Правила корреляции в KUMA (CookBook)
Этакий "CookBook" по правилам корреляции в KUMA
- Типы правил корреляции
- Использование Листов, Списков, Таблиц
- Приемы в правилах корреляции
- Тестирование правил корреляции (ретроскан)
- Производительность правил корреляции
- Сегментация правил корреляции
- Правила сбора и анализа данных (Data Mining)
- Конвертер правил Sigma
Типы правил корреляции
Простое правило (simple)
"Обновить параметры" нужно делать в корреляторе, когда какое-либо правило меняется, чтобы подтянулись актуальные изменения в правилах в коррелятор.
Простое правило (simple) — срабатывает при обнаружении каждого события, удовлетворяющего условиям в одном селекторе.
Типовой пример правила:
Параметр Наследуемые поля (Identical fields) имеет разный смысл, в зависимости от типа правила. В простом правиле он просто перечисляет, какие поля базового события коррелятор скопирует в корреляционное событие при срабатывании правила. Этот параметр обязательный, поэтому хотя бы одно такое поле нужно задать.
Например, если простое правило срабатывает на события о сетевых атаках, в идентичных полях уместно будет перечислить поля с информацией, характеризующие атаку: адрес злоумышленника, адрес жертвы, тип атаки. Аналитику следует посмотреть, в каких полях базовых событий содержится эта информация и перечислить эти поля в Наследуемых полях.
Если аналитик планирует создавать другие правила корреляции, которые реагируют не только на базовые, но и на корреляционные события, то от того, какие поля будут скопированы в корреляционное событие, будет зависеть, какие условия аналитик сможет использовать для такого события.
Простое правило используется, когда нужно создать алерт при обнаружении любого события, которое соответствует определенным условиям. В этом правиле есть только один селектор, который определяет эти условия.
Селектор работает как фильтр. В настройках селектора можно выбрать фильтр из существующих ресурсов или создать новый прямо в этом правиле. Также, как и в других фильтрах, можно использовать ссылки на другие фильтры в более сложных условиях. Например, можно задать условие: "Если поле события равно Х" или "Если выполняются условия фильтра Y".
При срабатывании правила аналитик может настроить одно или несколько из следующих действий:
- output — создать корреляционное событие, которое будет передано в настроенные точки назначения (обычно это хранилище), и по которому будет создано (или дополнен) алерт
- loop — переслать корреляционное событие на вход этого же коррелятора для рекурсивной обработки
- пополнить активные списки — добавить в активный список (или удалить из списка) запись на основании содержимого полей события
- обогатить корреляционное событие по словарю, по данным исходного события, константой или по шаблону, без запросов во внешние системы (т.е. такое же обогащение как в нормализаторе на коллекторе). Обогащение правилами можно задать в корреляторе отдельно, точно так же как в коллекторе
Необходимо указывать все поля и переменные участвующие в селекторах в наследуемых полях.
Создание правила корреляции типа Simple
В качестве примера создадим простое правило корреляции для обнаружения неудачной попытки входа в веб-интерфейс KUMA.
Чтобы настроить правило корреляции типа Simple:
1. Перейдите в раздел Ресурсы → Правила корреляции.
2. Опционально слева нажмите Добавить папку для создания отдельной папки под пользовательские правила.
3. В окне Новая папка укажите Название и нажмите Сохранить.
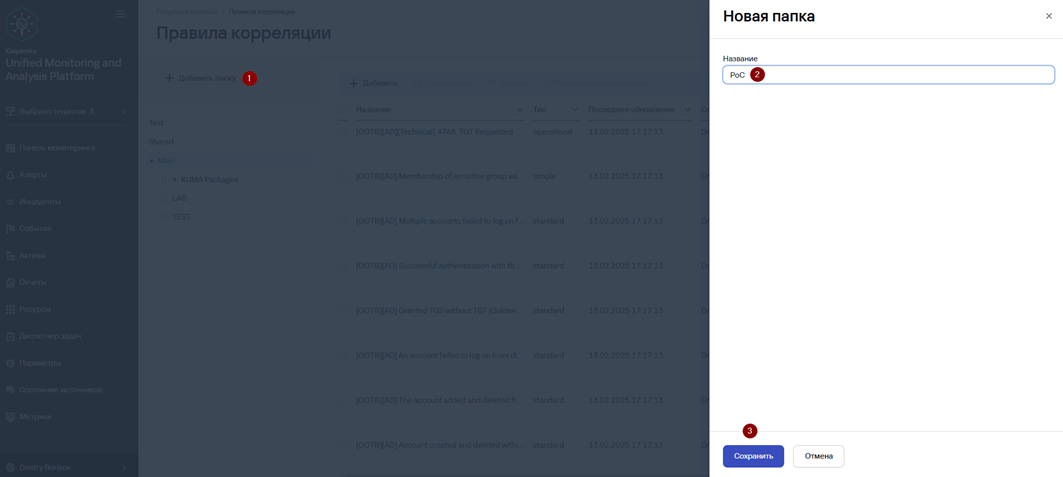
4. В панели слева выберите созданную папку и далее нажмите Добавить.
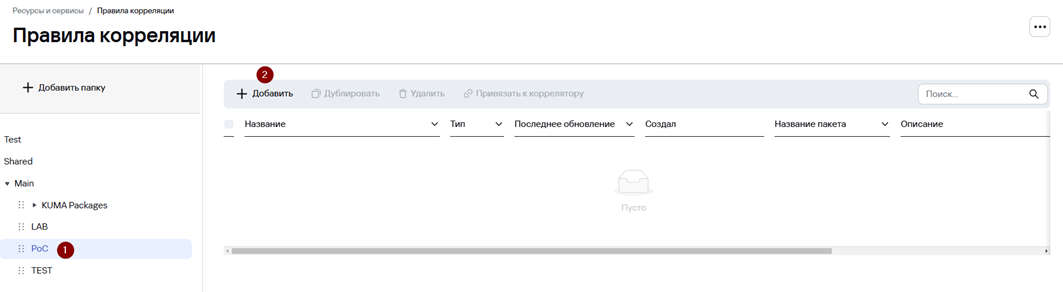
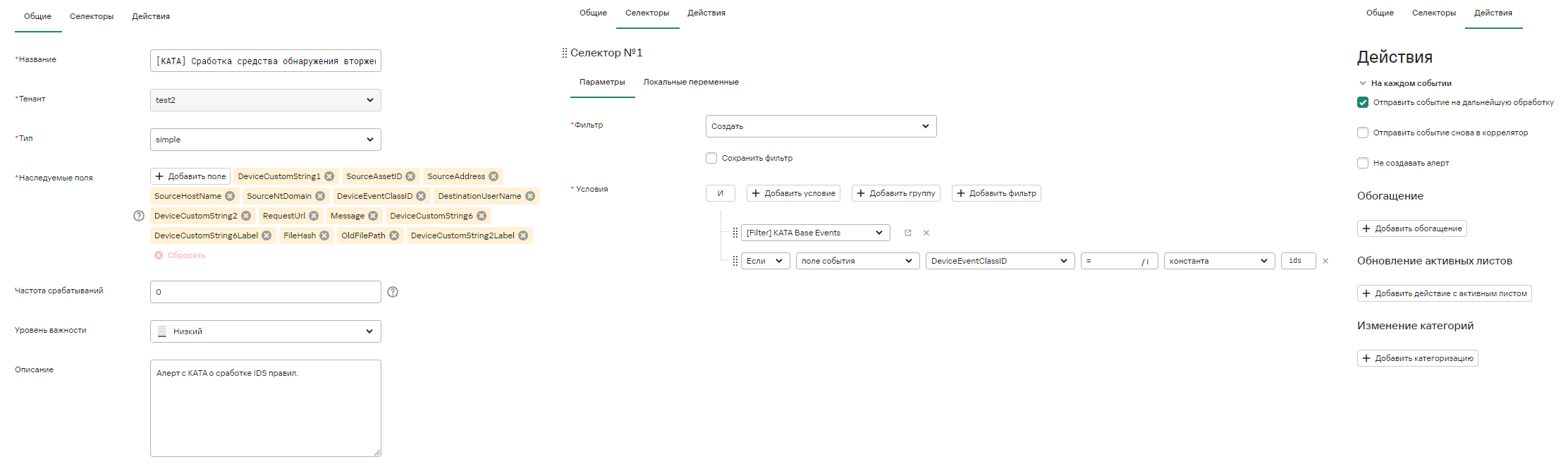
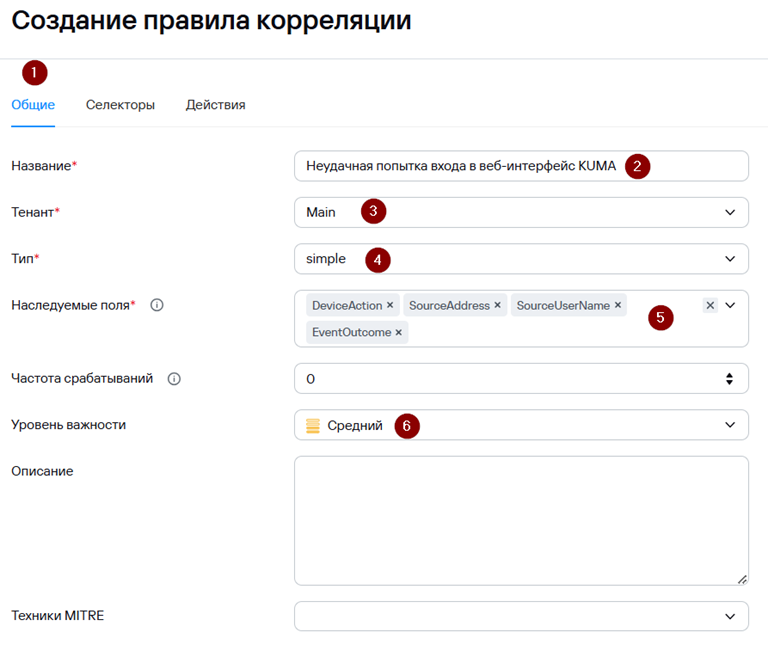
5. В появившемся окне Создание правила корреляции на вкладке Общие укажите:
· Название правила корреляции
· Тенант
· Тип (в нашем примере simple)
· Наследуемые поля (в нашем примере это поля DeviceAction, SourceAddress, SourceUserName и EventOutcome).
Наследуемые поля – это поля базового события, которые коррелятор скопирует в корреляционное событие при срабатывании правила.
Например, если простое правило срабатывает на событие неудачного входа в веб-интерфейс в наследуемых полях уместно будет перечислить поля с информацией под какой учетной записью и с какого адреса была выполнена неудачная попытка входа.
Какие поля с полезной информацией необходимо добавить в наследуемые можно «подсмотреть» в примере события, на которое Вы планируете, чтобы срабатывало правило корреляции и создавался алерт.
· Уровень важности (в нашем примере Средний)
· Опционально Описание
· Уровень важности (в нашем примере Средний)
· Опционально Описание
6. Перейдите на вкладку Селекторы и добавьте условия (Добавить условие) согласно скриншоту ниже. На вкладке Селекторы определяются условия, которым должны удовлетворять обрабатываемые события для срабатывания правила корреляции.
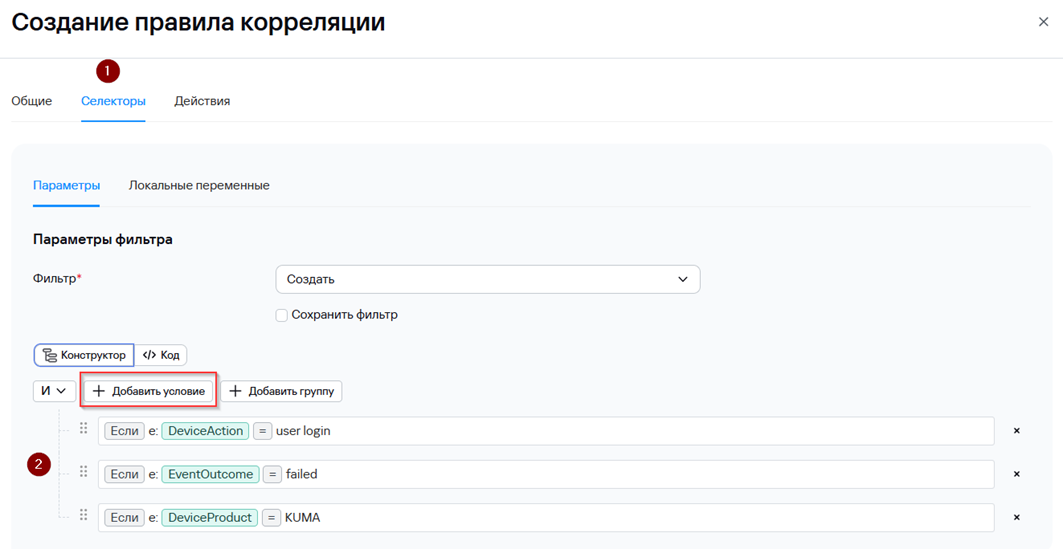
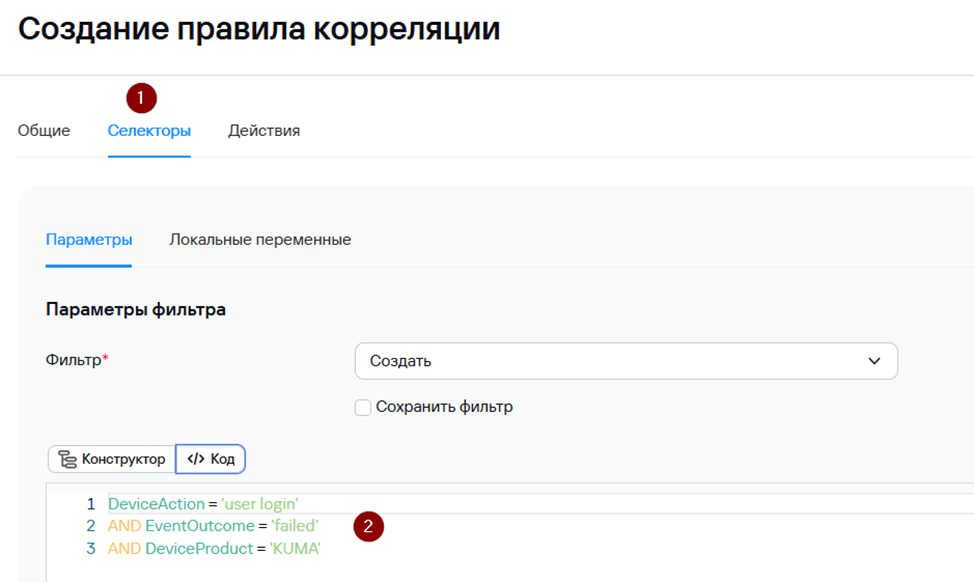
Условия можно задавать как в виде конструктора, так и в виде кода.
Какие поля и их значения необходимо использовать в качестве условий Селектора можно «подсмотреть» в примере события, на которое Вы планируете, чтобы срабатывало правило корреляции и создавался алерт.
Для повышения производительности более специфичные условия рекомендуется размещать выше, например, условие DeviceAction = ‘user login’ является более специфичным, чем условие DeviceProduct = ‘KUMA’.
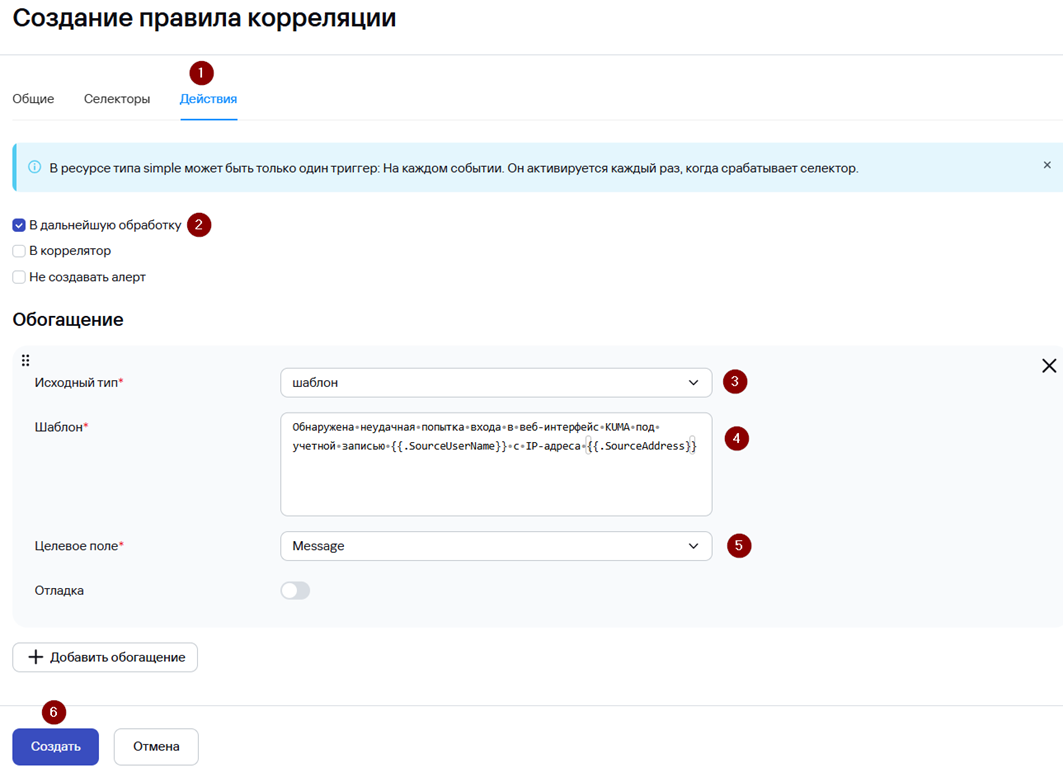
7. Перейдите на вкладку Действия и установите флажок возле параметра В дальнейшую обработку для отправки корреляционного события, создаваемого в результате срабатывания правила корреляции, на хранение в Хранилище.
8. Добавьте обогащение, нажав Добавить обогащение:
· Укажите Исходный тип – Шаблон
· В поле Шаблон добавьте следующий текст:
Обнаружена неудачная попытка входа в веб-интерфейс KUMA под учетной записью {{.SourceUserName}} c IP-адреса {{.SourceAddress}}
· В поле Целевое поле укажите Message
Данное обогащение является опциональным и используется для информирования аналитика какое потенциально вредоносное действие было совершено.
9. Нажмите Создать.
После создания правила корреляции необходимо выполнить его привязку к коррелятору:
1. Выберите созданное правило корреляции и нажмите Привязать к коррелятору.
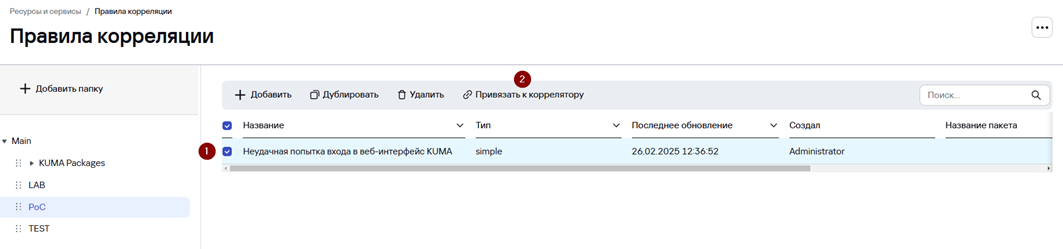
2. В окне Корреляторы выберите сервис Коррелятора, к которому будет привязано правило и нажмите ОК.
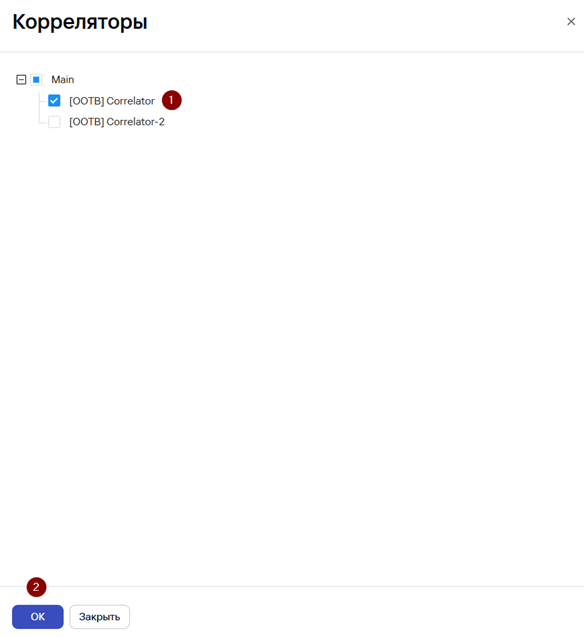
Чтобы коррелятор применил изменения конфигурации необходимо обновить параметры сервиса:
3. Перейдите в Ресурсы → Активные сервисы.
4. Нажмите ПКМ на сервис Коррелятора и выберите Обновить параметры.
Чтобы проверить корректность работы созданного правила корреляции выполните неудачную попытку входа в веб-интерфейс KUMA.
Для проверки, что созданное правило сработало:
1. Перейдите в Алерты.
2. Убедитесь, что в списке алертов присутствует алерт Неудачная попытка входа в веб-интерфейс KUMA

