Развернутые ответы на вопросы
В данном разделе находятся ответы на вопросы по KUMA, которые сложно уместить в одно предложение
- Что такое SIEM и Приоритет подачи журналов в SIEM
- Схема сетевого взаимодействия KUMA (Архитектура)
- Модель лицензирования KUMA (Licensing)
- Типы хранения данных в KUMA
- Первичный Траблшут в KUMA (Troubleshoot)
- Описание процесса работы c инцидентами в KUMA
- Как использовать MITRE ATT&CK в SOC
- Как слушать коллектором порты меньше 1024
- Где брать официальный контент для KUMA? (Обновление контента)
- Форматы времени, которые понимает KUMA
- Как перенести KUMA на другой диск
- Лайфхаки для шаблонов
- Замена сертификата (веб - интерфейсе) KUMA
- Настройка мониторинга источников с алертом
- Аудит изменений по активам
- Тенанты в KUMA (Multitenancy)
- Описание метрик в KUMA
- Как узнать связи между ресурсами KUMA
- Устройство кластера хранилища
- Как расширить диск с данными KUMA в случае с lvm
- Продление сессии пользователя для режима ТВ (TV-mode)
- Как определить средний размер события
- Cканер уязвимостей ADPulse DC
Что такое SIEM и Приоритет подачи журналов в SIEM
Вводная SIEM

- Получение данных с различных уровней сети
- Централизованное хранение и просмотр различных данных в нормализованном виде
- Кросс-корреляцию данных

Сценарий применений SIEM
- Предпроектное обследование (сбор информации об источниках, инфраструктуре), составление модели угроз, разработка сценариев выявления
- Развёртывание и первоначальная настройка Подключение источников событий, интеграция с продуктами для реагирования и обогащения
- Доработка и адаптация правил корреляции, дашбордов, отчётов
- Инвентаризация и категоризация активов, групп пользователей
- Штатная работа с системой (мониторинг безопасности, реагирование на инциденты, Threat Hunting)
- [по мере необходимости] Подключение новых источников, обновление коннекторов, правил корреляции
- [на регулярной основе] Оценка эффективности и актуализация сценариев выявления и правил корреляции
- Остальные юзкейсы будут на этой странице (в разработке)
Эффективное логирование направлено на:

Хранение журнала событий
Сроки хранения журналов должны быть основаны на оценке рисков для данной системы. При оценке рисков для системы следует учитывать, что в некоторых случаях может потребоваться до 18 месяцев, чтобы обнаружить инцидент кибербезопасности, а некоторые вредоносные программы могут находиться в сети от 70 до 200 дней, прежде чем нанести явный вред.
Сроки хранения журналов также должны соответствовать любым нормативным требованиям и структурам кибербезопасности, которые могут применяться в юрисдикции организации. Журналы, которые имеют решающее значение для подтверждения вторжения и его последствий, должны быть приоритетными для более длительного хранения.
Приоритет журналов систем к подаче в SIEM
- Периметровые/Пограничные решения (External facing Systems): VPN порталы, WEB сервера, терминалы, точки доступа, роутеры и др.
- Системы информационной безопасности (Security Devices): МЭ, IPS/IDS, Email защита, NGFW, Антивирусная защита, EDR, WAF и др.
- Системы аутентификации (Authentication Systems): PAM, MFA, LDAP/FreeIPA, RADIUS, CA Systems, SAML, AD и др.
- SaaS приложения/ПО как услуга (SaaS Apps): Slack, Cloudflare, Microsoft Azure Active Directory, Zscaler и др.
- Системы под управлением ОС Windows (Windows Systems): Сервера (AD, MS SQL,Exchange, DNS, DHCP, SCCM, WSUS, и др.), Рабочие станции и др.
- Системы под управлением ОС Linux (Linux Systems): apache, nginx, mysql, fail2ban, bind, samba, exim, squid, postgres и др.
- Сетевые устройства (Network Devices): Маршрутизаторы (Netflow полезно), коммутаторы, мосты, Wi-Fi, модемы, концентраторы и др.
- Системы виртуализации (Virtualization Systems): VMware, Citrix, Hyper-V, KVM, ProxMox и др.
- Внутренние системы (Internal Systems): Процессинг, Бизнес-приложения и др.
- Управления и работа с мобильными устройствами (Mobile Devices): MDM, EMM, UEM и др.
- Системы хранения данных и СРК (Storage/Backup Systems): DELL EMC, HP 3PAR, NetApp, Veeam, CommVault и др.
- Узкоспециализированное ПО (COT: commercial off-the-shelf): Собственные приложения, The Microsoft Office, Adobe Photoshop, SAP и др.
Подход для корпоративных сетей на основе рисков
- Критические системы и хранилища данных, которые, вероятно, будут атакованы;
- Интернет-сервисы, включая удаленный доступ к ним, сетевые метаданные и их ОС;
серверы управления идентификацией и доменами; - Любые другие критические серверы;
- Пограничные устройства, такие как граничные маршрутизаторы и фаерволы;
- Административные рабочие станции;
- Высокопривилегированные системы, такие как управление конфигурацией, мониторинг производительности и доступности (в случаях, когда используется привилегированный доступ), CI/CD, службы сканирования уязвимостей, управление секретами и привилегиями;
- Хранилища данных;
- Системы связанные с ИБ и критически важное ПО;
- Пользовательские компьютеры;
- Журналы пользовательских приложений;
- Веб-прокси, используемые пользователями организации и сервисные учетные записи;
- DNS-сервисы (используемые пользователями организации), серверы электронной почты, серверы DHCP;
- Устаревшие ИТ-активы (которые ранее не были зафиксированы в критических или интернет-сервисах).
- Журналы с более низким приоритетом:
- Базовая инфраструктура, например, хосты гипервизора;
- ИТ-устройства, например, принтеры
- Сетевые активы, например, шлюзы приложений.
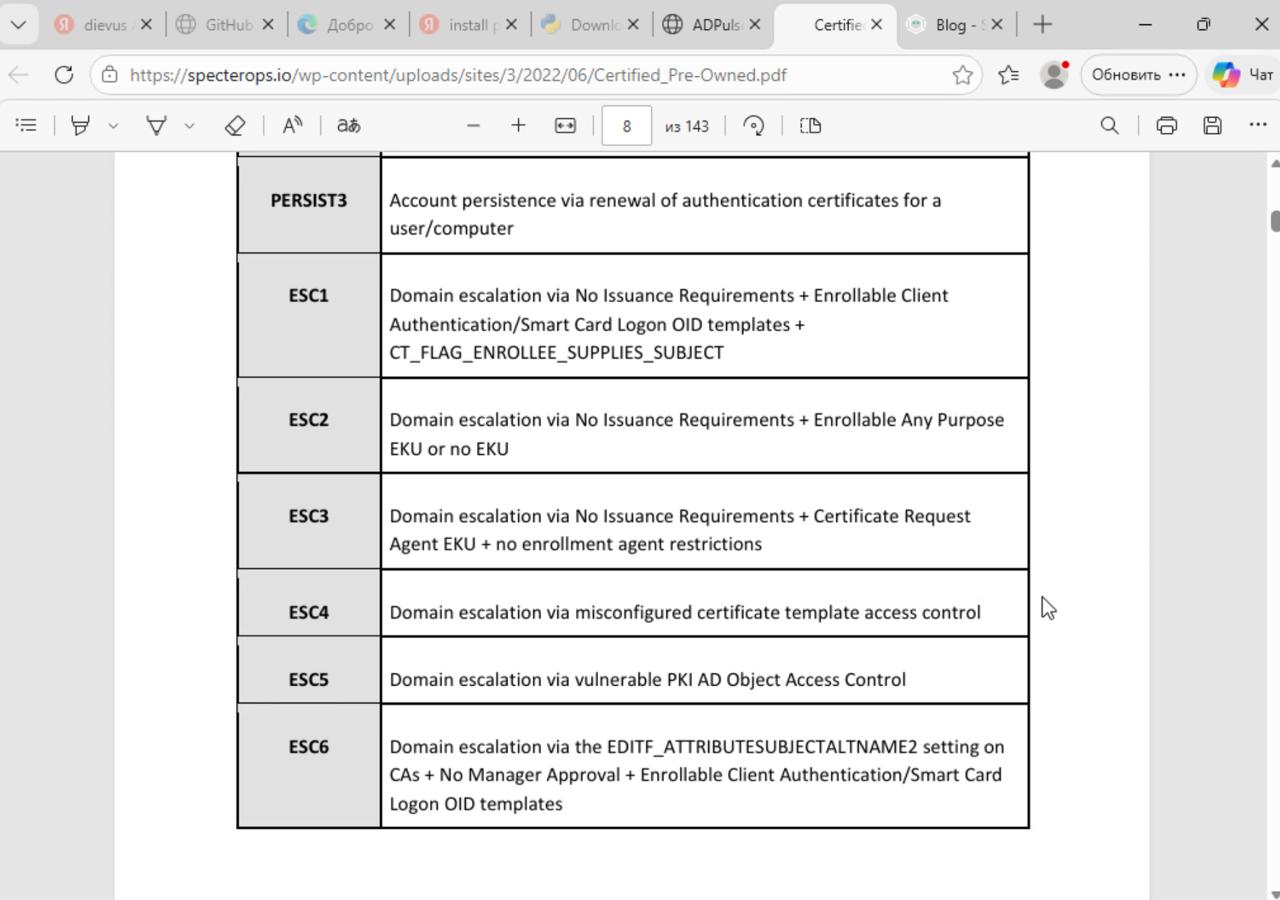
Схема сетевого взаимодействия KUMA (Архитектура)
Информация, приведенная на данной странице, является разработкой команды pre-sales и/или community KUMA и НЕ является официальной рекомендацией вендора.
Полная таблица доступов по портам (используемые порты) KUMA: https://support.kaspersky.ru/kuma/4.2/217770
Между шардами (при отсутствии реплик) кластера хранилища необходимо также открывать порт 9000, несмотря на то, что это не указано в таблице документации
Схема (хранилище представлено с двумя репликами, т.е. с копией данных):
KUMA до 4.0
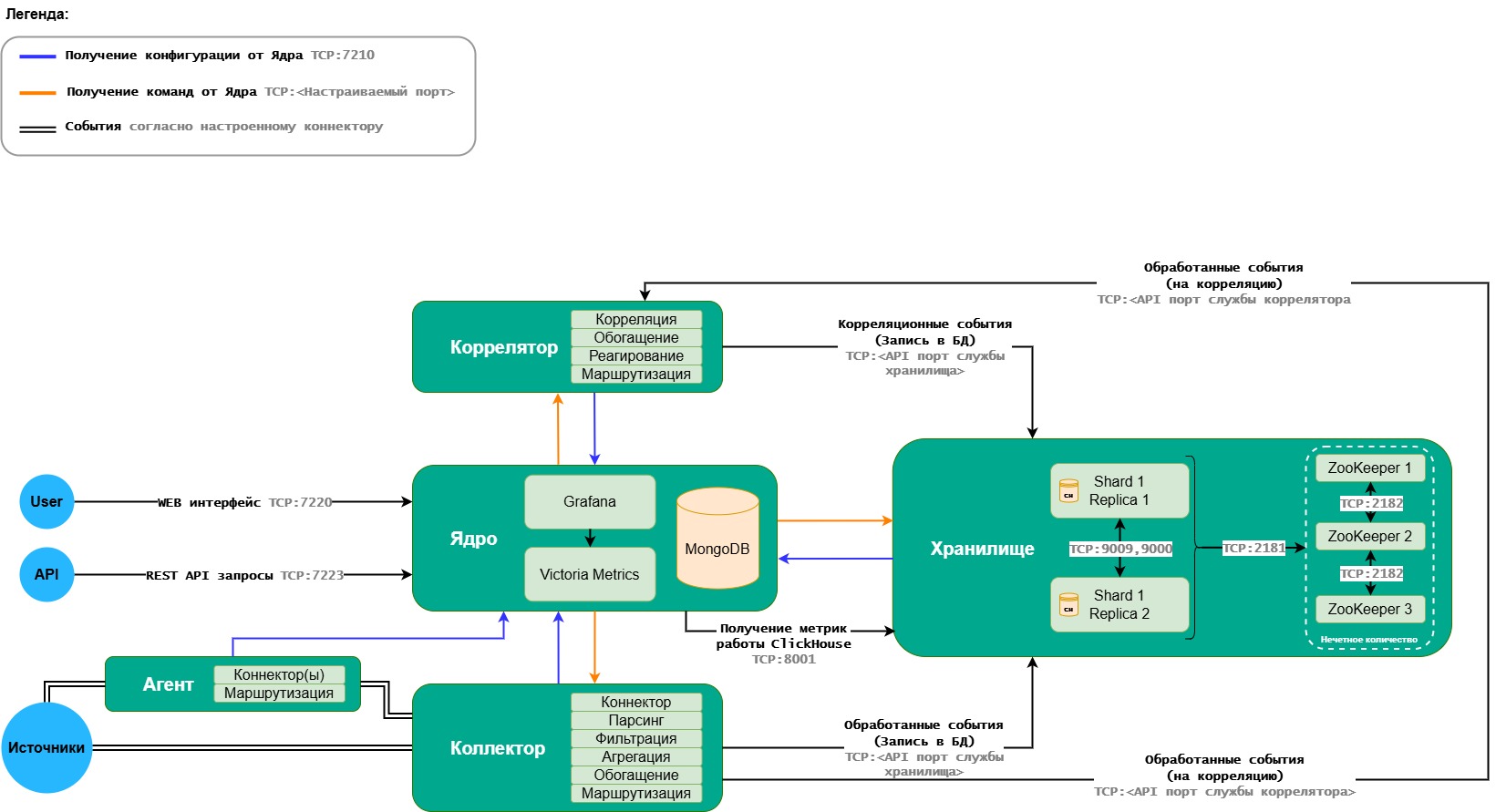
KUMA от 4.0
В случае если не дать доступ от Ядра до API портов служб (оранжевая стрелка), ядро не сможет отслеживать статусы служб и метрики, но события могут отправляться на корреляцию и хранение (если эти доступы открыты)
Сервер метрик подключается в API порт (обычно это 7200+ порты) и забирает метрики. К серверу метрик получается только ядро (отображение метрик и метрики агентов)
Для работы в изолированных сегментах через дата-диод, можно узнать в этой статье
Файл для редактирования (draw.io): https://box.kaspersky.com/d/757e0187aeae4d1caffb/
Модель лицензирования KUMA (Licensing)
Проверить поддержку версии продукта https://support.kaspersky.com/corporate/lifecycle#b2b.block13.kuma
Лицензирование продукта Kaspersky Unified Monitoring and Analysis Platform (KUMA) происходит по среднему количеству обрабатываемых событий в секунду (EPS) за 24 часа.
Минимально возможное количество EPS к приобретению = 500.
Подсчет событий идет после процесса их обработки, то есть после фильрации, агрегации и обогащения.
Если от коллектора событие отправляется в несколько точек назначения, то оно учитывается как одно событие.
В случае, если среднее значение превышает ограничение по EPS, указанное в лицензионном ключе, KUMA уведомляет о данном событии в интерфейсе. А также, если за 7 дней работы KUMA среднее значение EPS превышало ограничение 30% времени и более, KUMA дополнительно отправляет на email-адрес администратора уведомление о превышении количества полученных событий и продолжает далее подсчёт среднего значения EPS, не блокируя функционал.
Лицензии срочные, выписываются на 1, 2 или 3 года, если необходимо больше, то цена складвается из цен за ранее указанные периоды.
По истечении лицензии + 7 дней блокируются все функции (создание и / или изменение контента SIEM, обработка новых событий, корреляция, а также создание или изменение правил корреляции, нормализации, дашбордов, отчетов и пр.), за исключением просмотра информации по ранее собранным событиям.
Описание модулей лицензирования
Решение класса SIEM (Security Information and Event Management), предназначенное для централизованного сбора, анализа и корреляции событий информационной безопасности с различных источников данных. Решение обеспечивает единую консоль мониторинга, анализа и реагирования на угрозы ИБ, объединяя как решения «Лаборатории Касперского», так и сторонних производителей. Начиная с версии 2.1 поддерживается развёртывание в режиме отказоустойчивости, при котором отказ одного или нескольких узлов не приводит к нарушению потоковой обработки событий и выявления инцидентов. Отказоустойчивость системы достигается за счёт встроенных механизмов маршрутизации данных. Дополнительных лицензии и лицензионного ключа для отказоуствойчивости не требуется. Отдельный модуль High Availability доступен только до версии 2.0 (включительно).
Каждый из модулей решения KUMA включает в себя возможность сделать 50 запросов в Kaspersky Threat Lookup для получения дополнительного контекста в ходе проведения расследования. Чтобы активировать эту функцию, отправьте запрос с указанием номера заказа на адрес intelligence@kaspersky.com.
Netflow Support (Netflow)
События телеметрии о трафике, которые помогают в обнаружении аномалий на сетевом уровне и расследовании инцидентов. KUMA выполняет приём и обработку Netflow событий без ограничений, при этом данные Netflow не учитываются в счётчике EPS. Следует учитывать дополнительную нагрузку на мощности машины при анализе Netflow. Поддерживаются стандарты NetFlow v5/v9/IPFIX, Flexible NetFlow (FNF, где периодичноть темплейта должна быть до 1 мин.) и sFlow.
Почему это может быть полезно
Netflow собирает данные о потоках, а не о каждом отдельном пакете, что делает его более эффективным с точки зрения производительности.
Основные данные, содержащиеся в трафике Netflow, (Netflow v5): IP-адрес источника (Source IP), IP-адрес назначения (Destination IP), Порт источника (Source Port), Порт назначения (Destination Port), Номер протокола (Protocol Number, например, TCP, UDP), Количество пакетов (Packets), Количество байтов (Bytes), Время начала потока (Flow Start Time), Время окончания потока (Flow End Time), Номер интерфейса (Interface Index).
Другие параметры: Тип сервиса (Type of Service, TOS), Флаги TCP (TCP Flags), Входящий и исходящий VLAN ID (VLAN ID), Направление потока (Ingress/Egress Interface)
Netflow v9: Более гибкая и расширяемая версия, чем Netflow v5, поддерживающая шаблоны полей, что позволяет собирать дополнительные данные, такие как: MAC-адреса источника и назначения, Имена приложений, Уровень MPLS, Информация о VPN.
Netflow позволяет (целесообразность с точки зрения ИБ):
- отслеживать объемы, типы и направления трафика, что помогает выявлять аномальные паттерны, которые могут указывать на кибератаки, такие как DDoS, сканирование портов, попытки взлома и т.д.;
- отслеживать попытки несанкционированного доступа к сетевым ресурсам;
- предоставляет информацию о том, какие приложения и пользователи потребляют больше всего сетевых ресурсов, что помогает выявить потенциальные уязвимости и оптимизировать сетевую инфраструктуру;
- реконструировать последовательность событий, которые привели к инциденту, что помогает в расследовании и выявлении причин.
GosSOPKA (ГосСОПКА)
Модуль, обеспечивающий возможность интеграции с технической инфраструктурой НКЦКИ (Национальный координационный центр по компьютерным инцидентам). Модуль ГосСОПКА позволит передавать инциденты, выявленные SIEM «по требованию» (т. е. по явному указанию пользователя), в техническую инфраструктуру НКЦКИ через API и получать рекомендации по реагированию на эти инциденты. Модуль ГосСОПКА регулирует только взаимодействие с НКЦКИ по инцидентам.
Threat Intelligence (TI)
В рамках данного модуля поставляются платформа для управления данными об угрозах Kaspersky CyberTrace и потоки данных об угрозах Kaspersky Threat Data Feeds. Наличие лицензии упрощает интеграцию потоков данных с KUMA для дальнейшего использования аналитики угроз в повседневной работе ИБ-служб. KUMA собирает журналы с различных устройств, ИТ-систем и ИБ-инструментов и отправляет данные о событиях с URL, IP-адресами и хешами в Kaspersky CyberTrace на анализ, который сопоставляет поступающие события с потоками данных об угрозах и отправляет данные об обнаруженных угрозах в обратно в KUMA и Kaspersky CyberTrace Web. Аналитик ИБ получает оповещения об обнаруженных угрозах с дополнительным контекстом и может провести первоначальное расследование и инициировать процесс реагирования на основе полученного контекста. Платформа взаимодействует с любыми типами потоков аналитических данных об угрозах («Лаборатории Касперского», других поставщиков, из открытых источников или иных каналов) в форматах JSON, STIX/TAXII, XML и CSV и поддерживает интеграции с рассылками НКЦКИ и бюллетенями ФинЦЕРТ. В рамках данного модуля доступны следующие потоки данных об угрозах: Malicious URL, BotnetCnC URL и Phishing URL, IP reputation и Ransomware URL.
Использовать фиды и Kaspersky CyberTrace, приобретённые в рамках данного модуля, можно только для обогащения событий, получаемых KUMA (использовать с другими SIEM системами, а также для интеграции с системами других классов недопустимо).
Предоставляется к KUMA дополнительно лицензия (Enterprise TIP) на продукт CyberTrace + сертификат для CyberTrace для получения фидов.
При приобретении KUMA (любых модулей) также предоставляется доступ к Kaspersky Threat Intelligence Portal (до 100 запросов в Kaspersky Threat Lookup и до 10 запросов в Kaspersky Threat Analysis) в период действия лицензии. Портал позволяет получить дополнительный контекст в ходе проведения расследований. Чтобы активировать эту функцию,
отправьте запрос с указанием номера заказа на адрес intelligence@kaspersky.com
KUMA Integration Add-on (отправка логов ОС с помощью KES)
(*Дополнение к любой лицензии KUMA)
В KES для Windows, начиная с версии 12.6, есть возможность отправлять события из журналов Windows в коллектор KUMA. Это позволяет получить в KUMA события из журналов Windows со всех хостов, на которых установлен KES для Windows версии 12.6, без установки агентов KUMA на эти хосты. Подробнее тут: https://support.kaspersky.com/KUMA/3.4/ru-RU/280730.htm Ограничений на количество хостов нет.
В KES для Linux, начиная с версии 12.2, есть возможность отправлять события ОС Linux в коллектор KUMA. Поддерживаемые типы событий: ProcessCreate, ProcessTerminate, FileChange, EventLog (ServiceStart, LinuxSessionStart, ServiceStop, LinuxSessionEnd, SuccessfulLogin, NewUserCreated, ...). Подробнее тут: https://support.kaspersky.ru/help/KUMA/4.0/ru-RU/301648.htm и тут https://support.kaspersky.ru/kes-for-linux/12.4.0/314120
Отправка событий из журналов начинается с самой начальной записи
Указанное в лицензии ограничение на максимальное количество устройств номинальное (на текущий момент)
Модуль AI (Artificial intelligence)
Kaspersky Investigation & Response Assistant (KIRA)
Облачный ИИ-ассистент предназначен для анализа событий и корреляционных событий в KUMA. Он выполняет детальный разбор командных строк (Windows/Linux) с деобфускацией, формирует краткое содержание и предоставляет аналитическую информацию, необходимую для расследования инцидентов и приоритизации алертов. Для функционирования модуля требуется действующая лицензия KUMA и сертификат, обеспечивающий возможность выполнения запросов. Использование KIRA подробнее.

