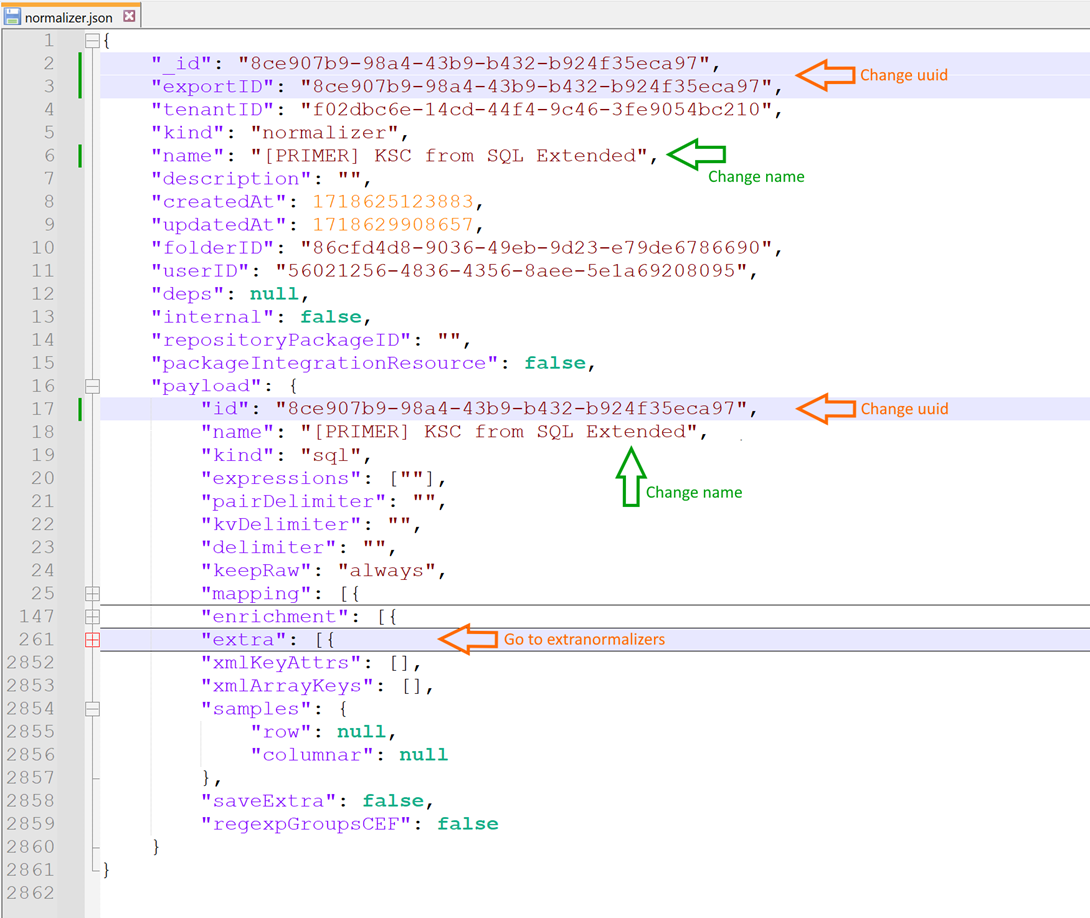 4\. В блоке "extra" найти по нужный экстранормализатор, выделить и скопировать его код целиком, ориентируясь на открывающую скобку перед полем "normalizer" и соответствующую закрывающую скобку.  5\. Вставить скопированный код в нужное место в блоке "extra". Например, в его начале или между требуемых экстранормализаторов (зависит от нужного вам порядка их следования). Проверить, что все скобки { } на месте. 6\. Сохранить получившийся JSON файл, перенести его обратно на сервер с KUMA Core и выполнить его импорт в MongoDB: ```bash /opt/kaspersky/kuma/mongodb/bin/mongoimport --db kuma --collection resources --file new_normalizer.json ``` Пример успешного импорта:  7\. Зайти в веб-интерфейс KUMA и проверить наличие отредактированного нормализатора (в том же тенанте и папке, т.к. они не менялись)  Результат: изменён порядок следования экстранормализаторов без их удаления и пересоздания вручную через веб-интерфейс 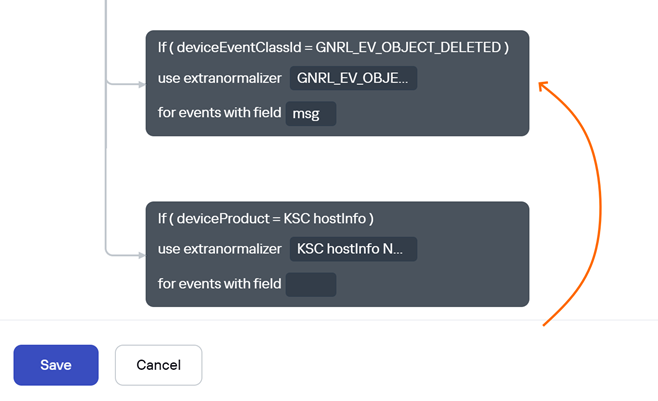 #### Альтернативный вариант с VS CodeПотребуется приложение: [https://code.visualstudio.com/](https://code.visualstudio.com/) и плагин для работы с MongoDB: [https://marketplace.visualstudio.com/items?itemName=mongodb.mongodb-vscode](https://marketplace.visualstudio.com/items?itemName=mongodb.mongodb-vscode)