3. Откройте карточку алерта, нажав на алерт.
4. В карточке алерта в секции Связанные события нажмите на созданное корреляционное событие.
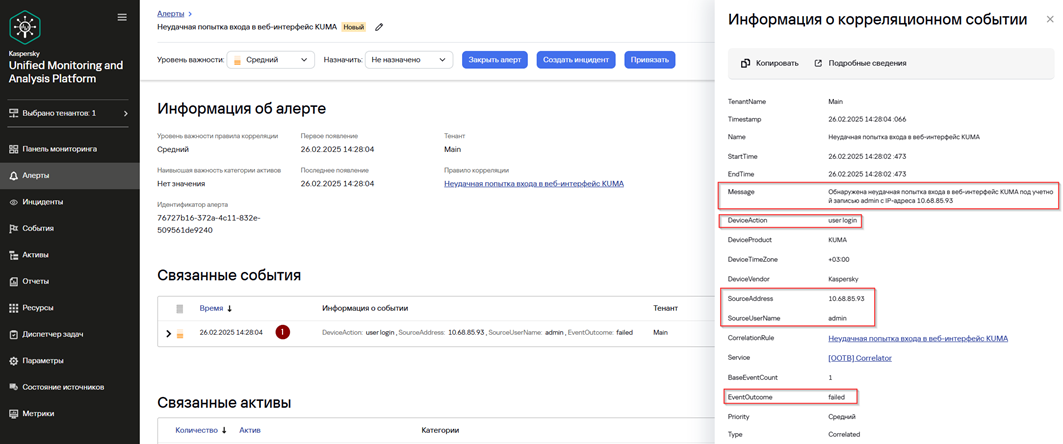
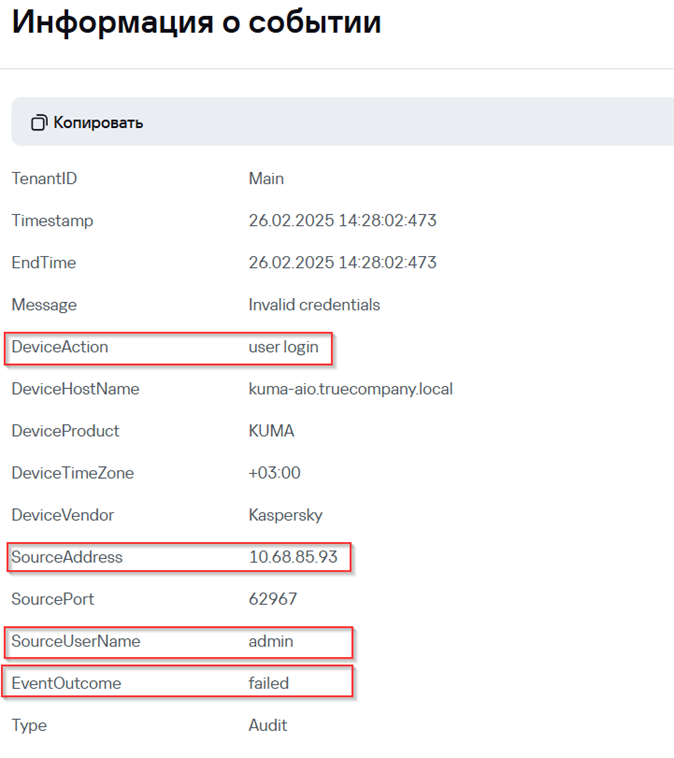
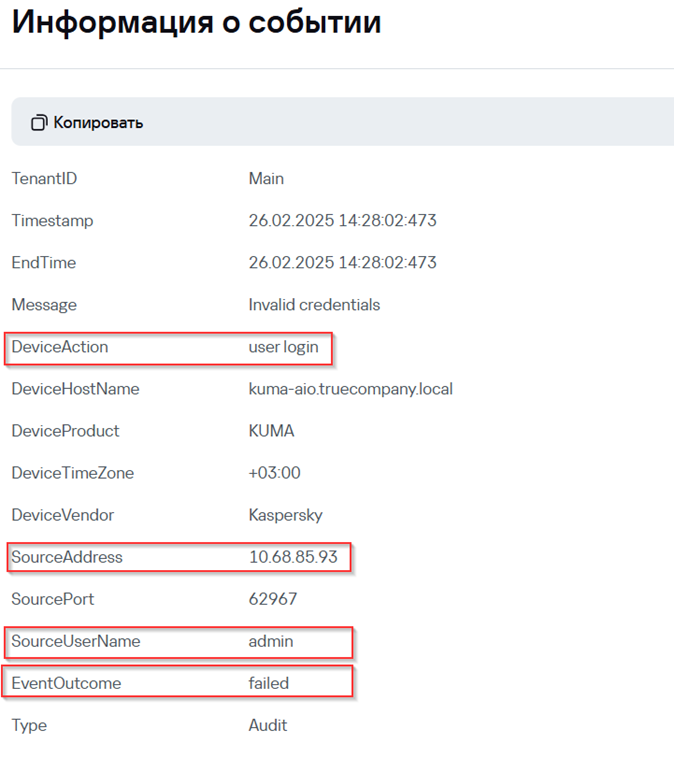
5. Убедитесь, что в окне Информация о корреляционном событии присутствуют поля, которые при создании правила корреляции были добавлены в Наследуемые поля:
· DeviceAction
· SourceAddress
· SourceUserName
· EventOutcome
6. Убедитесь, что в окне Информация о корреляционном событии в поле Message добавлен текст согласно ранее настроенному обогащению для информирования аналитика какое потенциально вредоносное действие было совершено.
Стандартное правило (standard)
"Обновить параметры" нужно делать в корреляторе, когда какое-либо правило меняется, чтобы подтянулись актуальные изменения в правилах в коррелятор.
Стандартное правило (standard) — срабатывает при достижении определенного порогового значения группы событий, которые удовлетворяют условиям селектора, полей группировки событий (на основе значений поля создается группа) и времени жизни контейнера для группы.
Если частота срабатывания (Rate limiting) явна не указана, то устанавливается лимит умолчанию - 100 срабатываний в секунду. При превышении лимита правило ничего не делает.
Политика хранения базовых событий (Base events keep policy) - указание, какие из базовых событий должны сохраняться в корреляционном. Возможно указать одно из значений:
- first (по умолчанию) - сохранять только первое базовое событие от каждого селектора в корреляционном событии
- last - сохранять только последнее базовое событие от каждого селектора в корреляционном событии
- all - сохранять все базовые события в корреляционном событии
Типовой пример правила (обнаружение сканирования портов, перебор портов >30 назначения, от одного адреса источника и назначения в течение 60 секунд):
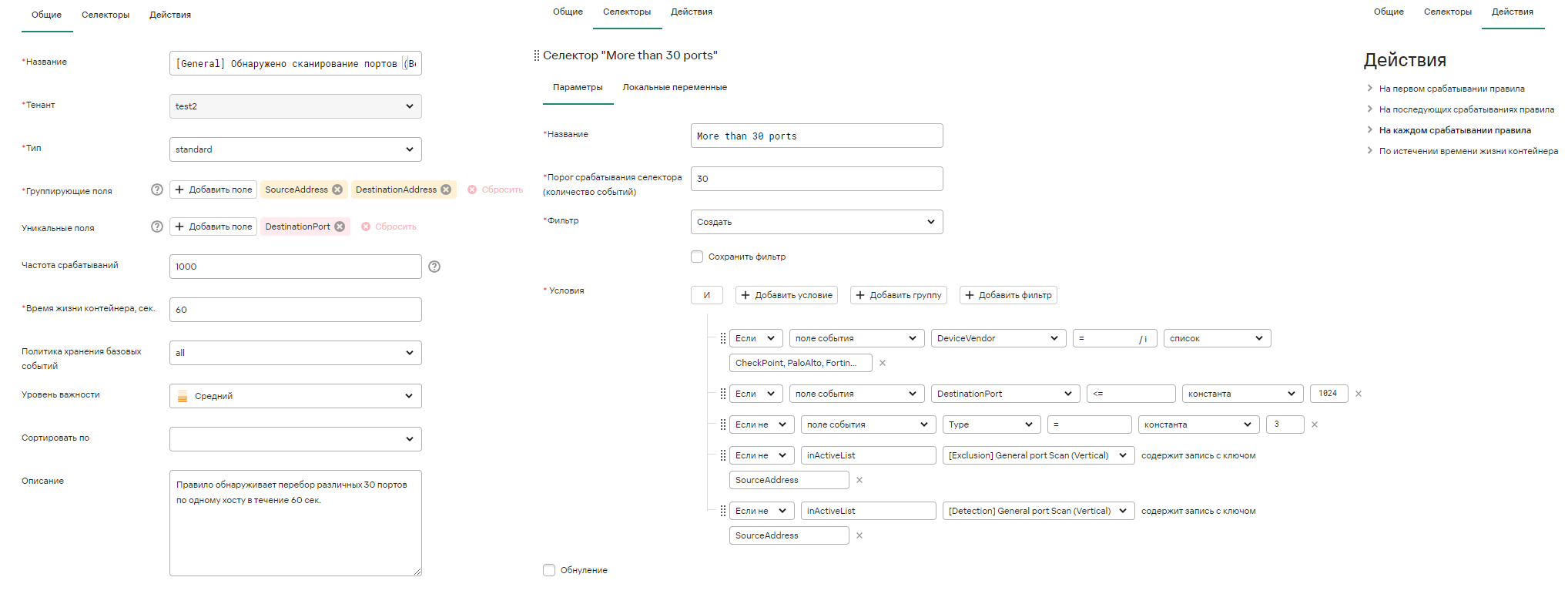
Другие подходящие примеры для стандартных правил:
- просто много обращений к опасным URL: с разных компьютеров и к разным URL
- много обращений к одному и тому же опасному URL с разных компьютеров
- много обращений к опасным URL, в том числе разным, с одного компьютера
- много обращений с одного и того же компьютера к одному и тому же опасному URL
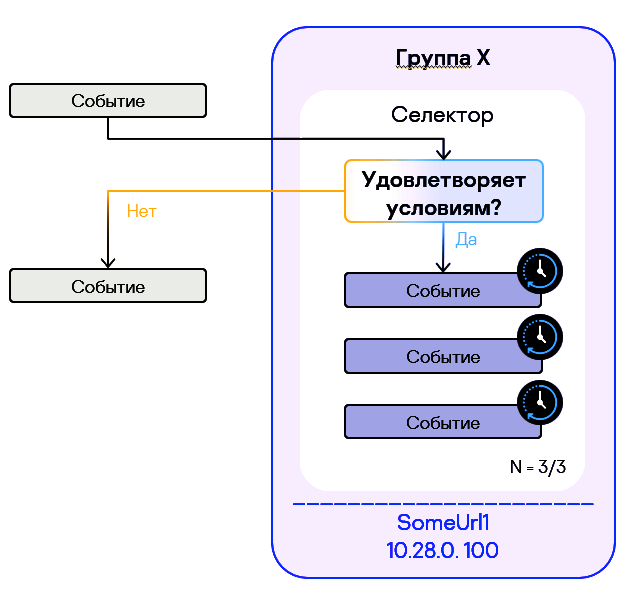
Стандартные правила разбивают все анализируемые события на группы (так называемые «корзины», buckets) с совпадающими значениями полей, перечисленных в параметре Группируемые поля (Identical fields) и затем обрабатывает каждую группу независимо от других. Критерии срабатывания применяются отдельно в каждой такой группе. Состояние всех групп хранится в памяти коррелятора.