Сервис AI (on-prem) по рейтингу и статусу активов
AI-сервис (Инструкция по настройке) получает корреляционные события со связанными активами, формирует ожидаемые цепочки событий и обучает модель на поведении конкретной инфраструктуры.
На основе анализа последовательности срабатываний корреляционных правил система определяет, является ли данная цепочка нетипичной, и автоматически:
- рассчитывает AI-рейтинг актива (числовое значение от 0 до 1);
- предоставляет оценку аномальности, на основе которой можно уточнить приоритет алерта
Модель переобучается раз в сутки, а переоценка рейтинга активов выполняется каждый час для всех активов, участвовавших в событиях за последние 24 часа.
Результат — снижение нагрузки на специалистов ИБ, фокус на реальных инцидентах и ускорение реакции за счет минимизации ложных срабатываний.
Обнаружение атак DLL Hijacking
Облачный модуль обнаружение атак DLL Hijacking — AI механизм выявления одной из самых скрытных техник компрометации. DLL Hijacking используется злоумышленниками для запуска вредоносного кода через легальное ПО за счёт подмены динамических библиотек. Детектирование выполняется на этапе обогащения событий, что позволяет выявлять атаку ещё до её развития.
Ключевые особенности решения:
- Используется обогащение типа «Проверка DLL Hijacking» на корреляторе;
- Требуется доступ к KSN;
- В облачный AI-модуль передаются:
- хэш и путь DLL-файла;
- хэш и путь процесса;
- цифровая подпись процесса (опционально)
Облачный AI-детект усиливает классический сигнатурный подход, обеспечивая более высокую точность и выявление ранее неизвестных атак.
Результат — раннее обнаружение DLL Hijacking, снижение риска обхода средств защиты и повышение эффективности реагирования на сложные атаки.
Материалы:
- Видео из конференции PHDays
- Прикладная статья об этой технике атаки
- подробная инструкция по настройке в официальной документации
Обнаружение (on-prem) использования скомпроментированной УЗ (Lateral Movement)
Модуль представляет собой ML-механизм для выявления скрытого горизонтального перемещения злоумышленника внутри инфраструктуры. Работает с Correlator-NG / Correlator 2.0 (KUMA от 4.2) и анализирует поведение учетных записей, сравнивая текущую активность пользователя с его выученным историческим профилем. Модель обучается на данных за последние 60 дней, что позволяет точно определять индивидуальную «норму» и фиксировать отклонения.
Покрываемые сценарии:
- Аномальное количество ранее неизвестных IP-адресов, с которых выполнялся логон под учетной записью.
- Аномальное количество новых host’ов, куда осуществляется логон и другие активности от имени аккаунта.
- Прочие нетипичные действия, указывающие на попытки горизонтального перемещения.
Результат — раннее обнаружение компрометации, сокращение времени присутствия атакующего в сети и предотвращение развития атаки на критические ресурсы.
Предлагаемая техническая поддержка
https://support.kaspersky.ru/corporate/msa#tab2 по KUMA см. документ "Поддержка для Premium и Premium Plus"
Каналы связи
| Premium | Premium Plus | |
| Company account (веб-портал, уведомления через почту) | ✔ | ✔ |
| Телефон | ✔ | ✔ |
Время реакции в зависимости от уровня критичности
| Premium | Premium Plus | |
| Критический (24 / 7) | 2 часа | 0,5 часа |
| Высокий (в рабочие часы) | 6 часов | 4 часа |
| Средний (в рабочие часы) | 8 часов | 6 часов |
| Низкий (в рабочие часы) | 10 часов | 8 часов |
Доступные услуги
| Программные исправления | Premium | Premium Plus |
| Удаленное подключение для диагностики проблем | ✔ | ✔ |
| Постпроектная поддержка* | ✔ | ✔ |
| Частные исправления | ✔ | ✔ |
| Рекомендации по оптимизации | ✔ | ✔ |
| Персональный технический аккаунт менеджер (ТАМ) | ❌ | ✔ |
| Регулярные статус-встречи с ТАМ для анализа зарегистрированных инцидентов, связанных с ТП | ❌ | Ежеквартальный отчет |
| Разработка нормализаторов для нестандартных источников событий | 10 шт.** | 20 шт.** |
* Консультации по донастройке в среде заказчика проводятся только по продукту KUMA и при наличии информации о инфраструктуре и схеме развёртывания продукта.
** Количество ежегодно.
Premium Pro
Новый (с середины ноября 2025) уровень расширенной технической поддержки. Включает в себя Premium Plus + регламентные работы для сопровождения продукта (Количество работ зависит от типа работ и продуктов заказчика).
Варианты сервисных работ (Premium Pro)
Установка и настройка:
- Развертывание и первоначальная настройка одной инсталляции Kaspersky Unified Monitoring and Analysis Platform
- Разработка дашборда (графической панели) или отчета под нужды заказчика
- Настройка одной интеграции или источника событий
Обновление:
- Сопровождение инженером процесса обновления одной инсталляции KUMA заказчика
Оценка и оптимизация
- Стандартный Health Check - оценка параметров работы KUMA (анализ только блока технического состояния)
- Разработка/доработка нормализатора
- Разработка нового корреляционного правила
- Расчет сайзинга инсталляции: подробный расчёт ресурсов, рекомендуемых для корректной работы продукта
Поддержка на площадке:
- Выезд инженера для консультации в критической ситуации или в случае отсутствия возможности предоставления удаленного доступа
Обучение / Сертификация
Администратор (KL 034.4)
Ссылка на официальный ресурс: https://academy.kaspersky.ru/course/kaspersky-unified-monitoring-and-analysis-platform-administration
- Разворачивание KUMA для демонстрации решения
- Расширение уже существующей инсталляции
- Обеспечение отказоустойчивости ядра, хранилища и коллекторов
- Настройка получения событий из разных источников
- Настройка уведомлений
Расследование (KL 051.4)
Ссылка на официальный ресурс: https://academy.kaspersky.ru/course/kaspersky-unified-monitoring-and-analysis-platform-investigation
Фокус: Расследование и анализ атак
- Настройка обработки событий (нормализация, агрегация, обогащение, и т.д.)
- Создание правил корреляции и реагирования, с последующим анализом данных для выявления угроз
- Использование ресурсов и функций KUMA для анализа и выявления угроз (активные списки, словари, переменные, API и т.п.)
Аналитик безопасности KUMA
Ссылка на официальный ресурс: https://academy.kaspersky.ru/course/kuma-security-analyst
Фокус: мониторинг + первичный анализ
- Анализ алертов и событий безопасности (от первичного анализа до эскалации в инцидент)
- Архитектура KUMA
- Работа с логами:
- поиск и фильтрация
- ретроспективный анализ
- SQL-запросы
- Создание правила корреляции для выявления атак
- Проводить расследование инцидентов и выявление угроз
- Использовать подходы вроде MITRE ATT&CK для анализа атак
Состав поставки дистрибутива
Обычная версия KUMA
- kuma-ansible-installer-k8s-*.tar.gz — архив с пакетами установки KUMA, где отказоустойчивое ядро разворачивается в кластере Kubernetes
- kuma-ansible-installer-*.tar.gz — стандартный архив с пакетами установки KUMA
Сертифицировнная версия KUMA
Обычный архив = certified-архив (ISO) + env* (ISO)
*env — архив с компонентами, не подлежащими сертификации. Используется для получения функционирующего инсталлятора из сертифицированного архива.
Типы хранения данных в KUMA
В KUMA существует три типа пространства для хранения событий:
- Горячее
- Холодное
- Архивное
Для оптимизации использования дискового пространства и ускорения выполнения запросов в KUMA введено несколько уровней устройств хранения:
- Горячее (hot) - оперативное хранение, обычно состоит из быстродействующих устройств с ограниченным объемом пространства [Диски, например: NVMe или SSD]. Поиск по событиям доступен из веб-интерфейса KUMA.
- Холодное (cold) - медленные устройства, но большого объема [Диски, например: HDD SAS или HDD SATA]. Поиск по событиям доступен из веб-интерфейса KUMA.
Основная идея разделения хранилищ на "горячие" и "холодные" состоит в том, что доступ к данным сохраняется, но при этом увеличиваются задержки. Используется сочетание настроек политики хранения ClickHouse и механизма переноса разделов таблиц между дисками. Плюсом подхода является возможность использовать в качестве хранилища любое примонтированное в качестве каталога Linux устройство, хранилища HDFS (используется функционал хранения, поиск делается с ClickHouse), а также S3.
Планируется прекращение поддержки HDFS и рекомендуется запланировать перенос данных в S3.
Подробнее про холодное хранение - https://support.kaspersky.ru/kuma/4.2/221257?page=help
Для холодного по объему пространства нужно столько же, сколько и для горячего (нет дополнительной компресии), сами диски можно использовать менее производительней и подешвле.
С версии 3.4 в связи с расширением функционала, изменился подход к определению срока хранения событий при использовании холодного хранения: Общий срок хранения событий определяется параметром TTL события - отсчет начинается от момента попадания события в хранилище. Значение TTL указывает, сколько времени событие будет храниться в KUMA. Время нахождения события в горячем хранилище определяется Вариантами условий хранения и может быть определено в днях, гигабайтах или процентах дискового пространства. Для горячего хранения можно применить до двух политик. Данные будет находиться в горячем хранилище до срабатывания одной из политик, после чего раздел с самыми старыми данными будет перемещен в холодное хранилище и будет находиться в холодном хранилище до истечения TTL. Общее время = горячее + холодное.
Холодное пространство монтируется на сами хранилища (в случае локального типа холодного хранения) в нужном объеме, на рисунке ниже схематично показано, как это выглядит для двух реплик (R) и одного шарда (S):
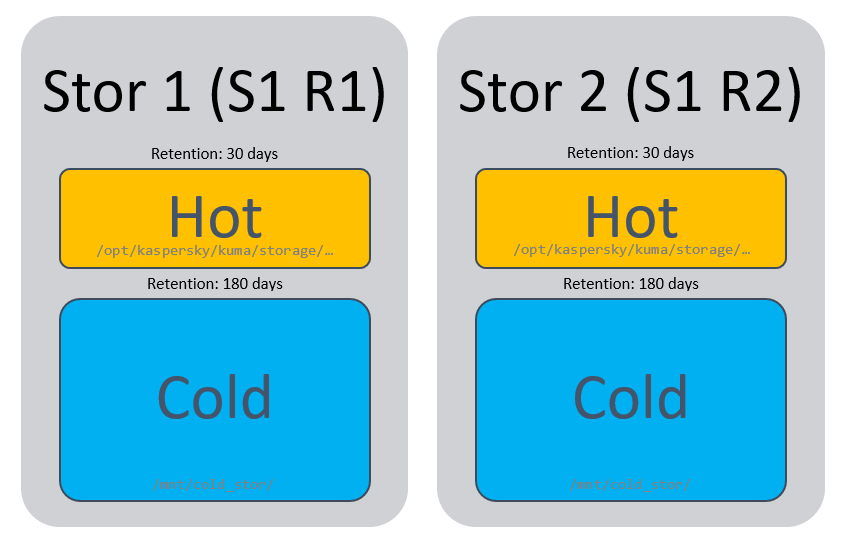
Владельцем папки по точке монтирования холодного хранения должна быть УЗ kuma, команда: chown -R kuma:kuma /mnt/cold_stor/
Если добавить второй локальный диск, то данные между ними будут распределяться по алгоритму round-robin до тех пор, пока кусок данных, который мы хотим вставить не окажется больше свободного зарезервированного места на диске. Когда это случится все записи будут падать по round-robin в следующие диски. Если дисков всего 2, то соответственно в тот, где есть место
Монтирование диска в fstab с правами для kuma
Узнайте UID и GID пользователя kuma
id -u kuma
id -g kumaДобавить запись в конец файла /ets/fstab, пример:
/dev/sdb1 /mnt/cold_stor/ auto defaults,uid=988,gid=984,umask=770 0 0- Архивное хранение — (отщелкивание индексов ClickHouse) по архивным данным поиск не возможен, только если вручную, либо автоматизировано разархивировать и аттачить партиции. [Диски, например: Лента, HDD SATA, USB FLASH, ленты, в сейфе]. Операция архивирования выполняется не автоматически [функционал не из коробки], есть скрипт не официальный, который может выполнять эту задачу (доступен из комьюнити в Community-Pack - см. тут), либо использовать автоматизацию. Объем занимаемого пространства примерно на 40% меньше, чем при горячем/холодном хранении (например, при потоке событий в 1000 EPS, для его хранения в течении 1 месяца требуется 1 ТБ места в хранилище (без учета реплик), в архиве будет занимать 600-700 GB).
- С версии 4.2 из веб-интерфейса стала возможным настройка автоматического архивирования + ручной режим, соответственно и импорт также возможен через веб
KUMA позволяет гибко настроить политику хранения событий (retention-период) по разным условиям: По дате, По объему, По проценту от занятого места на диске
Первичный Траблшут в KUMA (Troubleshoot)
Проверка статуса основных компонентов
Основные службы KUMA:
systemctl status kuma-collector-ID_СЕРВИСА.service
systemctl status kuma-correlator-ID_СЕРВИСА.service
systemctl status kuma-storage-ID_СЕРВИСА.service
systemctl status kuma-core-ID_СЕРВИСА.service
systemctl status kuma-metrics-ID_СЕРВИСА.serviceВ версии KUMA 3.2 сервис ядра изменил название на kuma-core-00000000-0000-0000-0000-000000000000.service
ID_СЕРВИСА можно скопировать в веб-интерфейсе системы, в разделе Активные сервисы, выделив в checkbox нужный сервис, затем нажав кнопку скопировать ID.
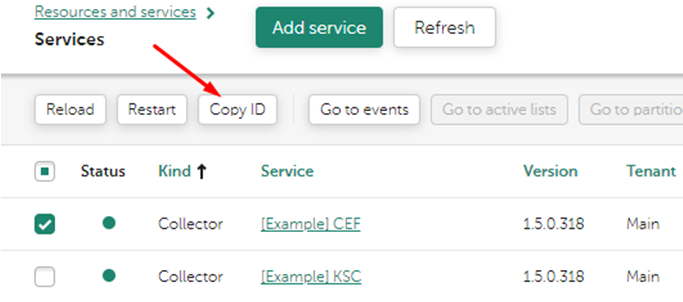
Перед рестартом коры (в версии KUMA 3.2) необходимо убедиться, что БД SQLite не находится в обслуживающем режиме (VACUUM), для этого перед рестартом убедитесь, что после выполенения команды sqlite3 /opt/kaspersky/kuma/core/00000000-0000-0000-0000-000000000000/raft/sm/db 'PRAGMA locking_mode;' получаете ответ normal
Проверка журнала ошибок KUMA
/opt/kaspersky/kuma/<Компонент>/<ID_компонента>/log/<Компонент>
Пример:
/opt/kaspersky/kuma/storage/<ID хранилища>/log/storage
Для неактуальных версий (2.0 и ниже):
journalctl –xe- Журнал ошибок Click-House:
/opt/kaspersky/kuma/clickhouse/logs/clickhouse-server.err.log
Вывод ошибок сервиса в консоль
В случае отсутствия информации в журналах целесообразно вывести информацию в консоль. Проверяем статус сервиса и копируем его параметры запуска:
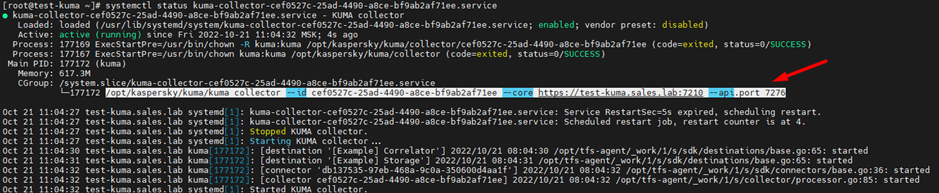
Останавливаем сервис, переходим в папку cd /opt/kaspersky/kuma/ и запускаем следующим образом, пример команды ниже:
sudo -u kuma /opt/kaspersky/kuma/kuma collector --id cef0527c-25ad-4490-a8ce-bf9ab2af71ee --core https://test-kuma.sales.lab:7210 --api.port 7276Пустые метрики
Для версий ниже 3.2
В случае если раздел метрик пустой (отсутствуют значения на дашбордах), то проверьте указан ли IP и hostname сервера KUMA в файле /etc/hosts, если нет то добавьте.
Перезапустите службы:
systemctl restart kuma-victoria-metrics.service
systemctl restart kuma-grafana.serviceЛибо присутствует конфликт со службой Cockpit на Oracle Linux.
Она слушает тот же порт 9090, что и Victoria Metrics. Останови Cockpit и посмотри, поднимутся ли метрики.
Либо проблема из-за наличия прокси между ядром и АРМом, с которого к вебке подключались.
Проверка прослушивания порта, например, 5144
netstat –antplu | grep 5144Работа с портами на МЭ (firewall-cmd)
Проверка открытых портов на МЭ:
firewall-cmd --list-portsДобавление порта 7210 на МЭ:
firewall-cmd --add-port=7210/tcp --permanentПрименение настроек:
firewall-cmd --reloadПроверка получения событий на порту 5144 в ASCII
tcpdump -i any port 5144 -AОтправка тестового события на порт 5144, для проверки работы коллектора
Для TCP:
nc 127.0.0.1 5144 <<< 'CEF:0|TESTVENDOR|TESTPRODUCT|1.1.1.1|TEST_EVENT|This is a test event|Low|message="just a test coming through"'Для UDP:
nc -u 127.0.0.1 5144 <<< 'CEF:0|TESTVENDOR|TESTPRODUCT|1.1.1.1|TEST_EVENT|This is a test event|Low|message="just a test coming through"'В случае наличия в сыром событии двух типов кавычек ' и ", то целесообразно отпралять событие из файла (для этого тестовое событие запишите в файл 1 строку).
cat test.txt | nc -u 127.0.0.1 5144Для HTTP:
curl -X POST -d "Your message here" http://localhost:<port>/pathЕсли многострочное событие в файле с разделителем \0:
truncate -s +1 sample
curl http://<ip/host>:<port>/input --data-binary "@/root/sample"Статус службы красный / Ошибка на компоненте
Переписать / перепроверить учетные данные (если используются) используемые в коннекторе на коллекторе. Проверить владельца папки службы, должно быть kuma:kuma
Посмотреть статус сервиса через консоль ssh. В случае если он запущен остановить:
systemctl stop kuma-collector-ID_СЕРВИСА.serviceзапустить вручную (--api.port выбирайте любой свободный), и посмотреть есть ли ошибки при запуске:
/opt/kaspersky/kuma/kuma collector --id ID_СЕРВИСА --core https://FQDN_KUMA:7210 --api.port 7225Если будут ошибки, они явно отразятся в консоли.
Для сервисов без ID, сначала смотрим параметры запуска службы, например:
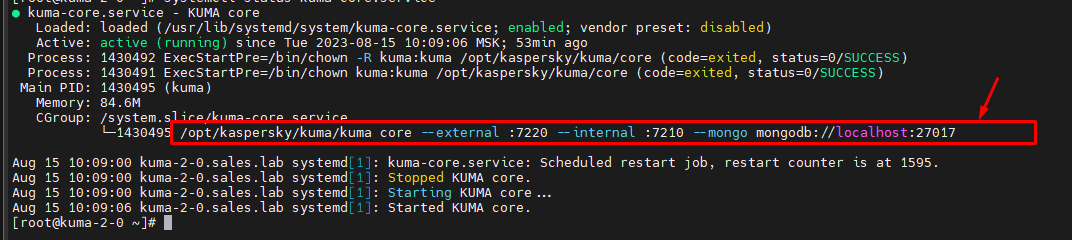
Затем делаем стоп службы и запускаем строку запуска от пользователя KUMA:
Для версий ниже 3.2
sudo -u kuma /opt/kaspersky/kuma/kuma core --external :7220 --internal :7210 --mongo mongodb://localhost:27017Ручная очистка пространства хранилища
Если место на сервере хренения заканчивается, но еще не закончилось.
Выберите в активных сервисах - сервис хранилища (storage) и нажмите на кнопку смотреть разделы. Удаляйте наиболее старые партиции.
Далее (чтобы в будущем не заполнялось):
- Resources/Storage - уменьшаем ретеншен период
- после этого рестарт сервисов KUMA Storage. Изменения применятся примерно в течение часа и место освободится.
Закончилось дисковое пространство
Если место уже закончилось.
- При all-in-one инсталляции в web консоль KUMA уже не пустит. Для all-in-one последовательность действий следующая:
- Останавить все сервисы
systemctl stop kuma-* - Удалить буферы коллекторов и коррелятора:
rm -rf /opt/kaspersky/kuma/collector/*/buffers/*иrm -rf /opt/kaspersky/kuma/correlator/*/buffers/ - Удалить кеш обогащения (если есть) коллекторов и коррелятора:
rm -rf /opt/kaspersky/kuma/collector/*/cache/enrichment/*иrm -rf /opt/kaspersky/kuma/correlator/*/cache/enrichment/ - Удалить лог файлы clickhouse:
rm -rf /opt/kaspersky/kuma/storage/*/logs/ - запустить сервис clickhouse:
systemctl start kuma-storage* - запустить сервисы core:
systemctl start kuma-core-00000000-0000-0000-0000-000000000000 - залогиниться в web консоль KUMA, удалить лишние партиции (см. предыдущий пункт траблшута)
- Стартуем оставшиеся сервисы KUMA (
kuma-metrics-<ID>.service,kuma-collector-*,kuma-correlator-<id>)
- Останавить все сервисы
- Если серверы хранения находятся отдельно:
- Остановить все коллекторы и корреляторы. Никакие новые события не должны отправляться в Storage.
- На серверах хранения остановить сервис kuma-storage
- очистить файлы журналов
rm -rf /opt/kaspersky/kuma/storage/*/logs/ - очистить файлы буфера
rm -rf /opt/kaspersky/kuma/storage/*/buffers/ - Запустить сервис
systemctl start kuma-storage-<ID> - Залогиниться в web консоль KUMA, удалить лишние партиции (см. предыдущий пункт траблшута)
Далее (чтобы в будущем не заполнялось) в KUMA с версии 3.2: В Параметры - Мониторинг сервисов - Хранилище, выставьте нужные значения по оповещениям и ротации.
Для полной очитки данных хранилища (выполнять на хранилищах и киперах):
- systemctl stop kuma-storage-*.service
- rm -rf /opt/kaspersky/kuma/clickhouse/data
- rm -rf /opt/kaspersky/kuma/clickhouse/coordination
- rm -rf /opt/kaspersky/kuma/clickhouse/logs/
- Иногда полезно чистить
- rm -rf /opt/kaspersky/kuma/clickhouse/tmp/
- rm -rf /opt/kaspersky/kuma/storage/*/buffers/
- systemctl start kuma-storage-*.service
Создание сервисов в случае их отсутствия
Если в разделе Ресурсы – Активные сервисы отсутствуют что-либо, то необходимо создать необходимые службы.
Создаем сервис хранилища
Перейдите в Ресурсы – Хранилища затем нажать на кнопку Добавить хранилище придумайте название и затем укажите количество дней хранения событий и событий аудита (от 365 дней срок хранения аудита), затем нажмите Сохранить.
Публикуем созданный сервис Ресурсы – Активные сервисы затем выбрать созданный ранее сервис и нажать на кнопку Создать сервис.
Скопируйте идентификатор сервиса:

Выполните команду в консоли:
В случае использования ядра в кластере Raft в параметре --core необходимо указать адреса всех серверов ядра через запятую.
/opt/kaspersky/kuma/kuma storage --id <ВАШ_ИДЕНТИФИКАТОР> --core https://<FQDN/ИМЯ_ХОСТА_СЕРВЕРА_ЯДРА>:7210 --api.port 7230 --installВ разделе Ресурсы – Активные сервисы убедитесь, что служба работает более 30 секунд с «зеленым» статусом индикатора:

Далее создадим точку назначения, которая используется в маршрутизации событий, перейдите в Ресурсы – Точки назначения, затем нажмите на кнопку Добавить точку назначения. Придумайте название и затем в поле URL укажите FQDN и порт службы хранилища, например: kuma-1-5-1.sales.lab:7230, затем нажмите Сохранить.
Аналогичные действия понадобятся для установки остальных компонентов, только в интерфейсе будет доступна команда, которую необходимо будет выполнить для установки службы.
Создаем сервис коррелятора
Развернем коррелятор, перейдите в Ресурсы – Корреляторы, нажмите на кнопку Добавить коррелятор и затем пройдите по мастеру настроек, на шаге добавления маршрутизации добавьте точку назначения ранее созданного хранилища:
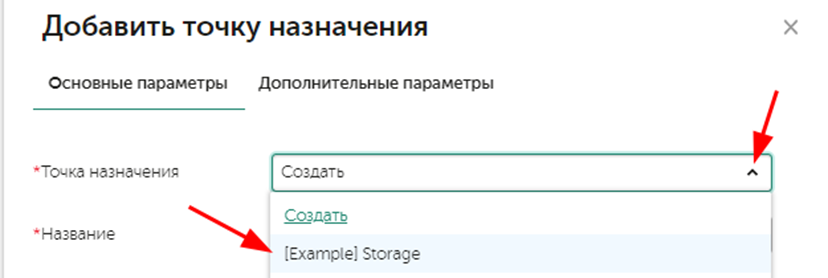
На последнем шаге нажмите кнопку Сохранить и создать сервис, в случае отсутствия ошибок появится командная строка для установки службы, скопируйте ее и выполните по ssh.