Также можно использовать клиент MongoDB Compass для подключения к MongoDB: [https://www.mongodb.com/products/tools/compass](https://www.mongodb.com/products/tools/compass)
Рекомендуется работать с копией / дубликатом ресурса, чтобы предотвратить возможные проблемы
1\. Подключение к монго через SSH: 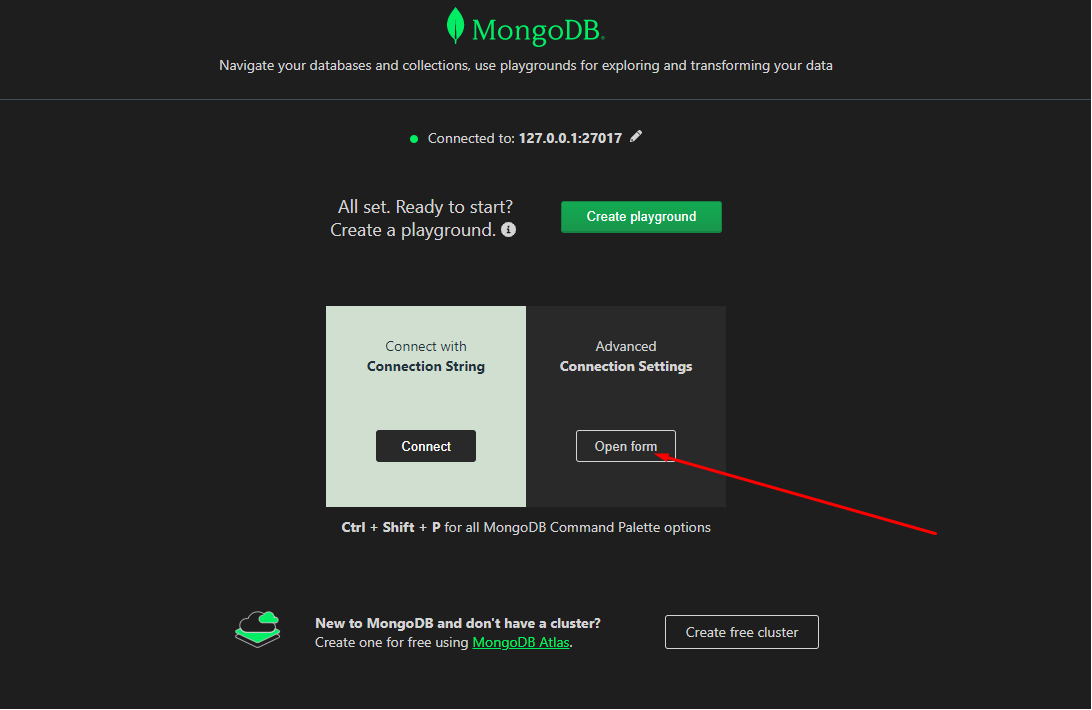 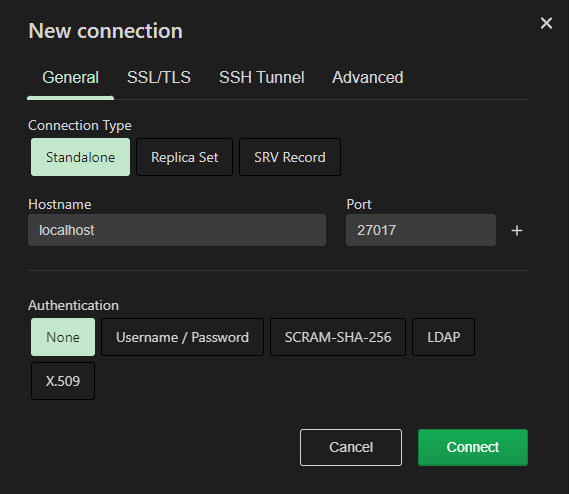 Прописываем адрес, логин и пароль для SSH: 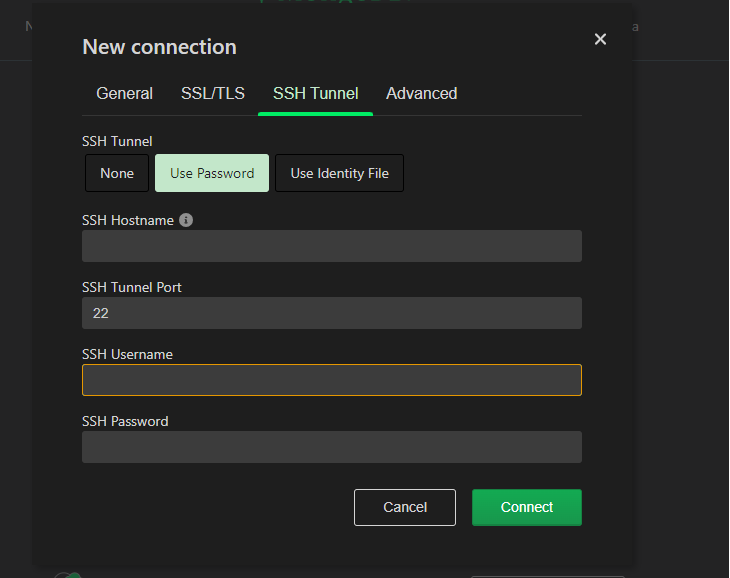 2\. Заходим в БД kuma 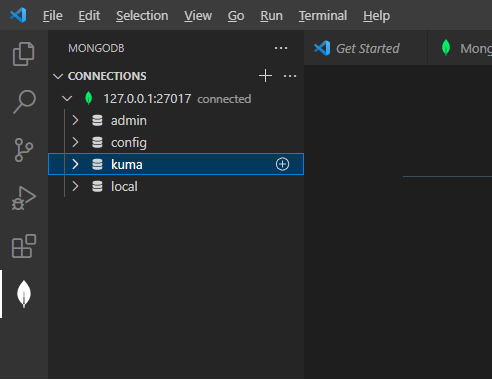 3\. Переходим в коллекцию resoureces и нажимаем на значок поиска  4\. Ищем ресурс по имени или ID (кому как удобно):  5\. Переходим в режим редактирования и далее можно перемежать блоки JSON нормализатора и других ресурсов, как вам удобно, для сохранения используте комбинацию клавиш Ctrl+S:  # Принцип работы правила агрегации (схематично) Отразим схематично принцип работы агрегации на примере событий аудита от ОС Linux: 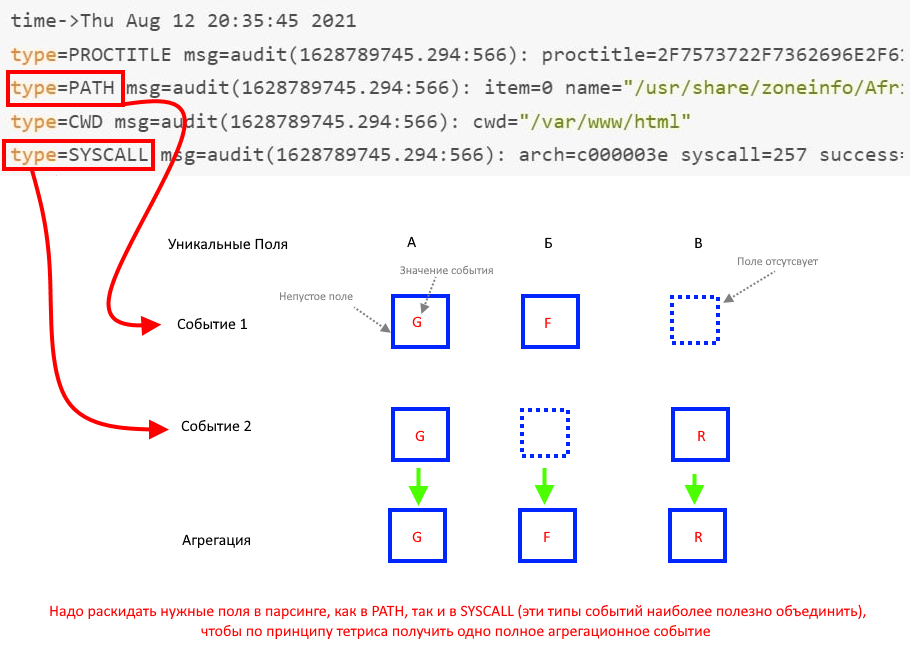При склейке множества событий в одно, порядок событий не сохраняется, т.