Бакет (Окно корреляции):
- Бакет открывается на событие из любого селектора, не важно в каком они порядке в правиле, порядок проверяется после наполнения бакета!
- Для каждого набора Identical Fields создается свой бакет.
- Когда событие подпадает под селектор, коррелятор смотрит, есть ли уже бакет с нужным набором полей Identical Fields, если нет - создает, если есть - событие отправляется в существующий.
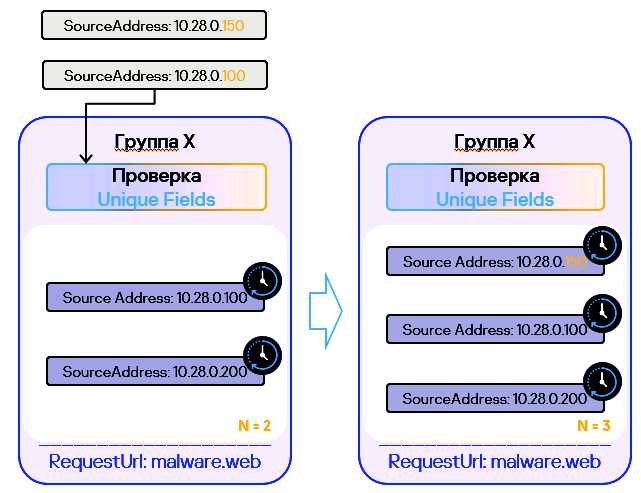
- Когда под селектор с Unique fields подпадает событие, то проверяется, есть ли уже в бакете события с таким же набором значений для Unique Fields, если есть, то событие не учитывается.
Пример для Identical Fields с полями RequestUrl и SourceAddress:

В более общем смысле параметр Время жизни контейнера (Window) определяет время жизни группы. Принцип такой:
- identical fields определяет, на какие группы разбивать события
- селекторы определяют, какие событие будут включены в группы (если событие не соответствует ни одному селектору, оно не попадет ни в одну группу)
- если событие соответствует селектору и уже есть группа с таким же набором значений идентичных полей, как в событии, событие добавляется в эту группу
- если событие соответствует селектору, но его значения идентичных полей не соответствуют ни одной группе, создается новая группа с временем жизни, заданным параметром Window
- по истечении времени жизни группы, группа удаляется
- если позже поступает новое событие с набором значений идентичных параметров группы, которой больше нет, создается новая группа и отсчет времени жизни начинается заново
Т.е. все свое время жизни (или окно наблюдения) группа накапливает события, после чего удаляется, и накопление событий может начаться заново. Для каждой комбинации значений идентичных полей это происходит параллельно и независимо.
Правило срабатывает, если группа за время жизни накапливает число событий, указанное в параметре Порог срабатывания (Threshold) селектора.
В общих настройках стандартного правила есть еще параметр Уникальные поля (Unique fields). Он не является обязательным, но он позволяет считать в группах только события с уникальными значениями выбранных полей. При добавлении событий в группу правило будет сравнивать значение уникальных полей нового события со значениями уникальных полей событий, которые уже есть в группе. Если комбинация значений уникальных полей нового событий уже встречается у одного из событий в группе, новое событие отбрасывается и в группу не попадает.
Возможные действия (допускается указать одно или более) правила:
- On first threshold — создавать корреляционное событие только после первого превышения порога, а двукратное, трехкратное и т.д. превышение порога за время жизни группы игнорировать. Например, если при пороге 3 за 30 секунд группа накопит 10 событий, корреляционное событие все равно будет одно - после третьего накопленного события
- On every threshold — создавать корреляционное событие после каждого превышения порога за время жизни группы. Если группа накопит 10 событий при пороге 3, будет создано 3 корреляционных события: после 3-го, 6-го и 9-го события в группе
- On subsequent threshold — создавать корреляционные событие при всех превышениях порога, кроме первого. Например, при пороге 3 после 6-го, 9-го и т.д. события. Так можно по-разному реагировать на первое переполнение порога и последующие. Например, можно настроить отправлять на вход коррелятора только первое корреляционное событие, но в хранилище писать все. Или пополнять активный список только данными из первого события, а при последующих превышениях порога этого не делать, так как в последующих событиях нет новых артефактов для списка
- On timeout — в стандартных правилах есть еще возможность настройки действий по окончании времени жизни группы. Это действие используется в связке с опцией Recovery (Обнуление) в настройках селектора, в каких случаях это уместно и как именно это работает рассматривается ниже. Обнуляющие селекторы можно использовать и не только с действием onTimeout.
Можно также использовать несколько селекторов. Например, несколько неудачных попыток брутфорса (ловится на основе сработки другого правила корреляции) и успешный вход. В общем случае правило, в котором задано несколько селекторов, срабатывает при одновременном превышении порогов во всех селекторах.
Пример правила с несколькими селекторами:
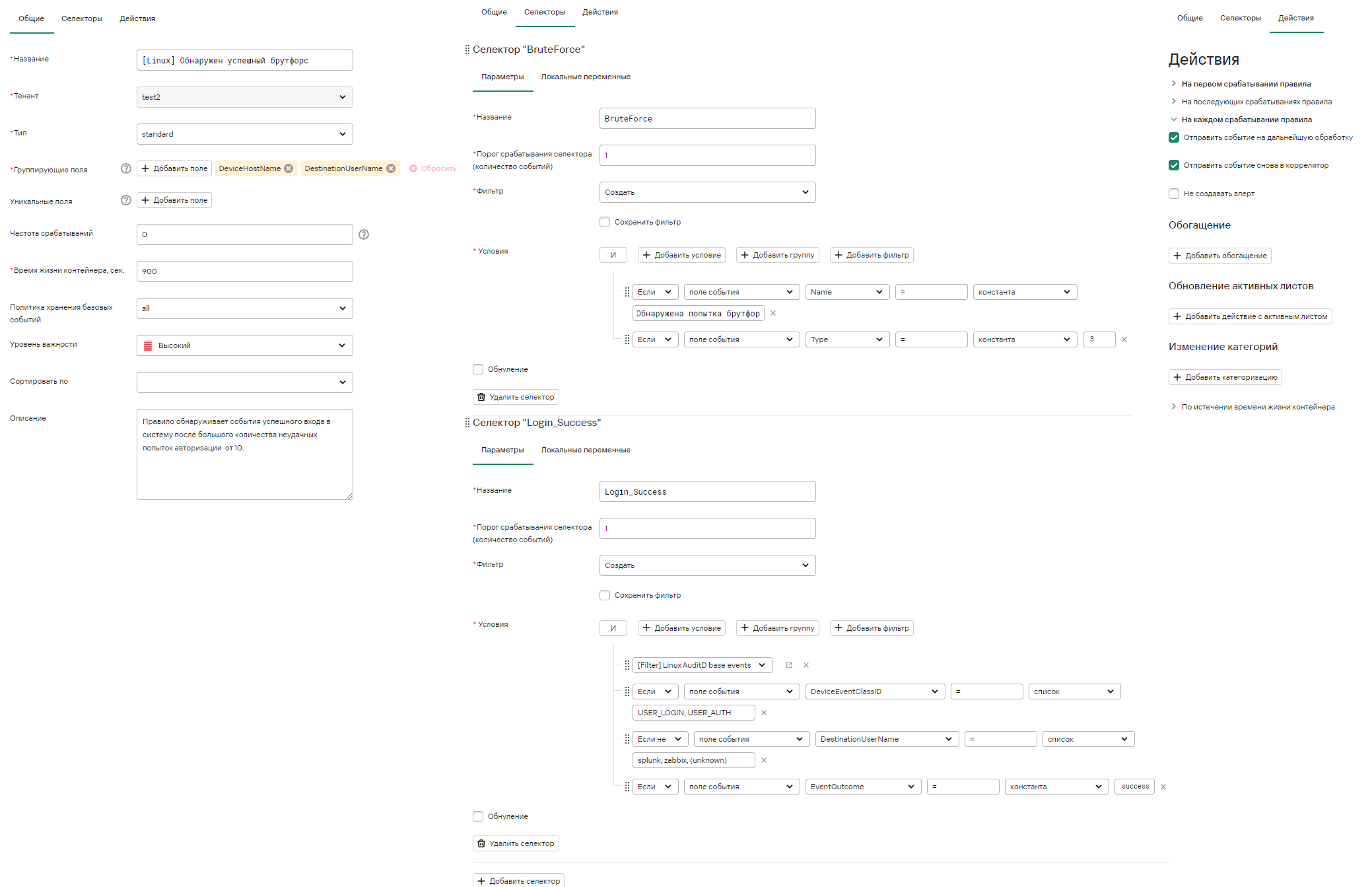
Можно также рекавери правило. Например, когда событие типа «Вредоносное ПО удалено» не обнаружено в течение 5 минут после получения события «Вредоносное ПО обнаружено».
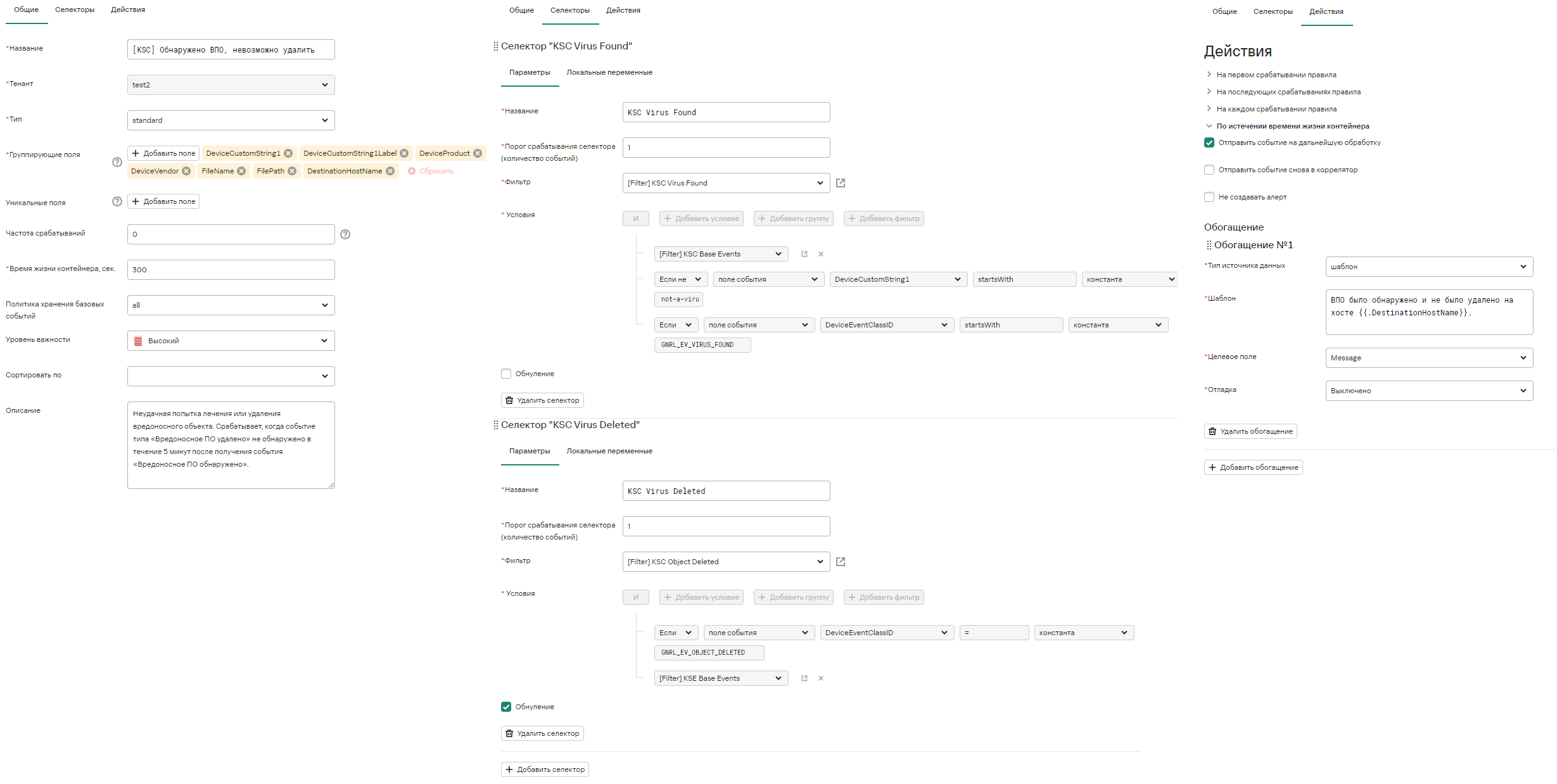
Recovery селектор (Обнуление):
- Бакет открывается только на событие из обычного селектора, на событие из recovery-селектора бакет не открывается никогда!
- Место нахождения селектора с recovery не имеет значения, как только в бакет попадут все нужные recovery-события бакет будет закрыт!
- На recovery-селектор не влияет настройка фильтра Order By.
- Если нужно, чтобы произошло событие А, и не произошло событие Б, при этом событие Б может произойти раньше А, нужно использовать активные листы, т.к. с помощью recovery-селектора такой логики не достичь (см п.1).
Создание правила корреляции типа Standard
В качестве примера создадим стандартное правило корреляции для обнаружения 3 (трех) неудачных попыток входа в веб-интерфейс KUMA.
Чтобы настроить правило корреляции типа Standard:
1. Перейдите в раздел Ресурсы → Правила корреляции.
2. В панели слева выберите ранее созданную папку для пользовательских правил корреляции и далее нажмите Добавить.
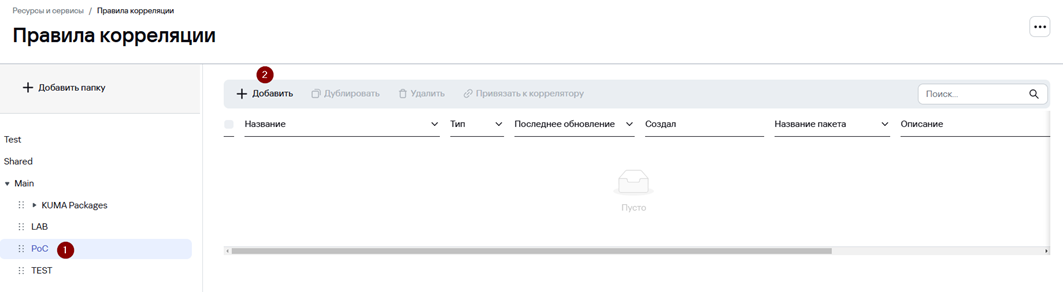
3. В появившемся окне Создание правила корреляции на вкладке Общие укажите:
· Название правила корреляции
· Тенант
· Тип (в нашем примере standard)
· Группирующие поля (в нашем примере это поля DeviceAction, SourceAddress, SourceUserName и EventOutcome).
Стандартные правила разбивают все поступающие события на группы («бакеты»), с совпадающими значениями полей из Группирующих полей. Затем каждая сформировавшаяся группа обрабатывается независимо от других. Критерии срабатывания применяются отдельно в каждой такой группе.
По аналогии с Наследуемыми полями правил Simple значения полей, перечисленных в Группирующих полях, будут скопированы в корреляционное событие.
Какие поля необходимо добавить в группирующие можно «подсмотреть» в примере события или событий, на которые Вы планируете, чтобы срабатывало правило корреляции и создавался алерт.
· Время жизни контейнера (в нашем примере «в течение какого периода времени мы ожидаем 3 неудачные попытки входа»)
Время жизни контейнера («бакета») в секундах. Отсчет времени начинается при создании контейнера, когда контейнер получает первое событие.
· Уникальные поля
Не является обязательным, но позволяют реализовать более сложную логику правила корреляции. Не рассматривается в данном примере.
При добавлении событий в группу («бакет») правило будет сравнивать значение уникальных полей нового события со значениями уникальных полей событий, которые уже есть в группе. Если комбинация значений уникальных полей нового событий уже встречается у одного из событий в группе, новое событие отбрасывается и в группу не попадает.
· Политика хранения базовых событий (в нашем примере all)
Позволяет определить, какие базовые события требуется поместить в корреляционное событие.
· Уровень важности (в нашем примере Высокий)
· Сортировать по (в нашем примере Timestamp)
Поле события, на основании которого события будут отсортированы в группе («бакете»).
· Опционально Описание
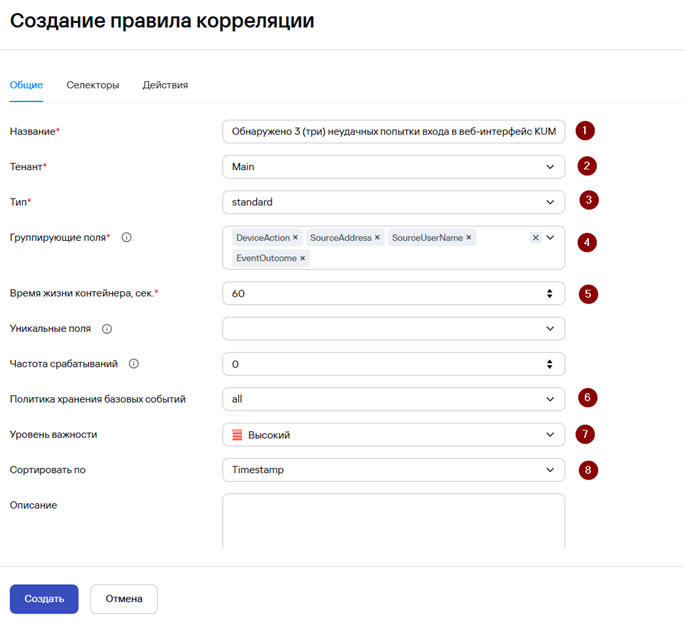
4. Перейдите на вкладку Селекторы, укажите Название селектора, Порог срабатывания селектора (количество событий; в нашем примере мы ожидаем 3 события неудачной попытки входа) и добавьте условия (Добавить условие) согласно скриншоту ниже. На вкладке Селекторы с помощью условий определяется какие события будут включены в группы (если событие не соответствует ни одному селектору, оно не попадет ни в одну группу).
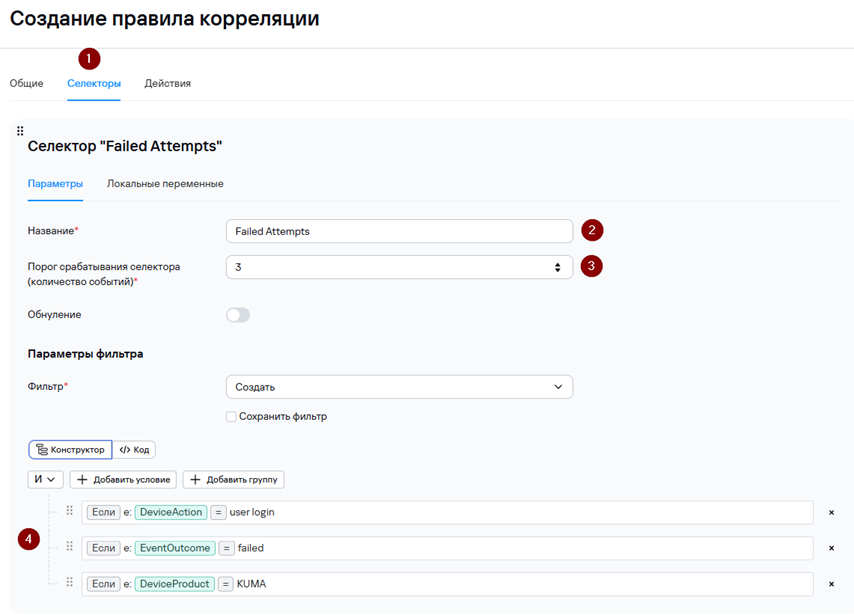
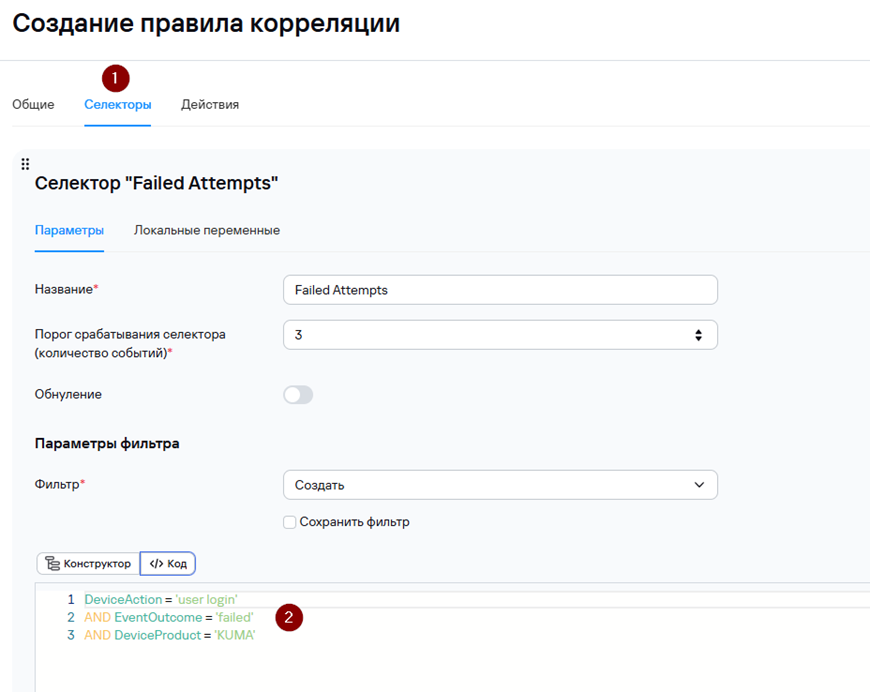
Условия можно задавать как в виде конструктора, так и в виде кода.
Какие поля и их значения необходимо использовать в качестве условий Селектора можно «подсмотреть» в примере события, на которое Вы планируете, чтобы срабатывало правило корреляции и создавался алерт.
Для повышения производительности более специфичные условия рекомендуется размещать выше, например, условие DeviceAction = ‘user login’ является более специфичным, чем условие DeviceProduct = ‘KUMA’.
В стандартном правиле можно добавить несколько селекторов.
5. Перейдите на вкладку Действия, выберите триггер На каждом срабатывании правила (т.е. при каждых трех неудачных попытках входа будет срабатывать правило корреляции и создаваться алерт), установите флажок возле параметра В дальнейшую обработку для отправки корреляционного события, создаваемого в результате срабатывания правила корреляции, на хранение в Хранилище.
6. Добавьте обогащение, нажав Добавить обогащение:
· Укажите Исходный тип – Шаблон
· В поле Шаблон добавьте следующий текст:
Обнаружено 3 (три) неудачные попытки входа в веб-интерфейс KUMA под учетной записью {{.SourceUserName}} c IP-адреса {{.SourceAddress}} в течение 60 секунд
· В поле Целевое поле укажите Message
Данное обогащение является опциональным и используется для информирования аналитика какое потенциально вредоносное действие было совершено.
7. Нажмите Создать.
После создания правила корреляции необходимо выполнить его привязку к коррелятору:
- Выберите созданное правило корреляции и нажмите Привязать к коррелятору.
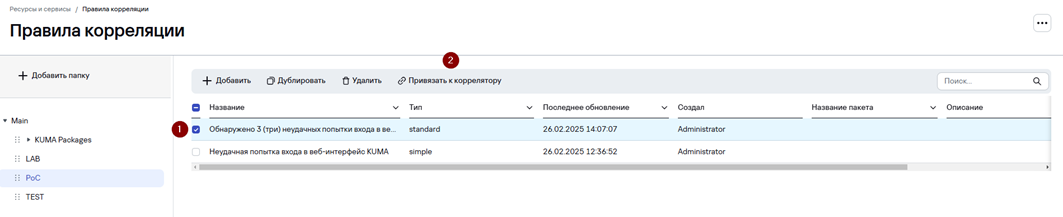
2. В окне Корреляторы выберите сервис Коррелятора, к которому будет привязано правило и нажмите ОК.
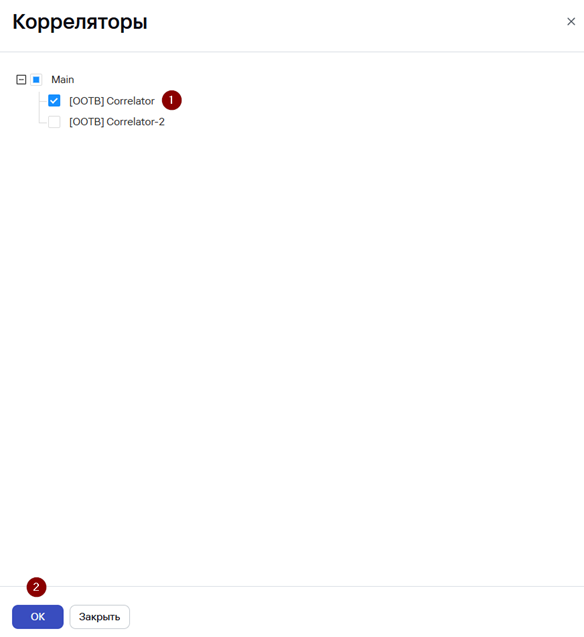
Чтобы коррелятор применил изменения конфигурации необходимо обновить параметры сервиса:
3. Перейдите в Ресурсы → Активные сервисы.
4. Нажмите ПКМ на сервис Коррелятора и выберите Обновить параметры.
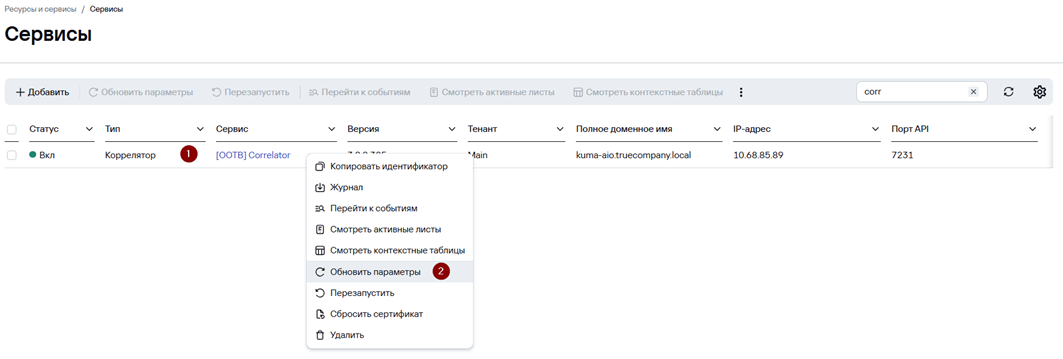
Чтобы проверить корректность работы созданного правила корреляции выполните 3 неудачных попытки входа в веб-интерфейс KUMA в течение 60 секунд.
Для проверки, что созданное правило сработало:
1. Перейдите в Алерты.
2. Убедитесь, что в списке алертов присутствует алерт Обнаружено 3 (три) неудачных попытки входа в веб-интерфейс KUMA