Аналогично по мастеру создаются коллекторы для приема или получения событий с источников.
Ошибка скрипта при установке - ipaddr
Если при установке возникает следующая ошибка (пишется в конце исполнения скрипта):
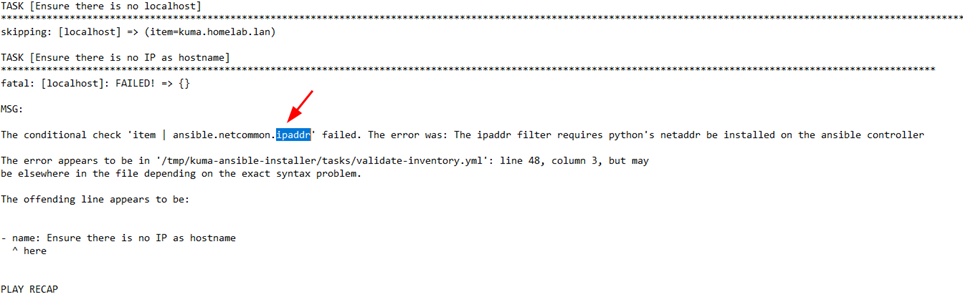
То попробуйте установить нужную библиотеку для python, это было в требованиях https://support.kaspersky.com/KUMA/1.6/ru-RU/231034.htm, в случае отсутствия возможности это сделать то закомментируйте (вставьте # перед строками) следующие строки в файле kuma-ansible-installer/tasks/validate-inventory.yml:
#- name: Ensure there is no IP as hostname
# loop: "{{ groups.all }}"
# when: item | ansible.netcommon.ipaddr
# fail:
# msg: |
# host: {{ item }}
# error: Hostname expectedСлушать на 514 порту (порты < 1024)
По умолчанию это невозможно, так работает Linux. Для обхода этого в описании сервиса:
/usr/lib/systemd/system/kuma-collector-<ID>Добавьте значение ниже тега [Service]
AmbientCapabilities=CAP_NET_BIND_SERVICEЗатем запустите команду ниже для обновления параметров сервиса
systemctl daemon-reloadНе запускается хранилище после перезагрузки в версии от 2.1
Прописать следующую команду в SSH консоли:
sudo -u kuma touch /opt/kaspersky/kuma/clickhouse/data/flags/force_restore_dataОшибка БД ClickHouse Table read only replicas
Ошибка в логах хранилища выглядит так: 
Зайдите в клиент ClickHouse:
/opt/kaspersky/kuma/storage/<ID>/deps/clickhouse/bin/client.shВыполните команду:
system restart replica on cluster kuma kuma.events_local_v2Для выхода из клиента нажмите Ctrl+D.
Ошибка ZooKeeper - KEEPER_EXCEPTION
Убедиться, что ipv6 включен:
ping ::1Убедиться, что у вас корректное содержимое в /etc/hosts, смотрите этап подготовки п. 8
Очистить Coordination Zookeeper и наработки хранилища (удаляет все события):
systemctl stop kuma-storage-<ID>.service
rm -rf /opt/kaspersky/kuma/storage/<ID>/data/*
rm -rf /opt/kaspersky/kuma/storage/<ID>/tmp/*
rm -rf /opt/kaspersky/kuma/clickhouse/coordination/*
systemctl start kuma-storage-<ID>.serviceИногда требуется (в случае если ошибка остаеся):
sudo -u kuma touch /opt/kaspersky/kuma/clickhouse/data/flags/force_restore_dataЛибо:
/opt/kaspersky/kuma/clickhouse/bin/client.sh
system restore replica on cluster kuma kuma.events_local_v2Признаки нехватки выделенных ресурсов
Описание метрик доступно тут: https://kb.kuma-community.ru/books/kuma-how-to/page/opisanie-metrik-v-kuma
Универсальный показатель Load

Мощностей не хвататет, если на нодах высокий LA (Load average), утилизация CPU доходит до 100%, нагрузка зависит не только от потока (EPS) зависит, но и от профиля использования (количество обогащений, интеграций, используемых правил и т.д.). Средние значения нагрузки (Load averages):
- Если значения равны 0.0, то система в состоянии простоя
- Если среднее значение для 1 минуты выше, чем для 5 или 15, то нагрузка растёт
- Если среднее значение для 1 минуты ниже, чем для 5 или 15, то нагрузка снижается
- Если значения нагрузки выше, чем количество (виртуальных) процессоров, то могут быть проблемы с производительностью (в зависимости от ситуации)
Проблема с производительностью диска на хранилище по метрикам
Накапливается буфер в точках назначения, на рисунке ниже хранилище не справляется с потоком, в норме буфер не накапливается при доступности хранилища:

Загрузка CPU и RAM доходит до 100% или близко к этому значению:

В случае использования кластера хранилищ растут очереди распределенных запросов и мерджи:

Хранилища выпадают в режим только для чтения:

Может быть полезно для хранилища при нагрузках или плохой производительности:
- Работа с объемом буфера для записи в хранилище и временем ожидания, изменение парметров хранилища (во вкладке дополнительно службы хранилища):
- Если в метриках по хранилищу Batch Size крайне низок по сравнению со 128 МБ, то следует увеличить Интервал очистки буфера (по умолчанию 1 сек). Данные сбрасываются в хранилище либо по достижению определенного размера или по таймауту и задача найти этакий баланс между размером пачки и интервалом очистки. Хранилище не любит работать часто с мелкими фрагментами данных.
- Размер буфера (Batch Size) по умолчанию он 128 МБ, увеличить в большую сторону.
- Вынесение и использование отдельных машин с ролью keeper
- Использование более производительного RAID массива
- Использование более производительного дискового носителя
- Использование дополнительного шарда для повышения производительности
Также оценить нагрузку на диск можно командой top в ОС Linux, отслеживая параметр wa (wa: io wait cpu time (or) % CPU time spent in wait on disk) — показывает процент операций, готовых быть выполненных процессором, но находящихся в состоянии ожидания от диска. Допустимое значение < 0.5, в идеале 0.
Требования к хранилищу - тут
Устройство кластера хранилищ - тут
Проблема с производительностью сервисов (особенно коррелятор), большой Output Latency
Если CPU заняты не полностью (не на 100%), а Latency существенный (более 1-2 сек) — проблема вероятней всего в сети. Ниже пример допустимого Output Latency.

Для подверждения, что проблема именно в сети, установите коррелятор локально (что бы события не через сетевой интерфейс летели, а через localhost) на сервер с коллекторами, и подайте туда поток событий с аналогичной нагрузкой. Также полезно ознакомиться с разделом ниже.
Проблема с производительностью сервисов (особенно коррелятор), большьшая нагрузка на CPU, памяти и периодические перезапуски службы
Большое кол-во коллекторов (> 100 шт.) перенаправляют события на коррелятор. Высокая загрузка CPU на серверах и большое количество отправляемых пакетов с коллекторов приводит к общей деградации серверов со службой коррелятора по CPU и памяти (корреляторы перезапускаются каждые 5 минут). Пример поведения по метрикам:

Для решения проблемы были внесены изменения в точку назначения коррелятора, увеличив время ожидания соединения до 300-400 сек (задача найти этакий баланс между размером пачки и скоростью обработки/времени задержки). Множество мелких вставок данных от множества коллекторов в коррелятор хуже, лучше редкие и пачки объемней. Утилизация памяти на серверах со службой коррелятора выше 50% в течение для не поднималась.

Если CPU потребляются не на 100%, но при этом увеличивается время задержки обработки или нестабильное потребление ОЗУ, то можно:
- попробовать подобрать оптимальное (больше не значит производительней - используйте метод научного тыка) число рабочих процессов / workers для службы, количество воркеров должно быть идентичным для совместно работающих служб, например, на коллеккторе и его точке назначения - корреляторе.
- в случае когда соединений к коллектору становится очень много, то стандартное значение буфера (нуль =
1Мб) приводит к увеличению потребления оперативной памяти, так как память выделяется под каждое соединение. Рекомендуемое значение = размер события + небольшой запас в байтах (можно посмотреть в метриках в разделе нормализация - Raw & Normalized event size). Настройка выполняется на коллекторе "Транспорт - Дополнительные - Размер буфера")
Также полезным будет события от множества коллекторов отправлять в маршрутизатор событий (отдельный служба в KUMA) для реализации отдачи потока событий от одной точки.
Также это один из поводов дополнительно увеличить доступные коррелятору вычислительные ресурсы, либо разделить имеющиеся правила на N независимых групп, разместив каждую группу правил на отдельной группе корреляторов, если решение выше не сильно помогло.
Профилирование нагрузки служб
Профилирование необходимо для более глубокого изучения проблем связанных с нагрузкой и ресурсами.
1. Включить профилирование для сервиса, отредактируйте файл сервиса
/usr/lib/systemd/system/kuma-<serviceKind>-<ID>.serviceВ файле необходимо найти параметр ExecStart= и дописать в конце --pprof после этого выполнить systemctl daemon-reload и перезапустить (restart) сервис.
2. Команда для сбора профиля данных по памяти
curl http://127.0.0.1:7211/debug/pprof/heap > /tmp/heap.out3. Команда для сбора профиля данных по процессору
curl http://127.0.0.1:7211/debug/pprof/profile?seconds=30 > /tmp/cpuprof.out4. Расшифровка профиля. Потребуется установленный Go из папки с бинарем go (загружаете для своей ОС https://go.dev/dl/) запускается команда (в результате будет сгенерирована картинка с профайлером):
go tool pprof -png /tmp/heap.outПример результата:

Другие профили:
curl -o allocs.out http://127.0.0.1:7211/debug/pprof/allocs
curl -o block.out http://127.0.0.1:7211/debug/pprof/block
curl -o cmdline.out http://127.0.0.1:7211/debug/pprof/cmdline
curl -o goroutine.out http://127.0.0.1:7211/debug/pprof/goroutine
curl -o mutex.out http://127.0.0.1:7211/debug/pprof/mutex
curl -o threadcreate.out http://127.0.0.1:7211/debug/pprof/threadcreate
curl -o trace.out http://127.0.0.1:7211/debug/pprof/trace?seconds=30Мониторинг работы ядра в кластере Kubernetes
Посмотреть логи сервисов KUMA:
k0s kubectl logs -f -l app=core --all-containers -n kumaНа хосте контроллера можно посмотреть какие сервисы запущены:
k0s kubectl get pods --all-namespacesПо команде выше, в столбце NAMESPACE нам интересна строка kuma, в этой строке берем значение столбца NAME для просмотра конфигурации используем команду:
k0s kubectl get pod core-deployment-984fd44df-5cfk5 -n kuma -o yaml | lessПолучить список рабочих узлов:
k0s kubectl get nodesПолучить расширенную инфу по рабочему узлу, в т.ч. потребление:
k0s kubectl describe nodes kuma-4.localЗайти в командную строчку пода core-*:
k0s kubectl exec --stdin --tty core-deployment-984fd44df-gqzlx -n kuma -- /bin/shПотребление ресурсов контейнеров внутри пода:
k0s kubectl top pod core-deployment-984fd44df-gqzlx -n kuma --containersДля более удобного управления кластером используйте утилиту k9s - https://github.com/derailed/k9s
После установки ядра в кластере в папке установки прописывается конфиг, например, /root/kuma-ansible-installer/artifacts/k0s-kubeconfig.yml. Его надо “скормить” k9s командой: export KUBECONFIG=/root/kuma-ansible-installer/artifacts/k0s-kubeconfig.yml
Для персистентности переменной KUBECONFIG, необходимо выполнить команду:
echo "KUBECONFIG=/root/kuma-ansible-installer/artifacts/k0s-kubeconfig.yml" >> /etc/environmentПроверить переменные окружения можно командой:
export -pДалее можно запустить утилиту (ее можно загрузить отсюда) просто указав на исполняемый файл ./k9s
 Небольшие подсказки по горячим клавишам k9s:
Небольшие подсказки по горячим клавишам k9s:
?— Посмотреть хелп по командамShift+F— Настроить порт форвардинг (например, для longhorn-ui):— для ручного ввода команд, ESC для выхода:events— Смотреть события кубера:pods— Смотреть поды кубера (стандартное отображние)
Общий подход по траблшутингу k8s:
Описание процесса работы c инцидентами в KUMA
Ниже приведено описание основного функционала KUMA задействованного в управлении инцидентами.
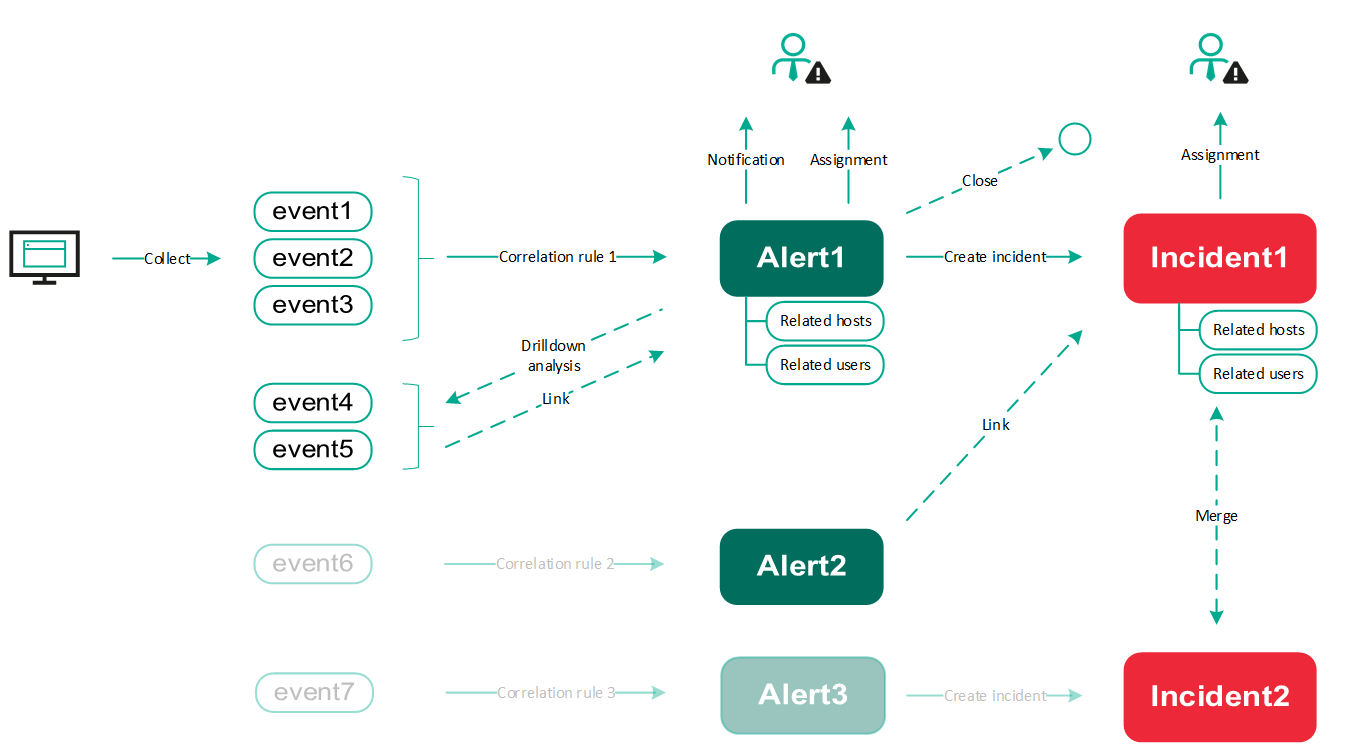
Алерты
Создание алерта
Алерт создается в результате сработки корреляционного правила на основе поступивших событий, он является подозрением на инцидент. Чтобы создать алерт, необходимо настроить корреляционное правило и в секции Actions не включать опцию Do not create alert, в таком случае при срабатывании этого правила, создастся новый алерт.
Оповещение об алерте
При появлении алерта есть возможность настроить оповещение на почту. Для этого необходимо перейти в Settings -> Alerts -> Notification rules. При создании нового правила оповещения можно указать свой шаблон для письма. С помощью правил оповещения есть возможность настроить разные сценарии в зависимости от того какое корреляционное правило сработало, и исходя из этого оповещение уйдет разным получателям.
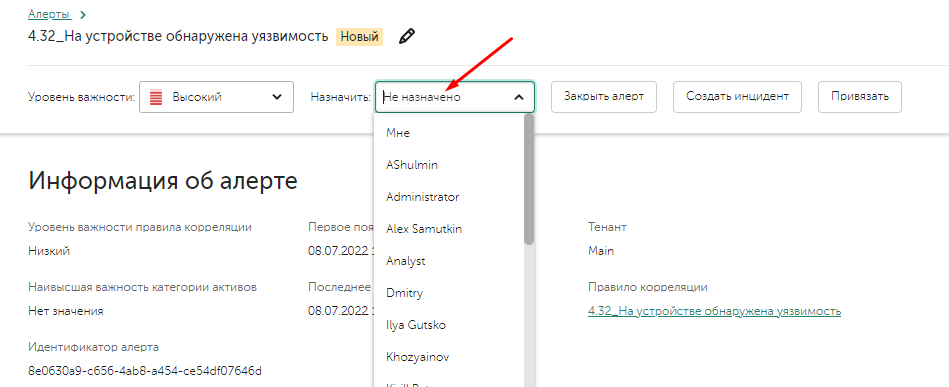
Назначение ответственного на алерт
Обнаружив новый алерт, аналитик может взять его в обработку, назначив на себя, для этого в окне алерта необходимо на верхней панели в поле Assigned to выбрать Me, либо выбрать другого пользователя, чтобы назначить алерт на него.
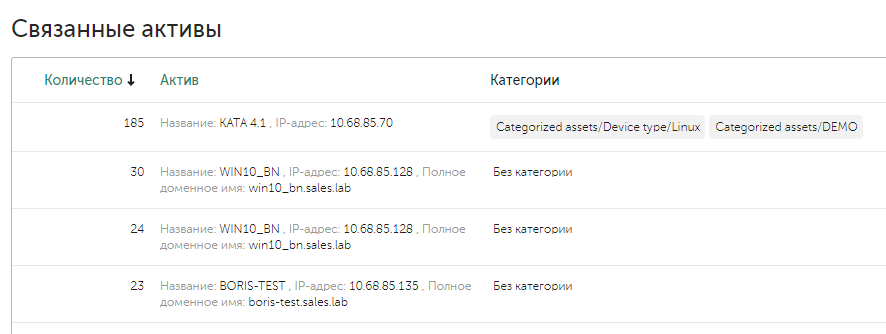
Связанные активы
В рамках алерта в зависимости от событий могут быть связанные активы (хосты или аккаунты). Для автоматической актуализации активов можно настроить интеграцию, например, с Active Directory и Kaspersky Security Center. Если в событии встречается актив, то система автоматически связывает само событие с активом, а затем и алерт с активом. Список связанных активов находится в карточке алерта в полях Related endpoints и Related users.
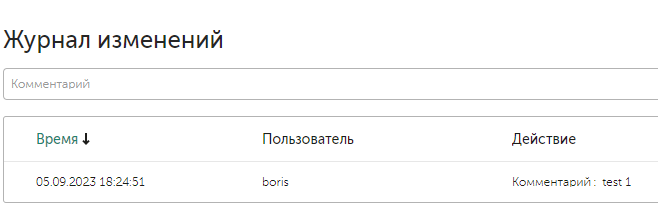
История изменений и ведение журнала
Для отслеживания всех действий, в карточке алерта есть раздел Change log, куда записываются все изменения алерта. Также для удобного взаимодействия внутри команды аналитиков, есть возможность оставлять записи в Change log, чтобы фиксировать ход расследования или записывать важную информацию.
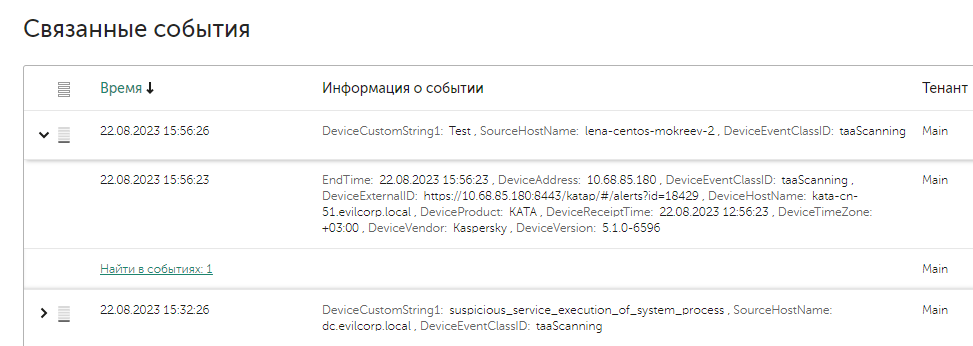
Связанные события
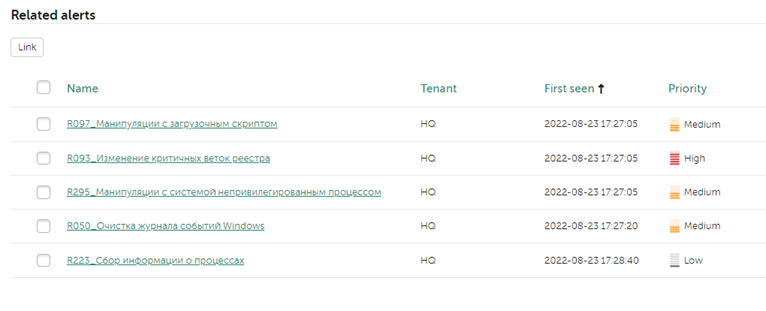
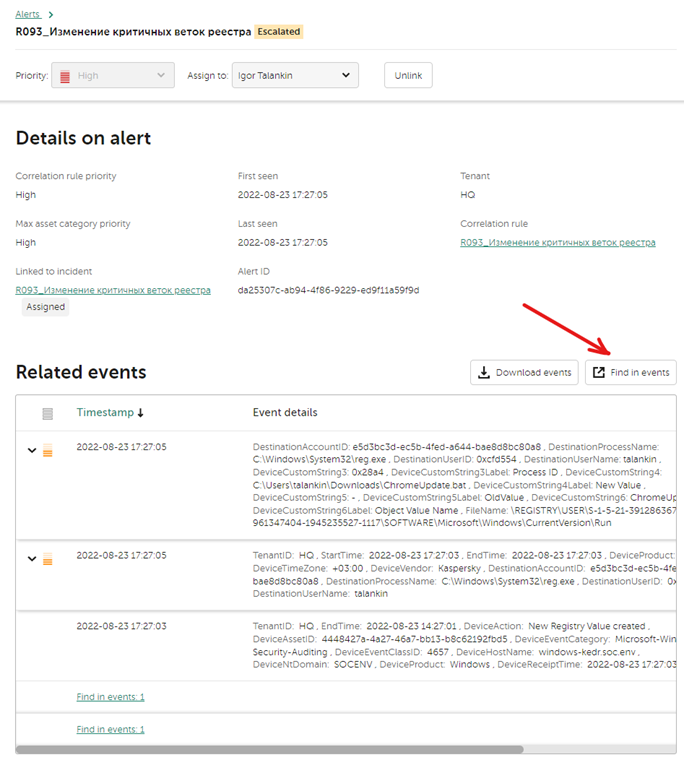
При срабатывании одного и того же правила новых алертов не создается, а наполняется существующий до тех пор, пока он не будет закрыт, либо если не создано правло сегментации для этого првила корреляции. В одном алерте может быть несколько вложенных событий, которые указаны в поле Related events. Для удобства расследования связанные события раскрываются в иерархическое дерево в зависимости от цепочки сработавших правил. Детали каждого события можно просмотреть прямо из карточки алерта, нажав на само событие.
Детализированный анализ
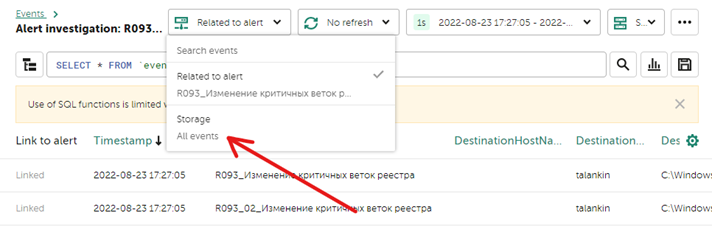
При необходимости детального анализа и изучения событий, которые произошли до и после инцидента, можно перейти ко всем событиям из алерта, нажав кнопку Find in events в разделе Related events. Перейдя во вкладку Events в результатах поиска, будут отображены все связанные события. Для отображения всех событий, которые были в данные промежуток времени, нужно сменить выбор с Related to alert, на All events. В результате отобразятся все события, среди которых можно выполнить поиск новых связанных событий и привязать их к алерту. Для этого выберете событие и в появившемся окне с детальной информацией нажмите Link to alert. Таким образом можно обогатить алерт новыми связанными событиями.