к обработка многопоточная (на выход события могут прийти не в той последовательности, как на вход). Для того чтобы обработка происходила в 1 поток необходимо в настройках коллектора на 1 шаге указать количество рабочих процессов (workers) = 1. см пример со склейктой [тут](https://kb.kuma-community.ru/books/sozdanie-parserov-v-kuma-cookbook/page/obrabotka-mnogostrocnyx-sobytii-na-primere-auditd-v-kuma)
# Обработка многострочных событий на примере AuditD в KUMAОфициальный способ получения multiline auditd - через переключатель "auditd", который доступен в KUMA 3.2: [https://support.kaspersky.com/help/KUMA/3.2/ru-RU/220739.htm](https://support.kaspersky.com/help/KUMA/3.2/ru-RU/220739.htm) Описанный ниже способ является wa и примером обработки многострочных событий на примере AuditD и может быть перенесен на другие источники с похожей структурой событий.
### Введение В данной статье будет рассмотрен процесс (**workaround**) обработки многострочных событий на примере событий AuditD.1) Каждая пачка событий, попавшая под агрегацию будет посчитана как 2 события (не 2 пачки). Так что в общем случае, когда в многострочном событии 2 и более событий увеличение числа EPS не произойдет. 2) Метод не подразумевает сохранение исходных событий (**Raw**), при необходимости собирать сырые события нужно будет создать дополнительный коллектор, который будет за это отвечать 3) После склейки, многострочное событие записывается в одно поле (в примере далее это **Extra и Message**). Соответственно потребуется использование измененных нормализаторов.
Коробочный парсер в данном случае не подходит, но его можно использовать за основу.
Так как алгоритм работы цикличный, крайне рекомендуется прочитать данную статью два раза.
--- ### Принцип работы Ниже представлена схема работы склейки многострочного события. 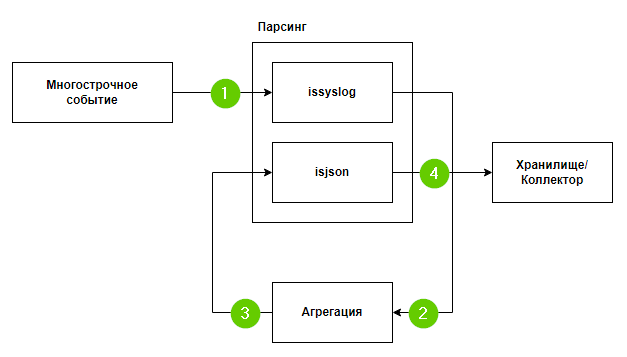Основная идея заключается в том, чтобы на коллекторе сагрегировать все события одного многострочного события в одно. Всю полезную информацию при агрегации записать в одно поле и затем отправить такое агрегированное событие обратно на вход коллектору для нормализации.
--- ### Алгоритм работы на примере Auditd 1\) На первом шаге в коллектор поступает событие, где происходит проверка, был ли отправлен syslog или json, в условиях экстранормализации, соответственно, выполняется проверка формата сообщения.В общем виде, проверка может быть любой. Основная идея - разделить на главном нормализаторе исходные события от источника от агрегированных событий.