3. Откройте карточку алерта, нажав на алерт.
4. В карточке алерта в секции Связанные события раскройте созданное корреляционное событие и далее нажмите на корреляционное событие.
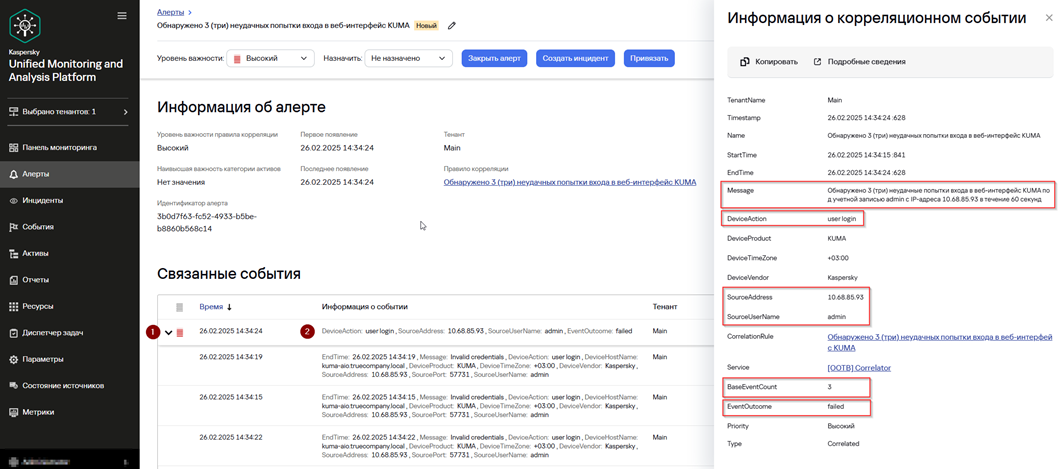
5. Убедитесь, что в окне Информация о корреляционном событии присутствуют поля, которые при создании правила корреляции были добавлены в Группирующие поля:
· DeviceAction
· SourceAddress
· SourceUserName
· EventOutcome
6. Убедитесь, что в окне Информация о корреляционном событии в поле Message добавлен текст согласно ранее настроенному обогащению для информирования аналитика какое потенциально вредоносное действие было совершено.
7. Убедитесь, что при раскрытии корреляционного события отображается 3 события неудачной попытки входа, которые стали триггером для срабатывания правила корреляции.
|
Статья онлайн-справки «Правила корреляции»: https://support.kaspersky.ru/kuma/3.2/217783
KUMA Community правила корреляции в KUMA (CookBook): https://kb.kuma-community.ru/books/pravila-korreliacii-v-kuma-cookbook
Видео «Работа с правилами корреляции»: https://rutube.ru/video/cc57b965e06574165617b37ea1d8ac96/?playlist=891489 |
Операционное правило (operational)
"Обновить параметры" нужно делать в корреляторе, когда какое-либо правило меняется, чтобы подтянулись актуальные изменения в правилах в коррелятор.
Операционное правило (operational) — наполняет активные листы без создания корреляционного события, механика работы аналогична простому правилу корреляции. С помощью списков можно отслеживать закономерности на длительных промежутках времени. Активный список хранится в памяти коррелятора (и кешируется на диск), так что состояние списка не теряется при перезагрузке службы или сбое.
Наполнять список могут любые правила. Но простые и стандартные правила всегда создают корреляционные события и предупреждения. Чтобы просто наполнять список и не создавать предупреждений, предусмотрены операционные правила.
В операционном правиле доступны только две операции над списком: set и del. Операция get не имеет смысла, поскольку она призвана обогащать корреляционное событие, а операционное правило не создает таких событий.
Пример правила:
Если при выполнении операции set окажется, что запись с таким же ключом уже есть в списке, она будет перезаписана новым значением на основании полей нового события.
При записи в активный лист, в качестве ключевого поля могут быть несколько занчений полей события, для составления комбинированного ключа, при этом в значении ключа это быдет выглядеть так: поле1|поле2|поле3 сравнивать с этим впоследствии можно будет только с целым ключом, а не с какой-то его частью.
Атрибуты записей из активного списка можно использовать для обогащения корреляционных событий. Для этого его нужно сохранить в виде атрибута записи в активном списке операционным правилом. А затем в корреляционном правиле в разделе действий нужно будет выполнить операцию get над активным списком и записать в какое-нибудь поле корреляционного события содержимое атрибута записи из активного списка.
Если есть несколько служб коррелятора, использующих один и тот же ресурс списка, у каждой будет свое состояние этого списка.
Чтобы просмотреть содержимое списка нужно открыть список активных сервисов (Active services), выбрать службу типа Correlator (поставить галочку слева) и у нее появится активная кнопка Go to active lists (Перейти в активные листы).
Аналитик может экспортировать и импортировать, а также очистить содержимое списка. Аналитик также может отобразить содержимое списка, увидеть, какие в нем есть записи, когда они были созданы или обновлены, и когда у них истекает время жизни, если для списка настроено время жизни. Аналитик может вручную удалять (но не редактировать) записи.
Каждую запись можно открыть и изучить ее дополнительные атрибуты.
Использование Листов, Списков, Таблиц
Общая информация
Контекстные таблицы и активные листы:
- живут на корреляторе;
- по большей части наполняются им же, реже - вручную и через API;
- используются для корреляционной логики и обогащения на корреляторе.
Важно! Содержимое активного листа/контекстной таблицы РАЗНОЕ на каждом корреляторе.
Словарь / таблица - это ключ и значение, который можно задать один раз и ручками править (можно через API), этот словарь доступен в коллекторах и на корреляторах, причем он один может быть доступен сразу всем. Поле значение не обязательно использовать, можно его пустым сделать, можно "-", "0" написать туда, как удобно. Особенности словарей и таблиц:
- живут на ядре, но транслируются на все сервисы, где они указаны;
- наполняются только вручную или через API, более статичны;
- используются в основном для обогащения на коллекторах/корреляторах, реже для корреляционной логики.
Если словарь содержит более 5000 записей, тогда KUMA в веб-интерфейсе не отображает содержимое словаря. Чтобы изменить содержимое словаря, отредактируйте CSV-файл и загрузите его в KUMA.
Важно! Содержимое словаря/таблицы ОДИНАКОВОЕ для всех сервисов, где он используется.
Активный список / лист
Активный лист (AL) – это контейнер для данных (представляет собой структуру ключ и значение), предназначенный для быстрой записи/чтения динамических данных, доступных всем фильтрам и корреляционным правилам в рамках одного сервиса Коррелятора. Чтобы их посмотреть, нужно из активных сервисов нажать кнопку Смотреть активные листы.
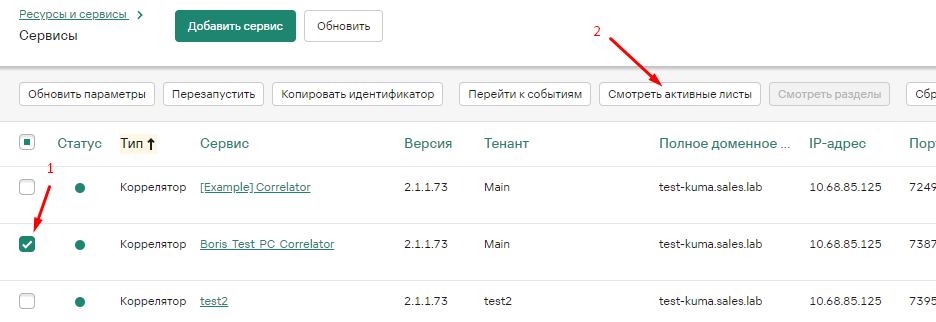
Взаимодействовать с активным листом могут не только компоненты коррелятора, но и пользователи, с помощью Web-консоли и API. Пользователь KUMA имеет возможность работы с данными AL:
- выполнять поиск по именам записей (выполняться по полному вхождению указанной пользователем подстроки);
- удалить записи;
- открыть содержимое записи.
Производительность активных листов комфортан (максимальна) с десятками тысяч записей.
Активные листы работают в памяти коррелятора, также при работе активного листа используется Write-Ahead Log (WAL), который предполагает сохранение каждого изменения состояния в виде двоичного файла на жестком диске. Каждой записи журнала присваивается уникальный идентификатор, позволяющий выполнять дополнительные операции с журналом, такие как сегментация журнала и очистка. Уникальность записей журнала также помогает применять обновления журнала с использованием единой очереди обновлений, обеспечивая последовательные и согласованные обновления.
Примеры использования тут.
Синхронизация активного листа между несколькими корреляторами. ВАЖНО это не поддерживаемый и не официальный сценарий. Можно попробовать сделать так: WAL записывается на сетевую папку, примонтиованную к двум корреляторам. И если один из корреляторов упал, скрипт (заранее написанный) запускает службу второго коррелятора. Второй коррелятор перечитает WAL и импортирует данные в лист.
Конекстная таблица
Конекстная таблица - это тот же лист, только с дополнительными возможностями по хранению в разных полях разных структур данных. Существует только в рамках конкретного коррелятора, в который она была добавлена либо через фильтры, либо через действия в корреляционных правилах.
Функциональные возможности контекстных таблиц:
- список ключевых полей определяется пользователем;
- данные в контекстных таблицах типизированы (целые числа, числа с плавающей точкой, строки, логический тип, timestamp, IP);
- поддерживаются массивы для всех типов данных, перечисленных выше;
- в корреляции, для полей с массивами возможны подсчеты уникальных значений, вычисление длины массива, обращение к определенному элементу массива.
Примеры использования тут.
Приемы в правилах корреляции
Сравнение с константой