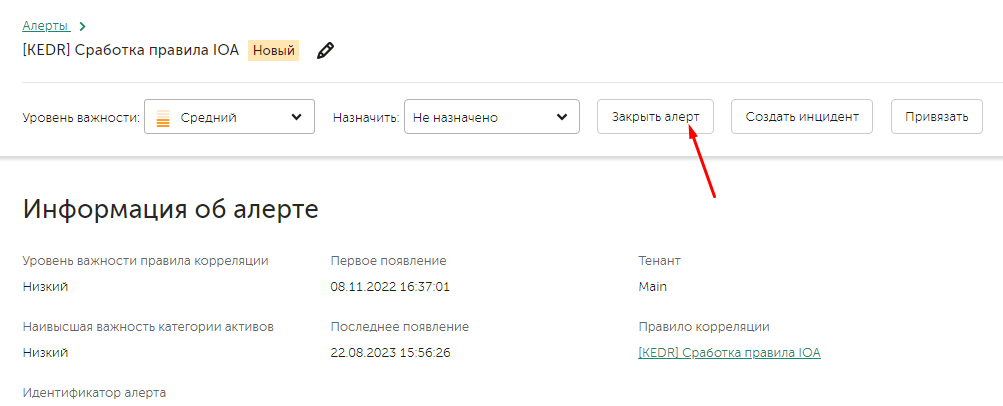
Закрытие алерта
В случае ложного срабатывания или, если нет необходимости создавать инцидент, есть возможность закрыть алерт. При закрытии алерта необходимо указать одну из трех причин: Отработан, Неверные данные, Неверное правило корреляции.
Создание инцидента
В случае необходимости повышения алерта до уровня инцидента, это можно сделать с помощью кнопки Create incident.
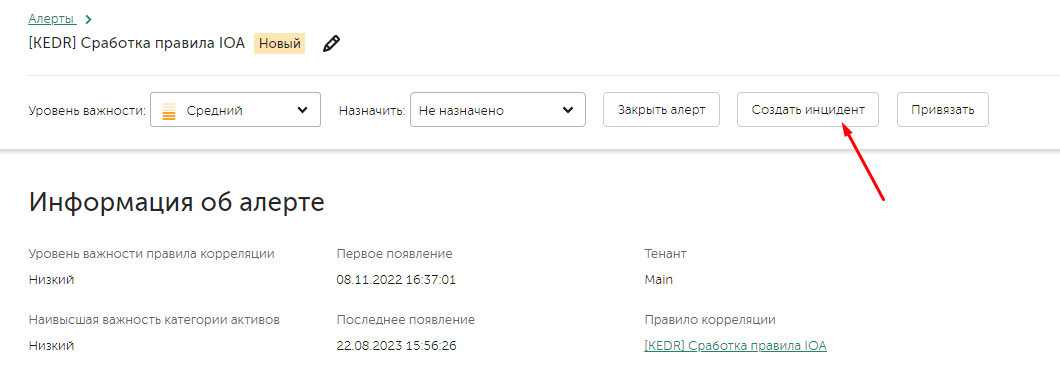
Привязка алерта к инциденту
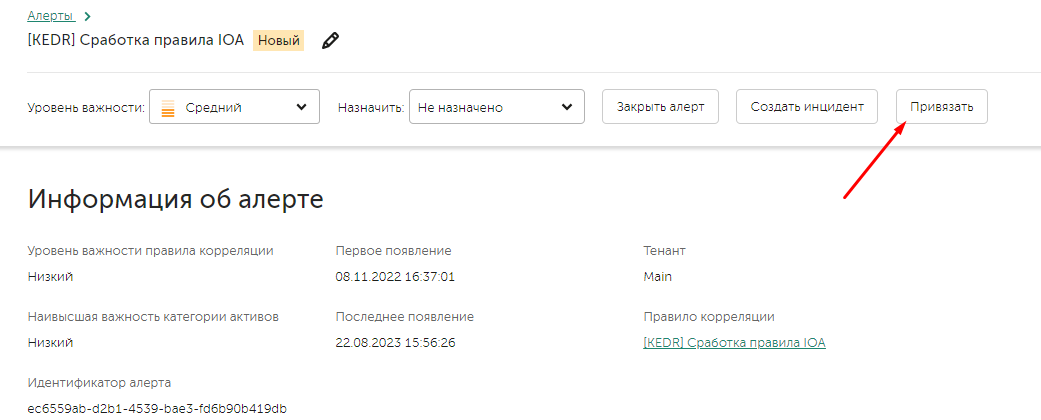
В случае, если алерт является частью активности, расследуемой в рамках уже существующего инцидента, его можно привязать его с помощью кнопки Link.
Привязанный алерт становится недоступен для изменения – при необходимости изменения алерта (например добавления в него событий), нужно отвязать (unlink) алерт от инцидента, внести изменения, и привязать его обратно.
Инциденты
Создание инцидента
Инцидент можно создать на основе алерта или вручную с помощью кнопки Create incident во вкладке Incidents. При создании вручную необходимо заполнить обязательные поля, также при необходимости, есть возможность прикрепить к инциденту алерты или связанные активы.
Объединение инцидентов
Если в ходе расследования потребовалось объединить несколько инцидентов в один – это можно сделать с помощью функционала объединения. Для этого в окне инцидента нужно на верхней панели нажать на Merge и выбрать инцидент, с которым необходимо выполнить объединение.
Назначение ответственного на инцидент
При создании нового инцидента, аналитик может взять его в обработку, назначив на себя, для этого в окне инцидента необходимо на верхней панели в поле Assigned to выбрать «Me», либо выбрать другого пользователя, чтобы назначить инцидент на него.
Пример процесса реагирования на инциденты
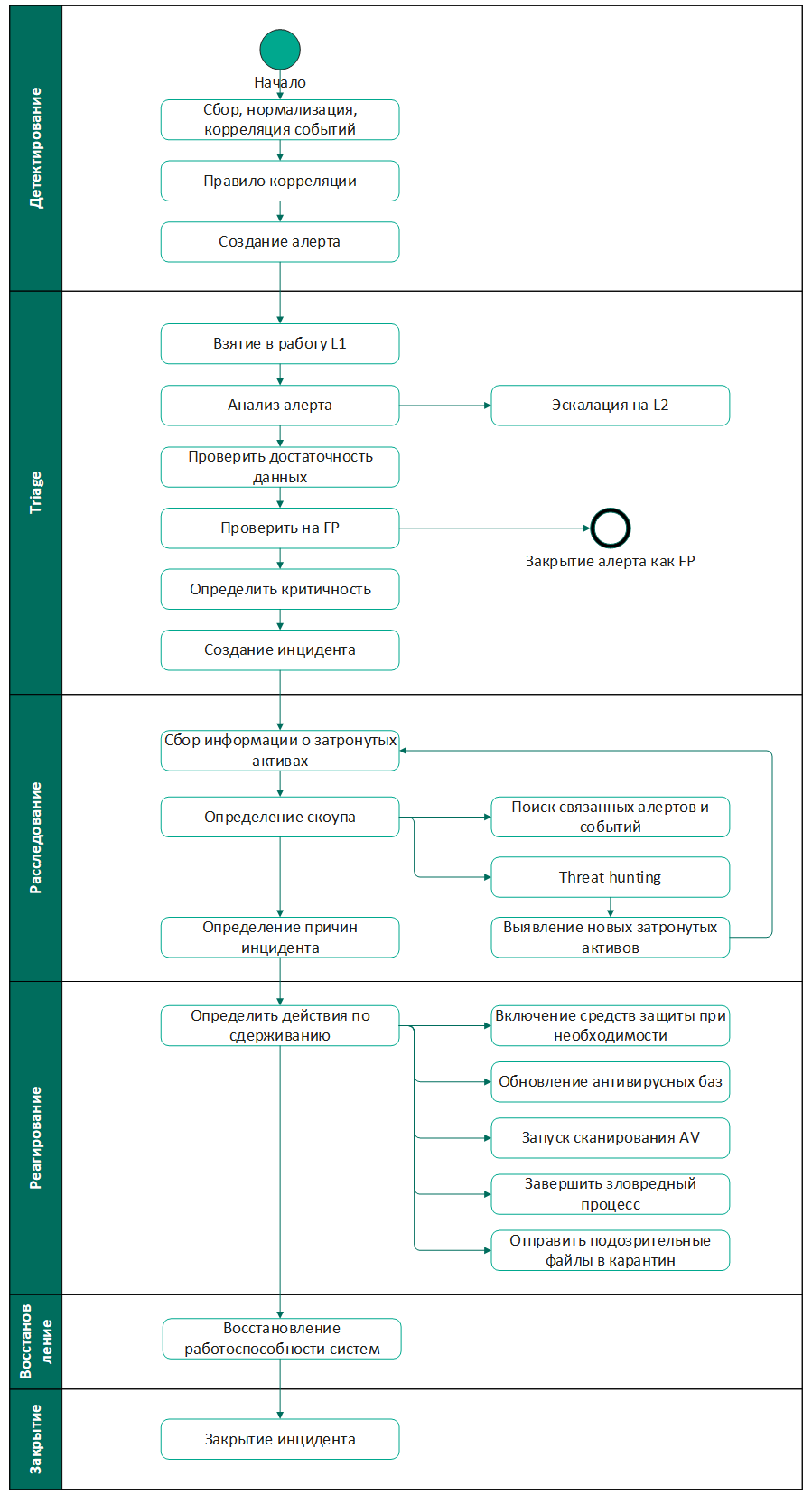
Рассмотрим пример плана реагирования на инцидент, в рамках которого можно выделить стадии:
- Мониторинг – сбор и анализ событий, выявление аномалий и подозрительной активности с помощью правил корреляции или threat hunting.
- Триаж – первичный анализ алертов с целью выявления инцидентов, ложных срабатываний и ошибок в рамках процесса мониторинга.
- Расследование – сбор информации об активах и вредоносной активности с целью определения скоупа, причин инцидента и всей цепочки атаки.
- Реагирование – противодействие вредоносным действиям с целью предотвратить дальнейшее продвижение злоумышленника и сократить влияние на инфраструктуру
- Восстановление – приведение инфраструктуры в первоначальное состояние и проверка работоспособности
- Закрытие – заключение или отчет об инциденте и закрытие инцидента
Пример реагирования на инцидент с помощью KUMA
Рассмотрим пример реагирования на инцидент с помощью Kaspersky Unified Monitoring and Analysis Platform. Для примера будет взят стенд со следующими параметрами:
- Рабочая станция на Windows 10
- доменная авторизация
- KES
- KEA
- KEDR
- KSC
- KUMA
- Установлен пакет правил SOC_package (см. пресейл пак или ссылку с архивом установки KUMA)
- Настроена интеграция с AD
- Настроена интеграция с KSC
- Настроена интеграция с KEDR
В рамках стенда условный нарушитель, заметив незаблокированный компьютер администратора, воспользовался случаем и выполнил зловредные действия:
- Скачал вредоносный файл со своего сервера
- Выполнил команду для создания ключа реестра в ветке Microsoft\Windows\CurrentVersion\Run
- Добавил скаченный файл в автозапуск с помощью реестра
- Выполнил очистку событий в журнале Security