Пример нормализации. 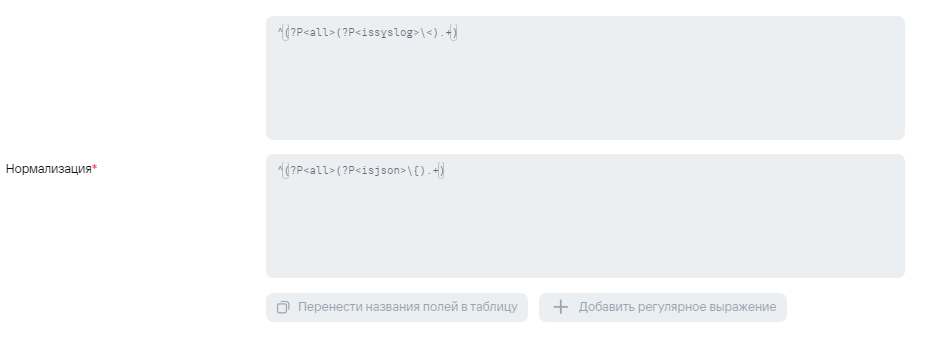 Пример условий для передачи событий в экстранормализатор, если событие исходное. 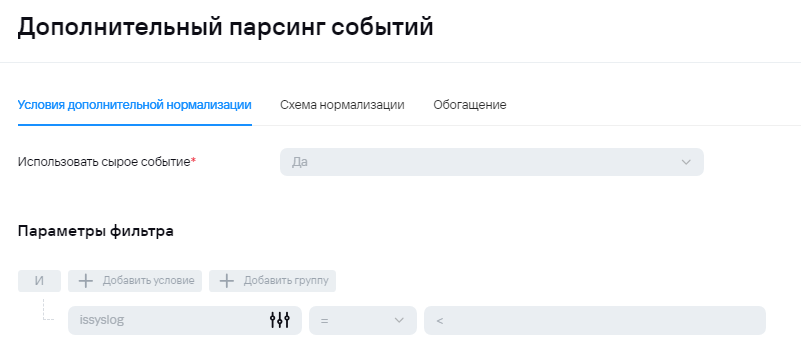Пример условий для передачи событий в экстранормализатор, если событие агрегированное. 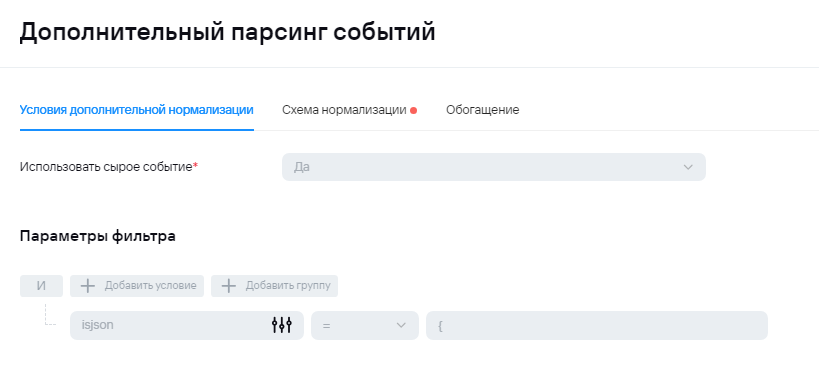2) В случае отправки syslog'а на этапе нормализации не будет происходит обогащения полями **DeviceProduct** и **DeviceVendor,** поэтому их можно будет добавить в условие для агрегации. Ниже приведен пример для агрегации событий AuditD:Здесь также проверка может быть любой. Основная идея - под правило агрегации должно попадать только исходное событие. Попадание под правила агрегации должно быть исключено для событий, попавших в коллектор второй раз. Также в поле суммы должно быть указано то поле, в которое на этапе парсинга пишутся полезные данные.