Сравнение с листом/списком
Аналогично =константе ИЛИ =константе
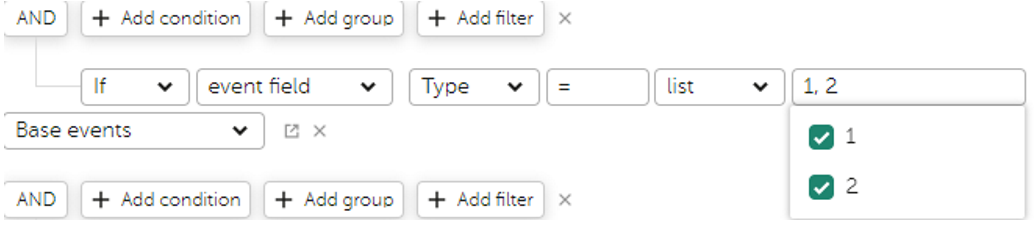
Содержит список констант регистронезависимый
Ищется заданная подстрока “whoami” или "ipconfig" и др в занчении поля DestinationProcessName
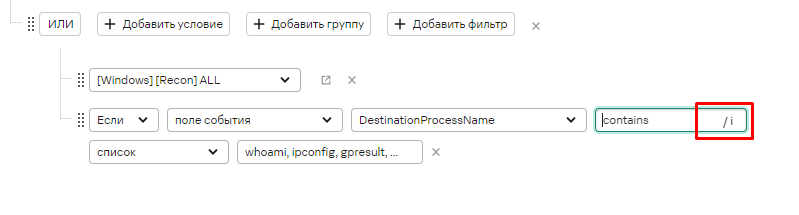
Соответствие регулярному выражению (REGEX)
Должно быть условие регулярного выражения в формате RE2

Работа с подсетями

Содержит любое значение (не пустое)

Активный список / лист
Активный лист содержит ключ
Ключ листа должен совпадать со значением поля Message

Сравнение по экстра данным в активном листе (неключевому полю)
В актуальных версиях, используйте комбинацию Ctrl+Enter для прододжения наполнения условия в конструкторе
Где threat_score > 70

Фильтр по количеству записей по ключу в активном листе
Где количество записей > 1, используется служебная переменная _count

Другие служебные поля активных листов:
- _count (счетчик количества записей)
- _created (время создания записи UnixTime, в наносекундах)
- _updated (время обновления записи UnixTime, в наносекундах)
- _expires (время окончания жизни записи UnixTime, в наносекундах)
- _key (значение ключевой записи)
Событие истечения времени жизни в активном листе
Возникает служебное событие active list record expired, помимо этого необходимо указать UUID активного листа в поле DeviceExternalID

Значение ключевого поля передатся в DevicePayloadID служебного события.
Работа с активным листом не по его ID
Если указывать ID листа неудобно (а это обычно так), то можно в ключевое поле писать уникальный префикс типа "failed login attempts|username|1.1.1.1" и в события ловить по полю devicePayloadID функцией startsWith "failed login attempts" такой вариант реализации правила не зависит от инсталляции.
Такие события существуют только в рамках коррелятора (служебные события) и не сохраняются в сторадже, их можно поймать только правилом корреляции.
Сравнение переменной с числовым значением
Из строки с REGEX вырезается число и кладется его в переменную, например, для получения SID пользователя из "SID: 1-21-1231-500", получаем "500", кладем в переменную $temp, чтобы сделать сравнение необходимо $temp привести к числовому типу это можно сделать новой переменной $usersid = $temp + 0 и далее сравнивать, например, $usersid > 1000
Условие с полем TI, сравнение с категорией
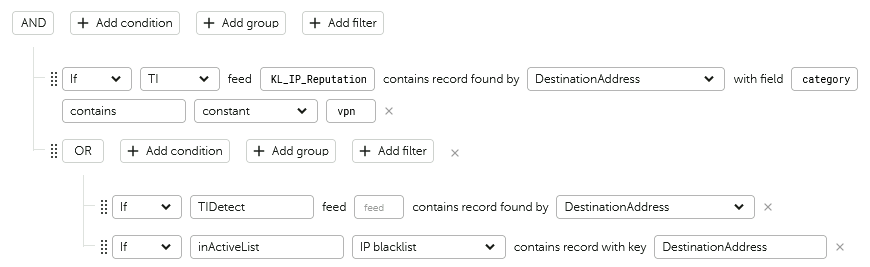
Значение feed это именование фидов из CyberTrace, например для фидов Kaspersky бывают такие значения (зависит какие фиды приобретены/подключены):
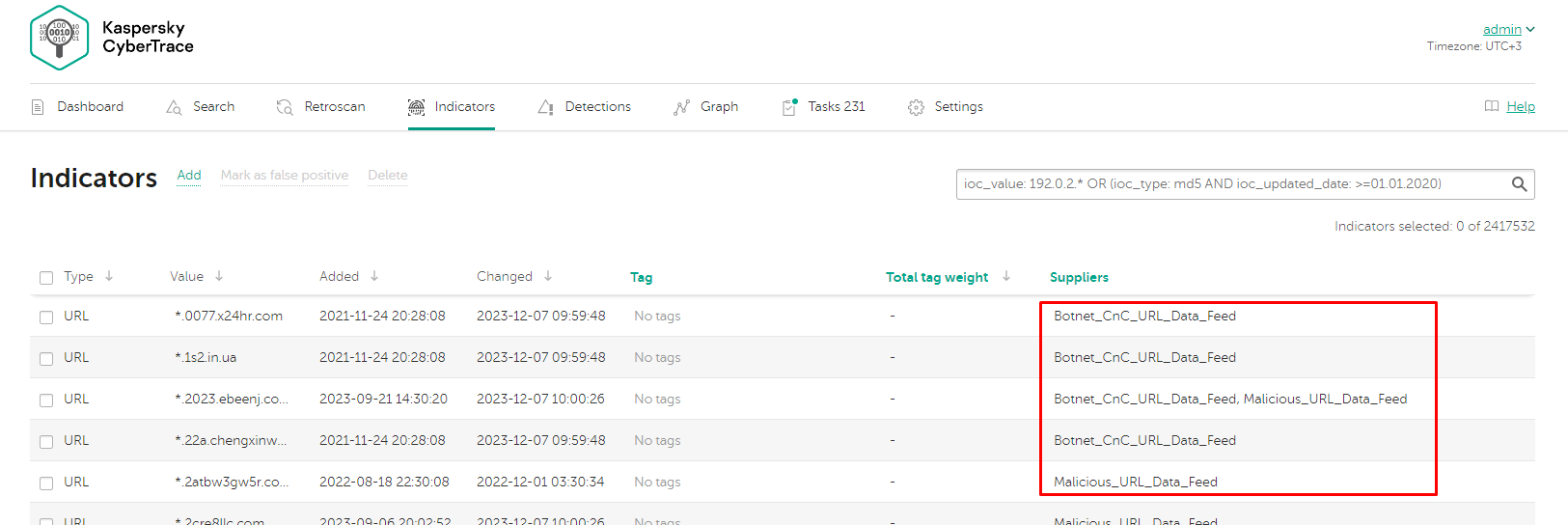
Работа с группами AD
Необходимо указывать полный DN, пример:
Условие фильтра:

Актив находится в определенной категории

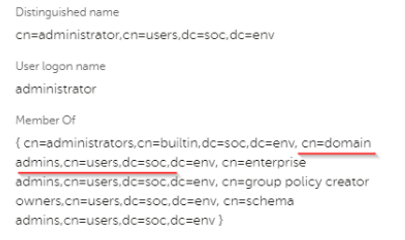
Работа с полем Extra в селекторе
Работа с полями типа SA (массив строк) KUMA 3.0+
При операции match к полям типа SA применяется как к строке, т.е. массив представляется в виде строки ["a1", "b2", "c3"] и т.д. Т.е. ко всему массиву сразу, а не к отдельным его элементам по очереди.
При операции contains применяется именно к элементам массива. Т.е. contains [ для массива вернет false, как и contains " или '. Но при этом же, если в массиве есть элемент abc, то contains abc вернет true и contains ab тоже вернет true
Работа с переменными (KUMA 2.1+)
Вход в рабочее время
Документация по функциям переменных (локальные переменные).
Сначала извлекается час из таймштемпа, с помощью функции: extract_from_timestamp(Timestamp, ‘h’, ‘Europe/Moscow’)
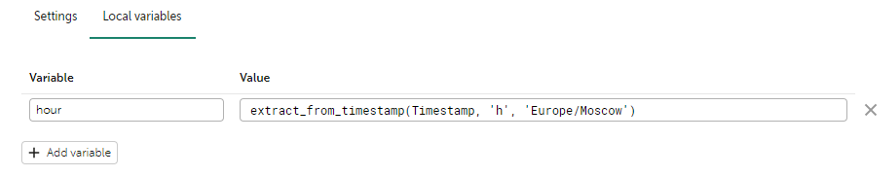
Условие в селекторе:
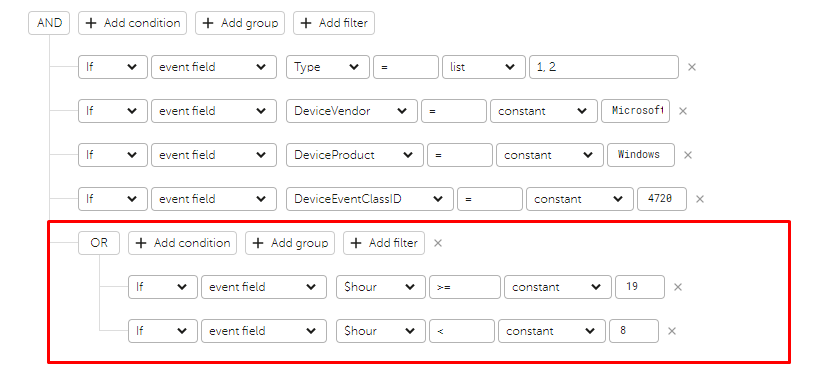
Переменные необходимо указывать в группирующих полях:

Работа с Extra
Здесь вместо Event.System.Channel нужно указать интересующее вас поле экстра. Регулярка: ."Event\.System\.Channel":"([^"]+)".