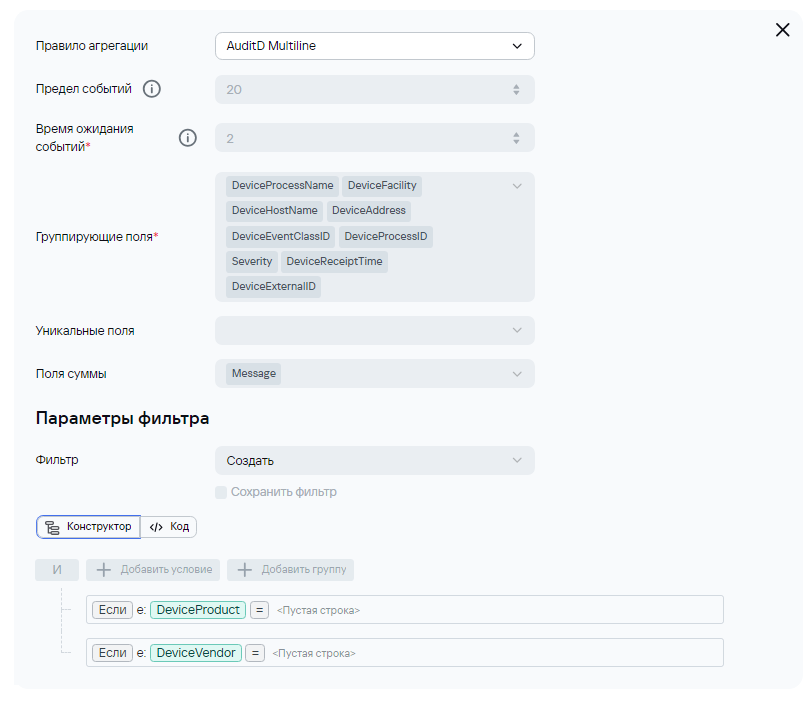 3\) На этапе маршрутизации есть две точки назначения: 1. **Storage for AuditD** - хранилище и **loop** - перенаправка событий обратно в коллектор (сам в себя). Во время этого этапа происходит проверка типа событий **loop** - для ***Type=2*** (агрегированные события) и **Storage for AuditD** для ***Type=1*** (базовые события). Обратите внимание, что при создании точки **loop,** нужно будет указать выходной формат **json**:Основная идея - разграничение точек назначения по типу событий. Обратно на вход коллектора должны подаваться агрегированные события, а в хранилище должны записываться только повторно обработанные события.
Пример точки назначения для отправки агрегированных событий в тот же коллектор 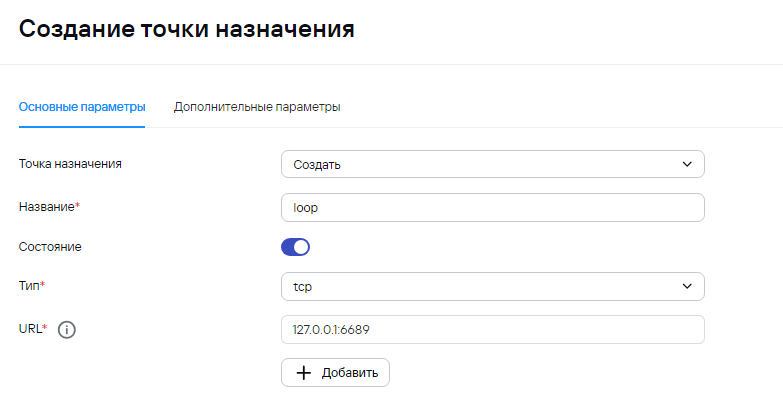 Пример условия для точки назначения для отправки агрегированных событий в тот же коллектор 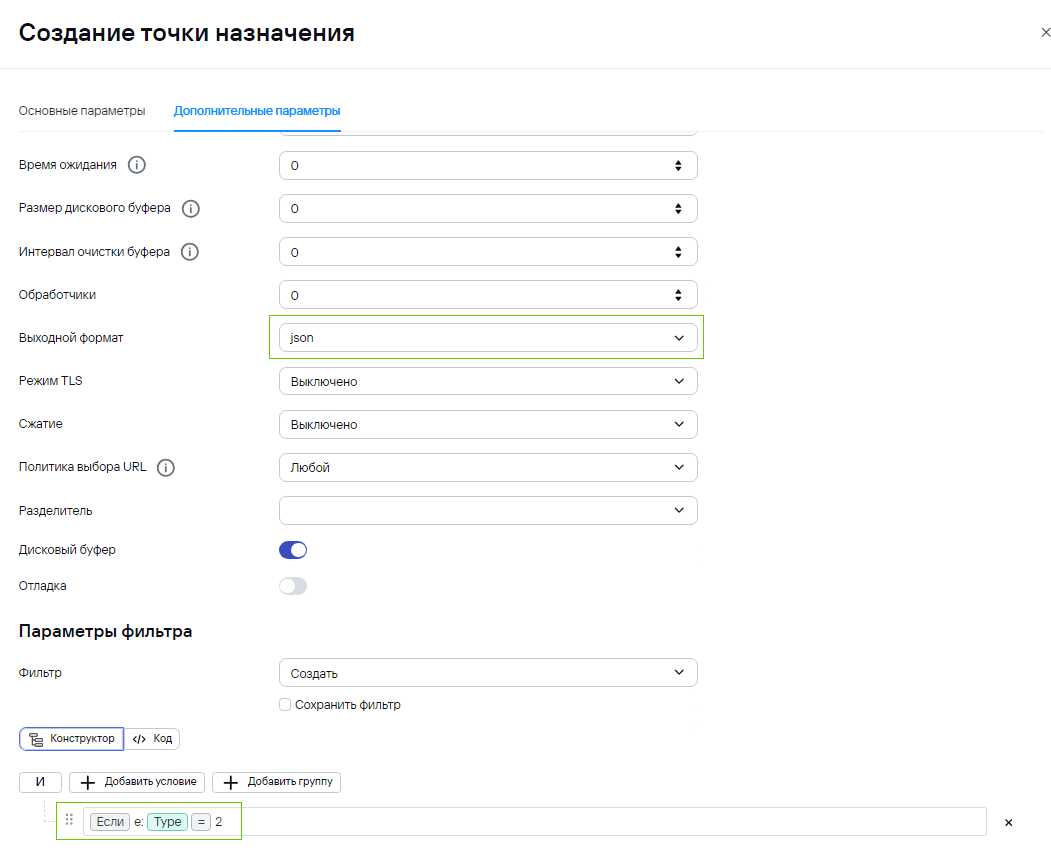 4\) После отправки агрегированного события на вход тому же коллектору, коллектор получает json, где уже происходит обогащение, а также вынос информации из Message в Extra. Это событие уже не будет считаться агрегированным из-за чего будет отправка в другую точку назначения.В общем случае, поле, в которое помещается информация из нескольких событий может быть любым. Также стоит учитывать максимально возможную длину полей.