В некоторых случаях производительней использовать не регулярки, а функции:
- $firstIndex=index_of('(', fieldName)
- $lastIndex=index_of('.', fieldName)
- $getSubstring=substring(fieldName, $firstIndex, $lastIndex)
Работа с контекстной таблицей (KUMA 3.0+)
Исходная задача: Необходимо отслеживать, на каких отличных друг от друга устройствах производится вход одной УЗ. (активный лист будет менее удобен т.к. различных устройств может быть > 1)
Пример Контестной таблицы:
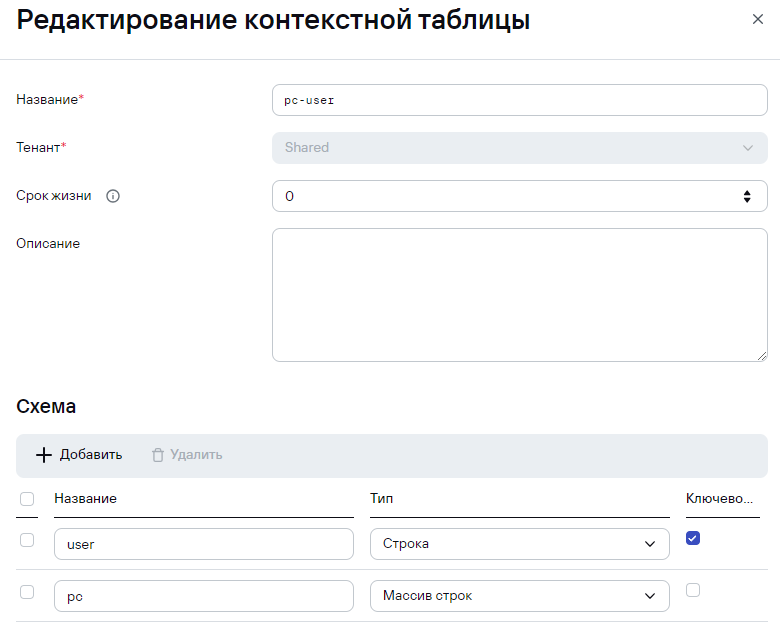
Примеры переменных:
Извлечение содержимого поля с массивом pc из контекстной таблицы в тенанте Shared (только для этого тенанта нужно в переменной это указывать) по ключевому полю user и его значением DestinationUserName, назовем переменную ct_value:
context_table('pc-user@Shared', 'pc', 'user', DestinationUserName)В событии выглядит это так:

Получение индекса (номер символа) по содержимому поля массива pc по значению поля DestinationHostName из контекстной таблицы в тенанте Shared (только для этого тенанта нужно в переменной это указывать) по ключевому полю user и его значением DestinationUserName, назовем переменную ct_contains:
index_of(DestinationHostName, $ct_value)Возвращает первую позицию символа или подстроки в строке, расчет индекса начинается с 0. Если в результате работы функции подстрока не была найдена, функция вернёт значение -9223372036854775808
Вот как выглядит это в событии, значение ct_contains в поле FlexNumber1.

Получение количества элементов в поле с массивом pc из контекстной таблицы (пример в собтии на рисунке выыше в поле FlexNumber2), назовем переменную ct_len:
len($ct_value)Если в содержимом поля с массивом pc из контекстной таблицы есть подстока см. выше описание переменной ct_contains, то вернуть true назовем переменную ct_item_exist:
conditional(`$ct_contains LIKE '-.*'`, 'false', 'true')Вот как выглядит это в событии, значение ct_item_exist в поле FlexString2.

Как записать значение из нескольких событий в одно поле в правиле корреляции типа Standard
В обогащении можнонаписать шаблон, в котором можно пройтись по всем подсобытиям и получить список всех полей. Дальше уже с помощью функционала Go template можете сделать что хотите. Для правильной работы метода keep event policy в правиле корреляции должна иметь значение all.
В данном примере можно получить в строку все значения SourceAddress из базовых событий через ";" в корреляционном событии.

На выходе получается примерно следующее

Тестирование правил корреляции (ретроскан)
Для тестирования правил можно использовать ретроскан (из раздела “События”), предварительно это правило нужно добавить в коррелятор и осуществить выборку интересующих событий запросом (выбрать временной диапазон):

В нашем случае, если правило сработает создастся алерт (можно отключить его создание по необходимости), заполнятся листы, если это есть в действиях правила корреляции. Также можно включить опцию запуска реагирования.
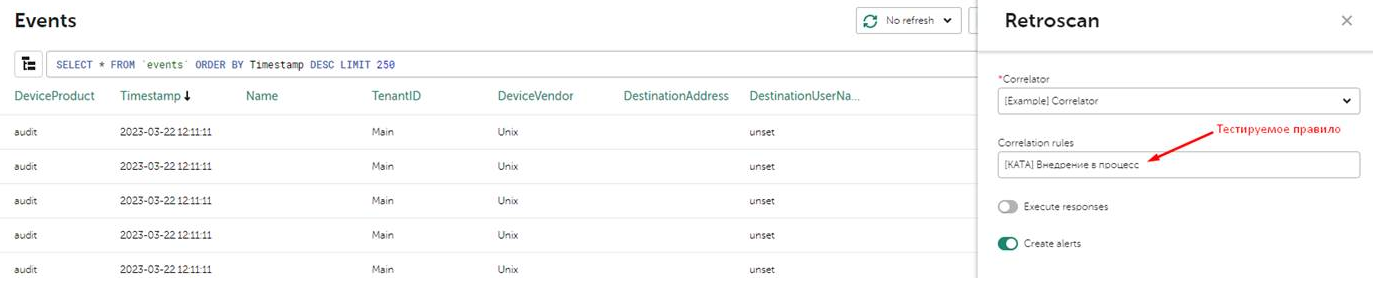
В случае отсутствия сработки попробуйте убрать LIMIT в SQL запросе при ретроскане
Производительность правил корреляции
Написание правил
В правилах корреляции очередность условий в селекторах имеет значение, НЕ актуально для Коррелятора 2.0 (Correlator-NG)
Уникальные условия надо поднимать вверх в правиле корреляции, чем раньше условие «провалится», тем лучше:


В случае несколльких селекторов, в начале лучше указать жесткое условие (например с "=") с полем из стандартной модели данных (не композитных полей S. или N. и т.д.), а затем условия где используются операторы contains или regex.
Операционные правила должны идти вначале:

Еще, например, есть правило, в котором в переменную кладется значение из активного листа, а затем эта переменная сравнивается в условии. Так вот в этом случае очередность условий имеет большое значение, так как поменяв условия местами и отодвинув проверку по активному листу в конец, в метриках количество OPS с активным листом уменьшилось со 100000 OPS до 1,1 OPS.
Все поля модели данных ищутся с одинаковой скоростью, а поля *Extra, S, SA, N, NA, F, FA работают медленнее
Значение переменной в селекторе высчитывается в момент, когда событие доходит до этого условия с переменной. Если переменная в группирующих полях, то переменная высчитывается после прохождения всех условий селектора.
При наличии условия с листами, словарями и т.д., отодвигайте их в конец.
Мониторинг произвоительности
Для мониторинга производительности по корреляции есть метрики, градации веса по операциям в продукте нет, все выполняется быстро благодаря GoLang. Метрики по правилам можно увидеть в разделе метрики, нажав на название “KUMA Collectors” затем выбрав “KUMA Correlators”:
Пример метрик по корреляции:
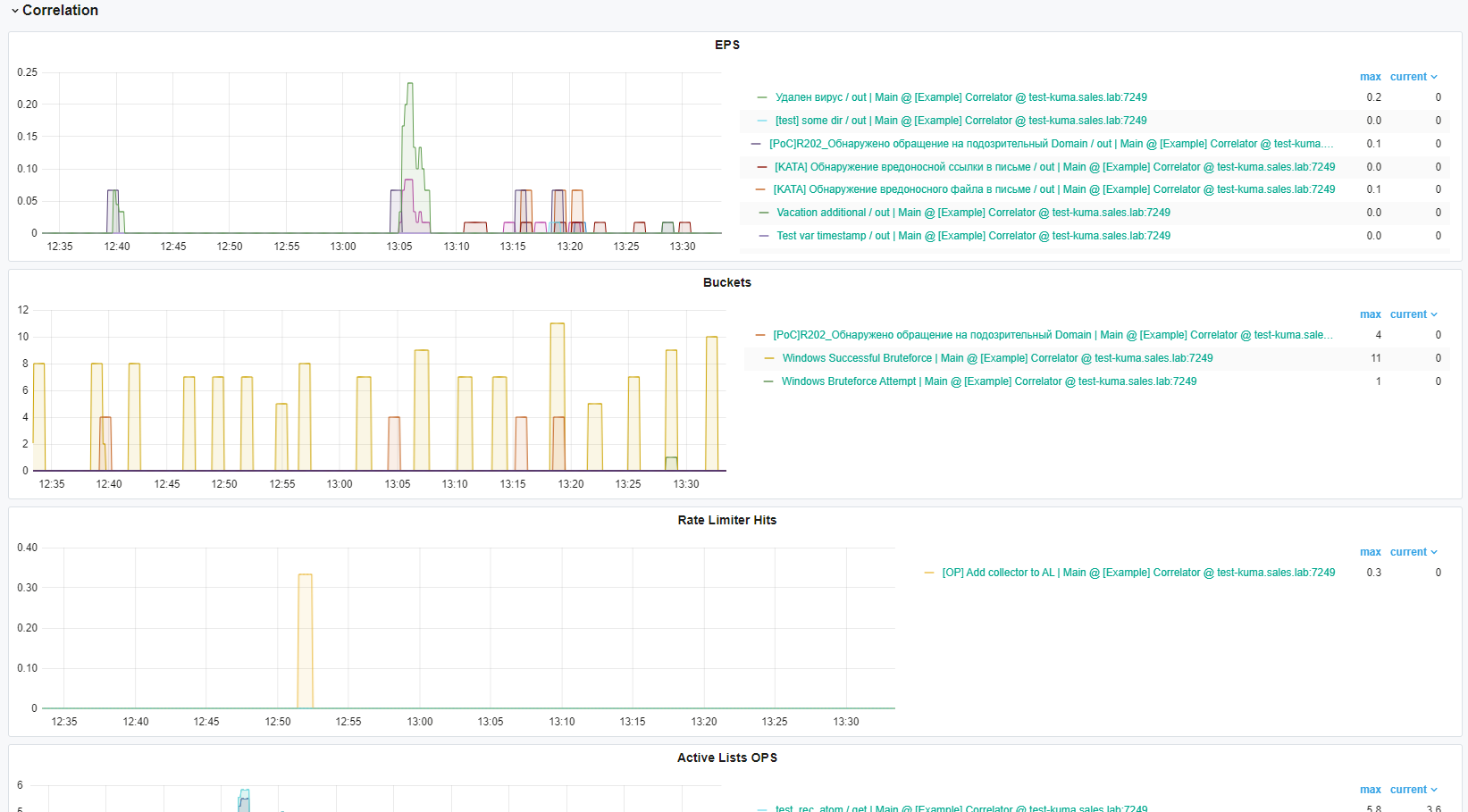
Сегментация правил корреляции
По умолчанию, если в корреляторе какое-то правило корреляции сработает несколько раз, все созданные в результате этого корреляционные события будут присоединены к одному алерту. Правила сегментации алертов дают возможность определить условия, при которых на основе таких однотипных корреляционных событий будут создаваться разные алерты.
Порядок применения правил сегментации соответсвует порядку правил сегментации созданным в интерфейсе KUMA (могут примениться и несколько сегментаций, если сработка правила корреляции соответствует нескольким правилам сегментации)
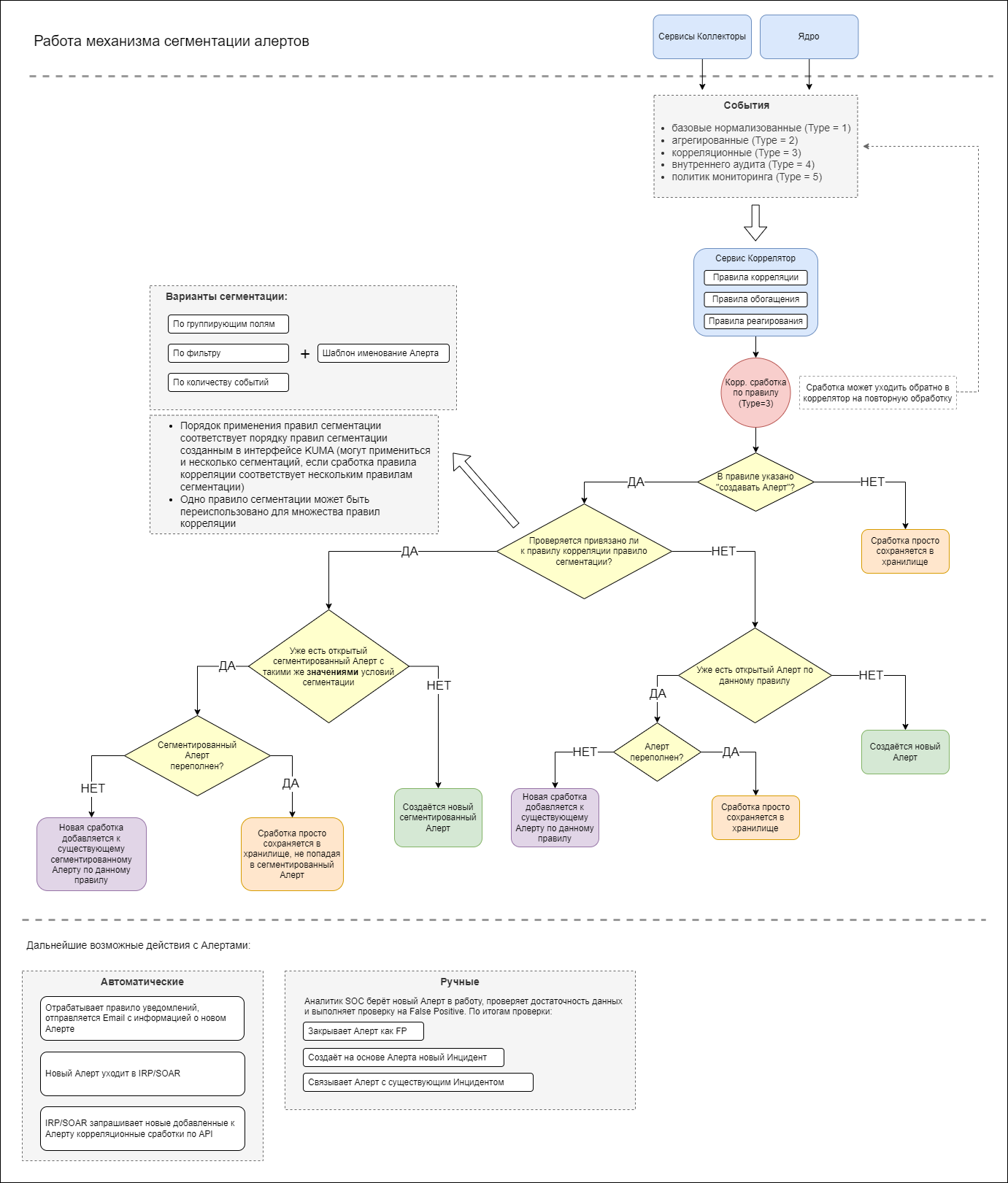
Блок-схема работы сегментации (спасибо за наработку интегратору):
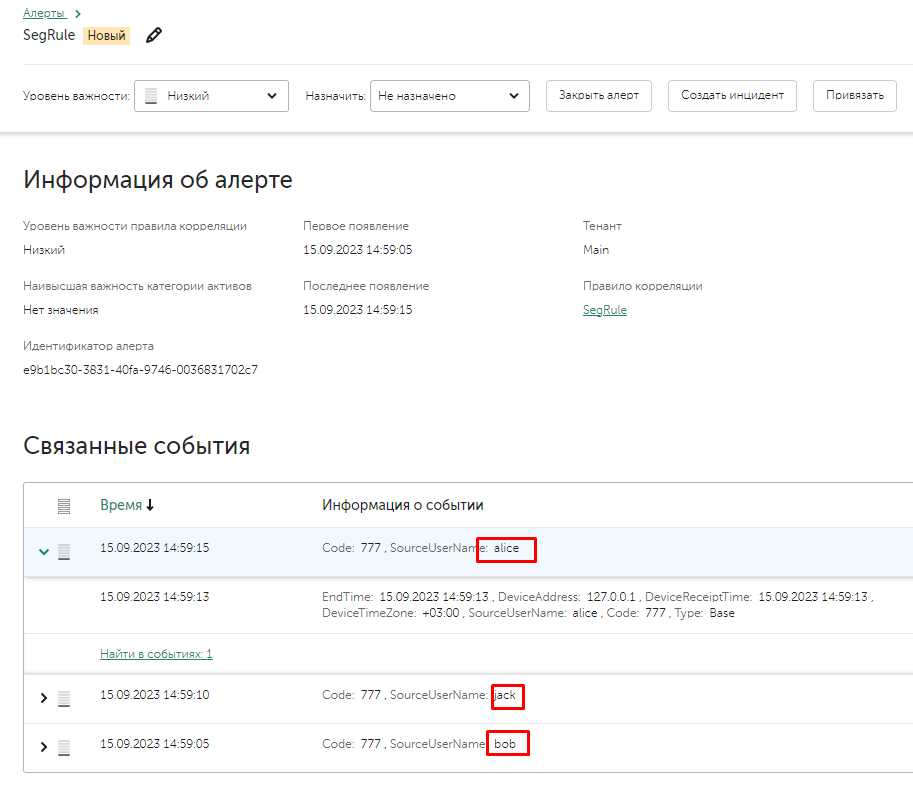
Пример работы, есть правило корреляции, которое срабатывает на событие с полем Code равное "777" с разными значениями SourceUserName, все сработки правила складываются в один Алерт, мы хотим создать отдельные алерты для отдельных пользователей:
Для этог онужно создать правило сегментации ипривязать его к правилу корреляции. Перейдите в Ресурсы - Правила сегментации и нажмите на кнопку Добавить правило сегментации. В нашем случае подойдет тип По группирующим полям:
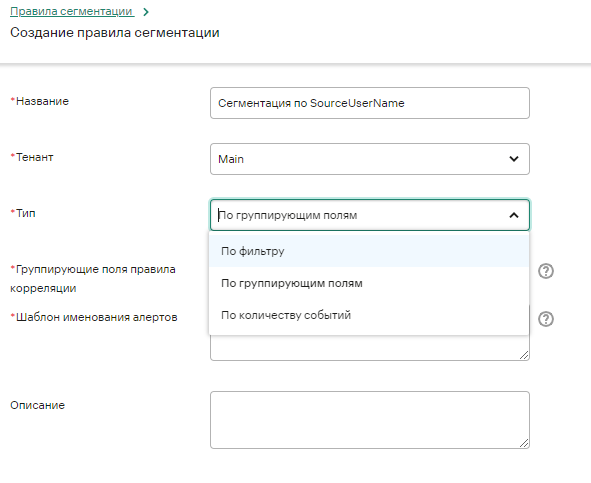
Указываем свой шаблон именования и группирующее поле - используем поля имени пользователя и Сохраняем:
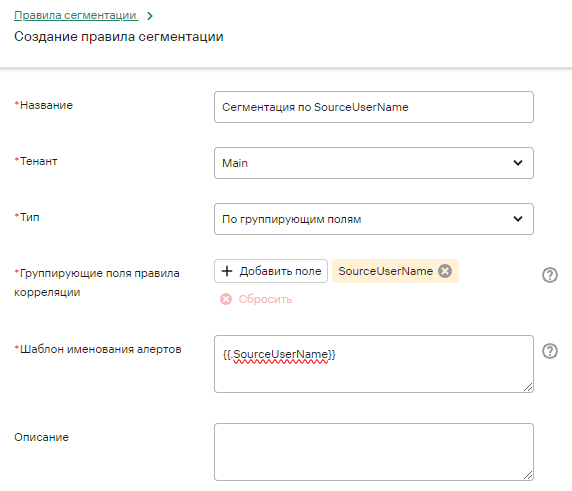
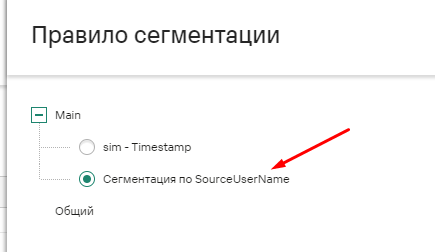
Далее необходимо привязать правило сегментации к нашему правилу корреляции. Это делается в Параметры - Алерты - вкладка Сегментация. Выбираем необходимый тенант, нажимаем кнопку Добавить, Указываем название, Выбираем правило корреляции и добавлем правило сегментации, затем на каждом шаге все Сохраняем.