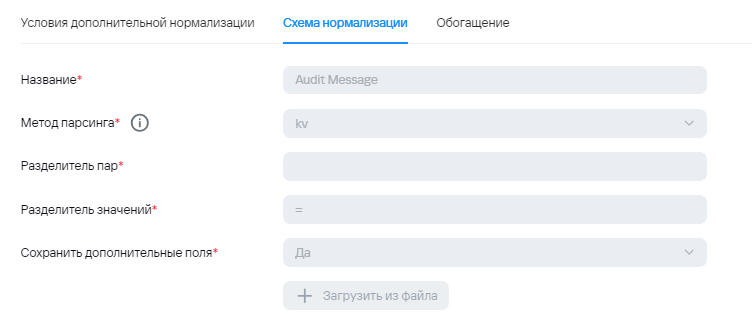 --- ### Заключение Метод приведенный выше позволяет склеивать и нормализовывать многострочные события, у которых есть общий идентификатор (id, timestamp или комбинация таких полей), по которому можно однозначно определить принадлежность каждого конкретного события к многострочному. Также, для простоты администрирования и нормализации можно использовать 2 коллектора вместо одного: - Первый коллектор агрегирует события, записывая всю полезную информацию в одно или несколько полей KUMA и отправляет на вход второму коллектору без отправки в Хранилище/Коррелятор. - Второй коллектор парсит полученные агрегированные события от первого и направляет нормализованные события в Хранилище/Коррелятор. --- ### Полезные ссылки 1\. Пример нормализатора и правила агрегации из примера: [https://github.com/KUMA-Community/kuma\_auditd\_multiline\_wa/](https://github.com/KUMA-Community/kuma_auditd_multiline_wa/) 2\. Принцип работы правил агрегации (схематично): [https://kb.kuma-community.ru/books/sozdanie-parserov-v-kuma-cookbook/page/princip-raboty-pravila-agregacii-sxematicno](https://kb.kuma-community.ru/books/sozdanie-parserov-v-kuma-cookbook/page/princip-raboty-pravila-agregacii-sxematicno)