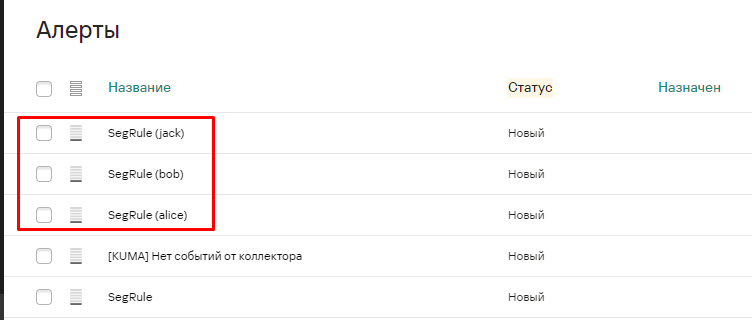
По итогу, при появлении событий удовлетворяющих правилу корреляции мы получим отдельные алерты на основе SourceUserName.
Аналогичным образом можно использовать и другие типы правил сегментации.
Правила сбора и анализа данных (Data Mining)
В отличие от потоковой корреляции, работающей в режиме реального времени, Data Mining правила позволяют с помощью языка SQL и функций ClickHouse (примеры запросов, почти все возможно использовать) распознавать и анализировать события, сохраненных в хранилище KUMA (можно указать и конкретный спейс хранилища).
Принцип работы
Выполнение SQL-запросов к ClickHouse и приведение результатов к формату нормализованных событий KUMA происходит на уровне Core с помощью новой сущности DataMiningRule и встроенного механизма Scheduler. Полученные результаты преобразуются в события и распространяются по корреляторам через стандартный API, который также используется коллекторами.
Важно, что:
- запрос к ClickHouse выполняется строго один раз за указанный период расписания;
- сформированный результат может быть направлен одному или нескольким корреляторам, а также в другие подсистемы в будущем;
- корреляторы, получающие данные, могут принадлежать различным тенантам, что обеспечивает гибкость и масштабируемость архитектуры.
Таким образом, Data Mining правила открывают возможность выявлять долгие и сложные цепочки активности - те, которые невозможно или крайне трудно обнаружить только средствами потоковой корреляции.
Преимущества и недостатки
| Плюсы | Минусы |
|
Снижение нагрузки на корреляторы — отсутствует необходимость хранить большие объёмы временных данных в оперативной памяти |
Увеличение нагрузки на хранилище данных, для которого постоянные сложные запросы не являются целевой нагрузкой. |
|
Кросстенантное обнаружение — правило может передавать результаты нескольким корреляторам разных тенантов. |
Риск тяжелых запросов — неэффективный SQL может существенно нагрузить кластер. |
|
Гибкость создания правил — возможность строить корреляцию напрямую на основе SQL-запросов. |
Отложенное обнаружение — аналитика работает постфактум, поэтому алерт приходит позже, чем при потоковой корреляции. |
|
Распределённое выполнение запросов — нагрузка обрабатывается кластером хранилища, а не одним сервером корреляции. |
|
|
Поддержка поиска аномалий и долгих сценариев атак — отклонения от нормы, тренды, девиации, редкие последовательности. |
|
|
Устойчивость к задержкам и несинхронности событий — если события приходят с опозданием или в неправильном порядке (например, правила по Golden Ticket), анализ всё равно будет корректным. |
|
|
Сохранность состояния при рестарте — бакеты и промежуточные данные не сбрасываются при перезагрузке коррелятора. |
Создание и настройка правила
Процесс создания правила можно разделить на три этапа:
1 этап. Создание непосредственно самого Data Mining правила
Создать правило можно двумя способами (из SQL-запроса в разделе Поиск по событиям):
- Формируем SQL-запрос в разделе Поиска по событиям (тестируем гипотезы, проводим атаку на полигоне, наполняем БД синтетическими событиями)
- Необходимо проверить что запрос выполняется, не вешает базу, возвращает осмысленный результат, который можно далее анализировать с помощью коррелятора
- Нажмите на значок "Create data mining rule"

- Далее открывается окно Создания правила, автоматически заполнится сам запрос, глубина и частота запуска. Заполнится маппинг полей из запроса в поля KUMA

- Здесь необходимо вписать название, выбрать тенант, дозаполнить поля и создать правило.
Второй способ (создать правило как ресурс):
- В Ресурсах - Правила сбора и анализа данных Создать правило

- В правиле указать:
-
- Интервал (частота) выполнения SQL-запроса можно указать в минутах, часах и днях (минимум 1 минута)
- SQL-запрос должен содержать функцию агрегации (примеры) и/или группировку (GROUP BY) данных c обязательным указанием ограничения LIMIT (от 1 до 10 000)
Каждое выполнение такого правила происходит в виде запроса в Хранилище, а это значит неосторожным движением в виде частого или тяжелого правила можно нагрузить базу больше чем хотелось бы
В примере рассматривается запрос на основе событий Windows по пользователям (DestinationUserName) событиям входа (EventID 4624) и выхода (EventID 4634) с расчетом среднего времени сесии пользователя за последние 24 часа.
Посмотреть SQL запрос (пример)
SELECT
login_events.DestinationUserName AS destination_user_name,
round(AVG(logout_events.logout_time - login_events.login_time)/1000) AS avg_time_diff_s,
COUNT(DISTINCT login_events.login_time) AS total_logins,
COUNT(DISTINCT logout_events.logout_time) AS total_logouts,
concat(
toString(floor(avg_time_diff_s / 86400)), ' days, ',
toString(floor((avg_time_diff_s % 86400) / 3600)), ' hours, ',
toString(floor((avg_time_diff_s % 3600) / 60)), ' minutes, ',
toString(avg_time_diff_s % 60), ' seconds'
) AS human_readable_diff
FROM
(SELECT
DestinationUserName,
toUnixTimestamp(EndTime) AS login_time,
FlexString1 AS logon_id
FROM `events`
WHERE DeviceEventClassID = '4624'
AND EndTime >= now() - INTERVAL 24 HOUR
AND DestinationUserName NOT LIKE '%$%') AS login_events
INNER JOIN
(SELECT
DestinationUserName,
toUnixTimestamp(EndTime) AS logout_time,
FlexString1 AS logon_id
FROM `events`
WHERE DeviceEventClassID = '4634'
AND EndTime >= now() - INTERVAL 24 HOUR
AND DestinationUserName NOT LIKE '%$%') AS logout_events
ON login_events.DestinationUserName = logout_events.DestinationUserName
AND logout_events.logon_id = login_events.logon_id
WHERE logout_events.logout_time >= login_events.login_time
GROUP BY login_events.DestinationUserName
ORDER BY avg_time_diff_s DESC
LIMIT 100-
- Добавить маппинг (сопоставление) по полям запроса и модели KUMA

2 этап. Создание планировщика
- Перейти в раздел Ресурсы - Сбор и анализ данных добавить планировщик по ранее созданному правилу
- Открыть правило и установить связи:
- Привязать хранилище по которому будет осуществляться поиск на вкладке Привязанные хранилища
- Привязать коррелятор с соответвующим правилом корреляции для сработки на вкладке Привязанные корреляторы
- Для ручного запуска нажмите кнопку Запустить

- По результатам запроса на выходе будут сформированы базовые события, которые не будут сохранены. Далее необходимо создать простое правило корреляции, чтобы создать корреляционное событие и алерт на данное событие и привязать правило к нужным корреляторам
3 этап Создание simple правила на результат
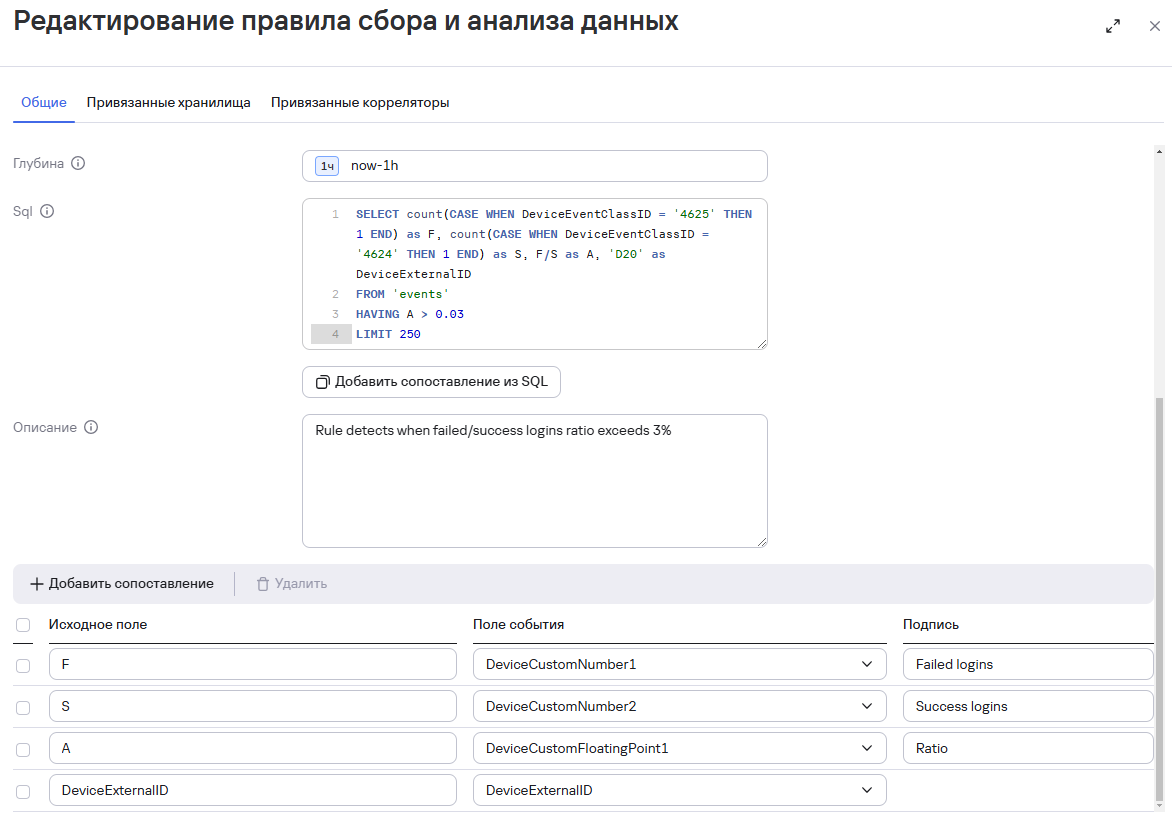
В нашем случае правило ловит события, где время сессии меньше 5 секунд:

Корреляционное событие выглядит следующим образом:

А событие на основе которого произошла сработка:

Еще пример:
Работу правил можно отслеживать с помощью метрик в разделе KUMA Core:

Кейсы использования правил
Использование Data Mining правил особенно актуально в ситуациях, когда классическая потоковая корреляция либо неэффективна, либо слишком ресурсоёмка. Рассмотрим основные практические сценарии:
- Когда нужно обработать много событий за период
Например, большое число неуспешных логинов за 5 минут или массовое сканирование портов.
Data Mining позволяет считать такие вещи в ClickHouse, не загружая корреляторы. - Когда нужно суммировать или усреднять значения
Можно использовать агрегирующие функции SQL:SUM(),AVG()и т.д.
Пример: средний объём исходящего трафика или количество DNS-запросов.
Алерт срабатывает при превышении порога. - Когда нужен сравнительный анализ
Например, сравнить количество событий за последний час с таким же периодом сутки назад. - Когда нужно работать со “скользящим” окном времени
Анализировать события за период, независимо от того, с какой задержкой они пришли. - Операции которые невозможны на уровне цепочки событий (Количественный прирост, анализ на схожесть, а не на одинаковость)
- Подсчет энтропии
Определение при помощи энтропии, какие хосты генерируют одни и те же сработки для формирования исключений (рандомность, неожиданность цепочки)
Описание кейсов
Рассмотрим более подробно на парочке примеров:
1. Частые неуспешные попытки входа
Корреляционная логика, при которой требуется длительное накопление событий. Например:
- более 10 неуспешных попыток аутентификации под пользователем
root - Берём окно поиска 15 минут и запускаем правило каждые 14 минут.
- Так мы анализируем накопившиеся события и получаем результат без необходимости хранить все данные в памяти коррелятора.

Частые неуспешные попытки входа под УЗ root
SELECT
SourceAddress,
SourceHostName,
DestinationUserName,
min(Timestamp) as StartTime,
max(Timestamp) as EndTime,
count(Distinct(DestinationServiceName)) as cnt_spn_names,
arrayCompact(groupUniqArray(DestinationServiceName)) as spn_names,
arrayStringConcat(
arrayMap(x -> '\'' || x || '\'', groupUniqArray(Distinct(ID))),
', '
) AS BaseEventIDs,
Count(*) as EventIDsCount,
'SOCSh_Kerberoasting' as exID
FROM 'events'
WHERE
DeviceEventClassID = '4769' AND SourceUserID != '' AND NOT ( SourceAddress in ('','::1') or SourceAddress like '127.0.0.%') AND NOT endsWith(DestinationUserName,'$')
GROUP BY SourceAddress, SourceHostName, DestinationUserName
HAVING cnt_spn_names > 10
LIMIT 1002. Подсчёт исходящего сетевого трафика
Простой пример, где нужно суммировать данные и обнаруживать превышение порога.
- Суммируем исходящий трафик (
SUM(bytes_out)) и группируем по адресу источника. - В поле «Глубина» оставляем пусто — тогда нижняя граница интервала определяется автоматически как конец предыдущего запроса + 1.
- В поле «Частота запуска» ставим минимальное значение — 1 минута.

В результате Scheduler каждую минуту запускает SQL-запрос с небольшим окном данных. Получается скользящее окно, которое постоянно обновляется и позволяет корректно работать даже при задержках в доставке событий и нарушении их порядка. Это как раз тот случай, когда Data Mining правила способны сделать то, с чем потоковая корреляция справиться не может.
Примеры готовых правил
1. Массовый перебор TGS билетов (Kerberoasting)
Kerberoasting
SELECT
SourceAddress,
SourceHostName,
DestinationUserName,
min(Timestamp) as StartTime,
max(Timestamp) as EndTime,
count(Distinct(DestinationServiceName)) as cnt_spn_names,
arrayCompact(groupUniqArray(DestinationServiceName)) as spn_names,
arrayStringConcat(
arrayMap(x -> '\'' || x || '\'', groupUniqArray(Distinct(ID))),
', '
) AS BaseEventIDs,
Count(*) as EventIDsCount,
'SOCSh_Kerberoasting' as exID
FROM 'events'
WHERE
DeviceEventClassID = '4769' AND SourceUserID != '' AND NOT ( SourceAddress in ('','::1') or SourceAddress like '127.0.0.%') AND NOT endsWith(DestinationUserName,'$')
GROUP BY SourceAddress, SourceHostName, DestinationUserName
HAVING cnt_spn_names > 10
LIMIT 1002. Сканирование портов и сканирование хостов (сетевые события)
Сканирование портов
SELECT
arrayStringConcat(arraySort(groupUniqArray(Distinct(DeviceProduct))), ', ' ) AS DeviceProduct,
arrayStringConcat(arraySort(groupUniqArray(Distinct(DeviceAddress))), ', ' ) AS DeviceAddresses,
SourceAddress,
SourceHostName,
SourceNtDomain,
DestinationAddress,
min(Timestamp) as StartTime,
max(Timestamp) as EndTime,
arrayStringConcat(arraySort(groupUniqArray(Distinct(DestinationPort))), ', ' ) AS DeviceCustomString1,
arrayStringConcat(
arrayMap(x -> '\'' || x || '\'', groupUniqArray(Distinct(ID))),
', '
) AS DeviceCustomString2,
Count(*) as DeviceCustomNumber2,
Count(Distinct(DestinationPort)) as DeviceCustomNumber1,
'SOCSh_ScanPort' as exID
FROM `events`
WHERE
Type=1 and
(DestinationPort < 1024 or DestinationPort in (1434,1521,3306,3389,5432,8080,9200,1352,1540,1541)) AND
SourcePort>1024 and DestinationPort!=0 and SourceAddress!='' and DestinationAddress!='' AND
(isIPAddressInRange(SourceAddress, '192.168.0.0/16') or isIPAddressInRange(SourceAddress, '10.0.0.0/8') or isIPAddressInRange(SourceAddress, '172.16.0.0/12')) AND
(isIPAddressInRange(DestinationAddress, '192.168.0.0/16') or isIPAddressInRange(DestinationAddress, '10.0.0.0/8') or isIPAddressInRange(DestinationAddress, '172.16.0.0/12'))
GROUP BY SourceAddress,SourceHostName,SourceNtDomain,DestinationAddress
HAVING DeviceCustomNumber1>=10
LIMIT 1003. Прирост корреляционных событий (Обнаружение отклонений)
Прирост корреляционных событий более 20% за сутки
SELECT
'CorrelationSplash' as ExternalId,
TenantID,
CorrelationRuleID,
CorrelationRuleName,
countIf(Timestamp between toUnixTimestamp64Milli(now64()) - 1*3600000 and toUnixTimestamp64Milli(now64())) as today,
countIf(Timestamp between toUnixTimestamp64Milli(now64()) - 25*3600000 and toUnixTimestamp64Milli(now64())-24*3600000) as yesterday,
round(today/yesterday,2) as k
FROM `events`
WHERE Type=3 and toDayOfWeek(now64())!=1
GROUP BY TenantID,CorrelationRuleID,CorrelationRuleName
HAVING yesterday > 20 and k>1.2
LIMIT 2504. Распыление/подбор паролей
SQL запрос правила Password Spraying
SELECT
SourceAddress, SourceHostName,
min(Timestamp) as StartTime, max(Timestamp) as EndTime,
count(Distinct(DestinationUserName)) as cnt_usernames, /*кол-во уникальных УЗ*/
arrayCompact(groupUniqArray(DestinationUserName)) as spray_usernames, /*уникальные сортированные имена УЗ, склеенные в строку*/
arrayStringConcat(arrayMap(x -> '\'' || x || '\'', groupUniqArray(Distinct(ID))),', ') as BaseEventIDs, /*уникальные сортированные ID базовых событий, склеенные в строку*/
Count(*) as EventIDsCount,
'SOCSh_PasswordSpray' as exID
FROM
'events'
WHERE
DeviceEventClassID = '4625'
AND DestinationNtDomain != ''
AND NOT endsWith(DestinationUserName,'$')
GROUP BY SourceAddress, SourceHostName
HAVING cnt_usernames > 10
LIMIT 100

SQL запрос правила Password Spraying с сохранением имен пользователей успешного и неудачного логина
SELECT
SourceAddress, SourceHostName, StartTime, EndTime,failure_logins,success_logins,failed_usernames,success_usernames,exID
FROM (
SELECT
SourceAddress, SourceHostName, min(Timestamp) as StartTime, max(Timestamp) as EndTime,
countIf(DeviceEventClassID = '4625') AS failure_logins,
countIf(DeviceEventClassID = '4624') AS success_logins,
arrayCompact(groupUniqArrayIf(DestinationUserName, DeviceEventClassID = '4625')) AS failed_usernames,
arrayCompact(groupUniqArrayIf(DestinationUserName, DeviceEventClassID = '4624')) AS success_usernames,
'SOCSh_PasswordSpray' as exID
FROM events
WHERE
DeviceEventClassID IN ('4625', '4624')
AND DestinationNtDomain != ''
AND NOT endsWith(DestinationUserName,'$')
GROUP BY SourceAddress, SourceHostName)
WHERE failure_logins > 10
LIMIT 100

6. Подсчет энтропии для определения исключений.
Запрос на Подсчет энтропии, который может помочь для определения и внесения исключений в правила корреляции.
Если очень грубо, энтропия это показатель случайности и чем она ниже - тем ниже случайности попадания источника DeviceAddress в корреляционное событие
Иными словами, можно определить, какие одни и те же хосты попадают в одни и те же алерты на постоянной основе и после проверки внести их в исключения
Подсчет энтропии для определения исключений
SELECT
CorrelationRuleID,
CorrelationRuleName,
entropy(DeviceAddress) as entr, /*"показатель случайности" попадающих DeviceAddress. Чем ниже - тем меньше случайности*/
count(*) as cnt, /*объем выборки энтропии (маленькая выборка не информативна)*/
count(distinct(DeviceAddress)) as hosts, /*количество уникальных DeviceAddress*/
'SOCSh_Entropy'as ExternalID
FROM events
WHERE Type=3 /*корр. события*/
GROUP BY CorrelationRuleID, CorrelationRuleName
HAVING
hosts > 1 and /*хостов в результате больше 1 (иначе о энтропии речи быть не может)*/
cnt > 10 /*количество событий достаточно для оптимальной оценки*/
ORDER BY entr ASC /*сортируем по принципу "наименее случайные последовательности"*/
LIMIT 250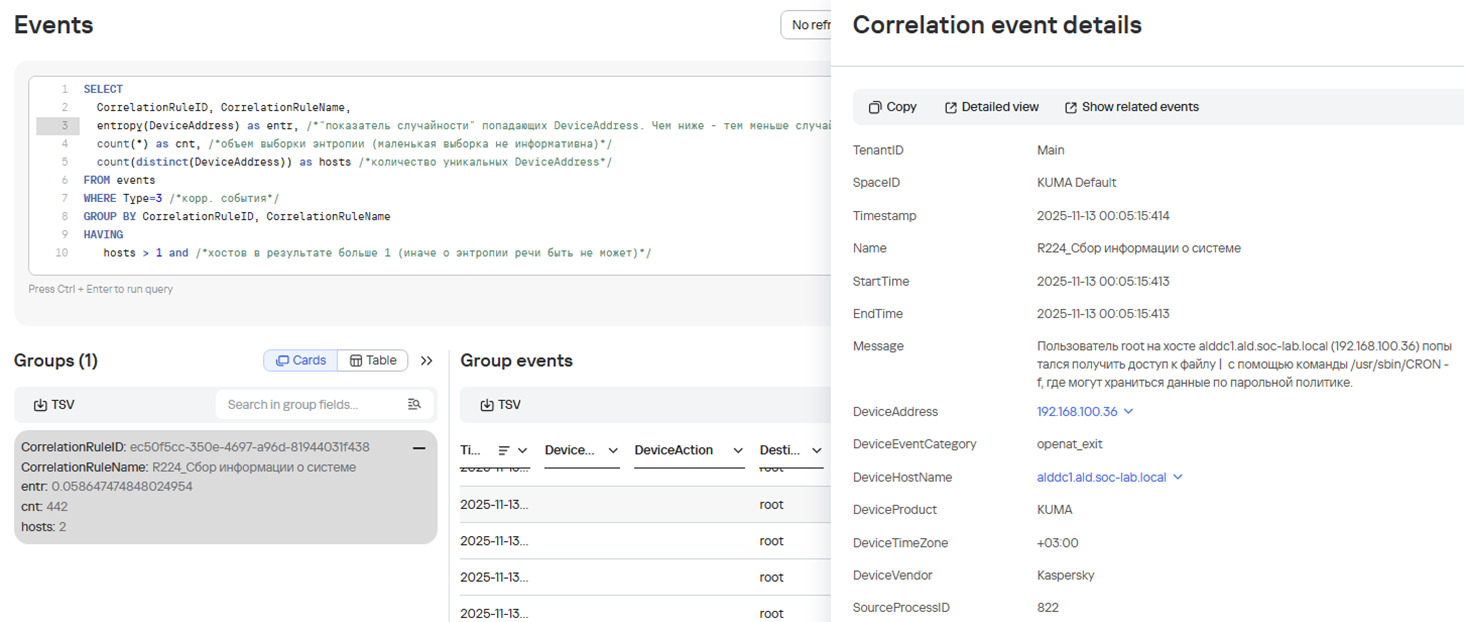
А также другие примеры:
- Скачок событий/алертов со средств защиты
- Большое количество DNS запросов с хоста
Пакет ресурсов Data Mining правил: Shared_20251113_231513_DMRules
Пароль к ресурсу: !QAZ2wsx#EDC_!QAZ2wsx#EDC_
Часто используемые функции SQL и лайфхаки
Здесь перечислены самые часто встречающиеся функции, которые используются в запросах:
-
arrayStringConcat- объединяет элементы массива в строку -
arrayCompact- удаляет последовательные дублирующиеся элементы из массива -
distinct- уникальные значения -
groupUniqArray- собирает значения в массив -
arraySort- сортирует массив -
arrayMap- применяет выражение к каждому элементу массива и возвращает новый массив с результатами
Возможно использовать все функции, описанные в документации ClickHouse: https://clickhouse.com/docs/ru/sql-reference/functions
А также набор специальных функций enrich и lookup в KUMA: https://support.kaspersky.com/help/KUMA/4.0/ru-RU/294927.htm
Например:
1. Уникальные отсортированные имена пользователей, склеенные в строку.
arrayCompact(arraySort(groupUniqArray(DestinationUserName)))
2. Уникальные ID базовых событий, склеенные в строку
arrayStringConcat( arrayMap(x -> '\'' || x || '\'', groupUniqArray(Distinct(ID))), ', ') AS BaseEventIDs
Конвертер правил Sigma
Информация, приведенная на данной странице, является разработкой команды pre-sales и/или community KUMA и НЕ является официальной рекомендацией вендора.
Официальная документация по данному разделу приведена в Онлайн-справке на продукт: https://support.kaspersky.com/help/kuma/4.0/ru-RU/296337.htm
Поддерживаемые примеры конвертации правил Sigma тут
Конвертер правил Sigma преобразует правила корреляции в понятный KUMA формат и облегчает импорт простых правил для последующей доработки аналитиком.
Разворачивание конвертера правил Sigma
- Установите конвертер правил Sigma. Для этого распайкуйте архив kuma-sigma-converter-x.x.x.tr.gz в папке установщика и после перейдите в распакованную директорию.
Установку можно произвести на отдельной машине
Для работы необходим установленный Docker на ОС. Документация: https://docs.docker.com/engine/install/
tar -xf kuma-sigma-converter-0.1.0.tar.gz && cd kuma-sigma-converter-0.1.0/
далее запускаем файл командой
./run.sh
После установки конвертера необходимо перейти в веб-интерфейс в браузере по адресу
<IP_сервера>:<порт>Работа с конвертером правил Sigma

Тут уже видим, как форматируется sigma-rule в запрос, читаемый KUMA.
Но для дополнительной демонстрации возьмем еще правило и доработаем его, вставим правило во вкладку конвертера "rule"
В поле backend выберите kuma, в поле Format выберите default, поле pipeline оставьте пустым. При необходимости нужно исправить ошибки в rule.yaml

Поскольку в предустановленных нормализаторах используется обогащение событий to lower case для полей, содержащих имена пользователей, имена хостов, имена процессов, мы рекомендуем в исходном правиле Sigma приводить соответствующие поля к нижнему регистру, иначе придется корректировать правило в KUMA.
Мы не рекомендуем в условиях contains и подобных условиях писать комментарии или дополнительную информацию. В случае необходимости оставить комментарий рекомендуем использовать символ #, тогда комментарий не окажет влияния на условие.
Правило должно начинаться со слова title, дефисов перед ним не должно быть.
3. Готовый результат из query скопируйте в KUMA. В результате получим условие WHERE для sql запроса.

Проверим и вставим запрос для фильтраций событий в KUMA:

Видим события, связанные с данным фильтром.
Примеры для теста:
- https://detection.fyi/sigmahq/sigma/windows/process_creation/proc_creation_win_conhost_susp_winshell_child_process/
- https://detection.fyi/sigmahq/sigma/windows/process_creation/proc_creation_win_conhost_susp_winshell_child_process/