- Вышел из сессии, чтобы владелец учетной записи ничего не заподозрил
- Владелец учетной записи вошел в систему, послу чего запустился вредоносный файл
Процесс мониторинга
В процессе мониторинга с рабочей станции поступили события из журнала Security, после чего сработали правила корреляции из пакета SOC_package.
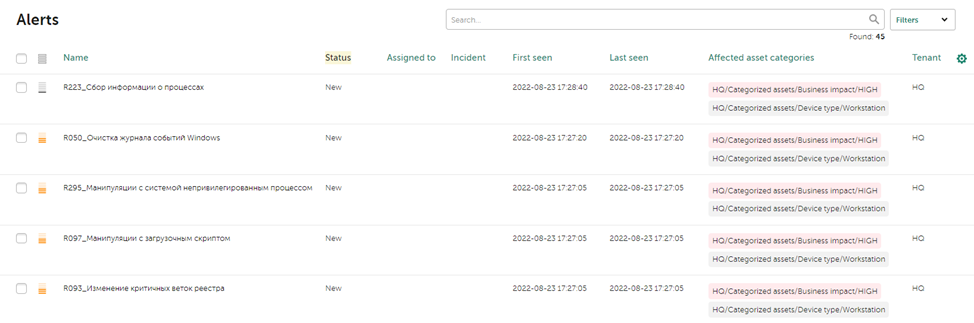
Каждый алерт имеет название правила корреляции, которое его породило. При повторном срабатывании правила в поле First seen будет время первого события, а в Last seen последнего.
Triage
При появлении нового алерта срабатывает правило оповещения и отправляется письмо на почту группе реагирования или конкретному аналитику.
Аналитики из L1 переходит по ссылке из письма и попадает сразу на карточку первого алерта:
Взятие в работу L1
Аналитик берет в работу алерт, назначая его на себя.
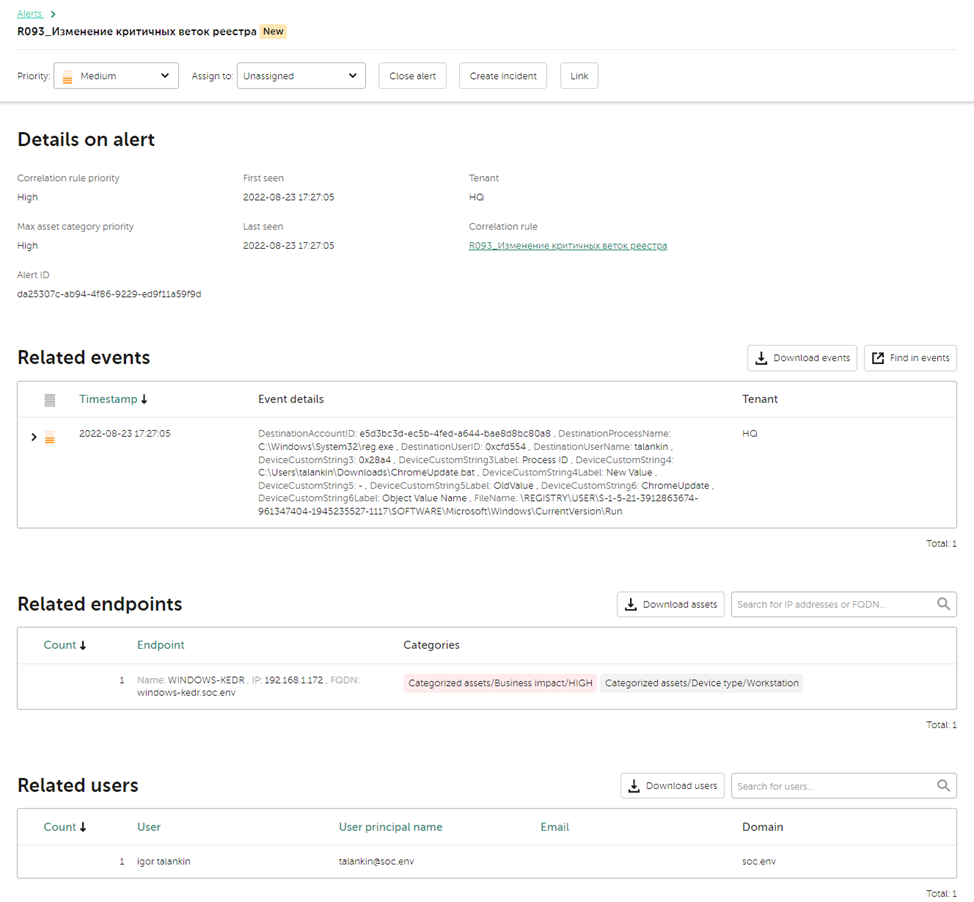
Анализ алерта
При анализе алерта аналитик обращает внимание на то какое правило сработало и соответствуют ли данные из событий с самим правилом. Как видно из названия правила алерт сработал на изменение какой-то критичной ветки реестра, в поле Related events в событии присутствуют путь до ключа реестра, есть старое и новое значение ключа реестра, отсюда можно сделать вывод, что правило соответствует произошедшему событию и аналитик обладает достаточной экспертизой, чтобы продолжить реагирование. Иначе же аналитик может перевести алерт на L2, назначив его на другого аналитика.
Проверка достаточности данных
На данном этапе аналитик должен определить каких данных ему будет достаточно для дальнейшего расследования. Чтобы продолжить расследование в рамках алерта по несанкционированному изменению ветки реестра, необходимо точно знать какой ключ был изменен и на каком хосте это было сделано. Дополнительными полезными данными будет информация о том, кто это сделал и новое значение ключа реестра. Раскрыв дерево событий от верхнеуровневого правила до самого события, можно увидеть детали, нажав на интересующее событие.
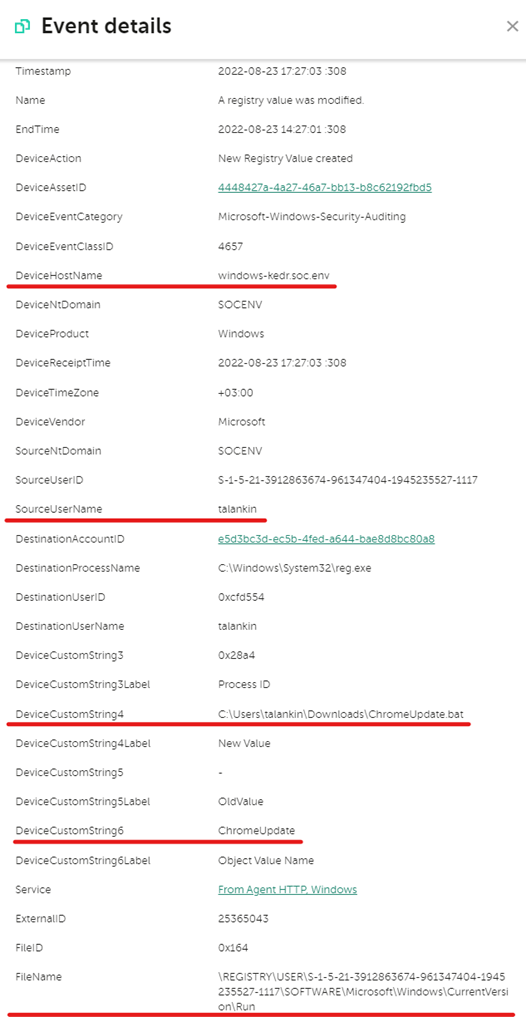
Проверка на False Positive
В рамках проверки на ложное срабатывание аналитик должен проверить верно ли сработало правило, может ли быть такая активность легитимной в связи с нормальной работой системы (например, обновление). Проанализировав детали события, видно, что персональная учетная запись talankin выполнила создание ключа реестра с помощью утилиты reg.exe, а также ключ реестра был создан в ветке \Microsoft\Windows\CurrentVersion\Run, отвечающей за автозапуск программ при входе пользователя в систему. Эти данные дают понять, что алерт скорее всего является True Positive и можно продолжить анализ дальше.
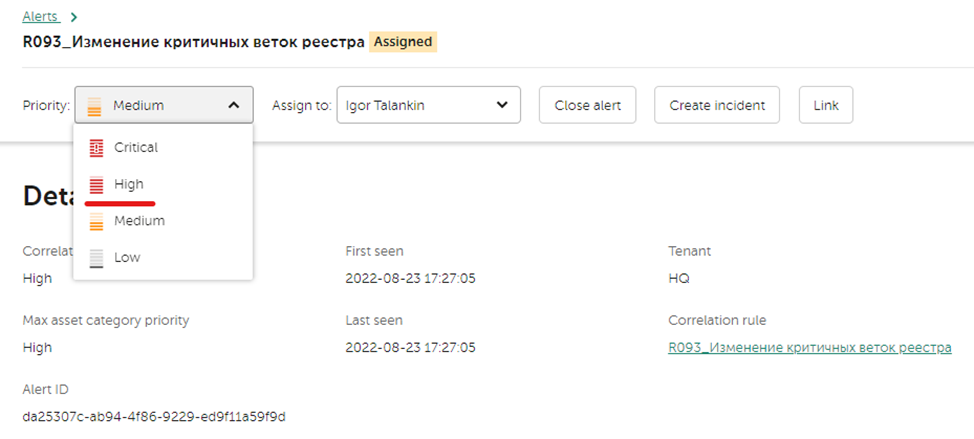
Определение критичности
На стадии определения критичности нужно валидировать критичность, которая была проставлена автоматически либо скорректировать её. Исходя из данных алерта имеет смысл выставить высокую критичность для данного алерта:
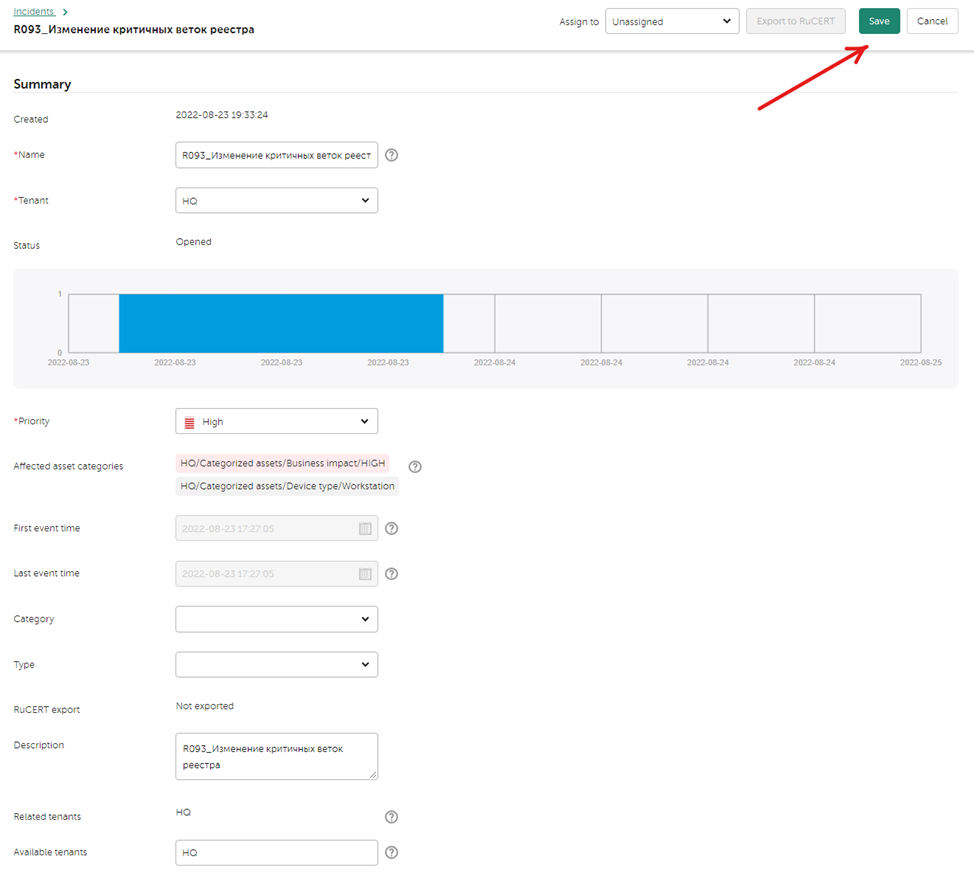
Создание инцидента
Проведя действия в рамках триажа, аналитик может эскалировать алерт до инцидента, чтобы начать расследование. Для этого в карточке инцидента необходимо нажать Create incident, в появившемся окне заполнить необходимые поля и нажать Save:
Расследование
Сбор информации о затронутых активах
Информация о затронутых активах автоматически выделяется в поля инцидента Related endpoints и Related users в том случае, если данные об этих активах загружены в KUMA с помощью интеграции с KSC, AD или внесены вручную. В изображении ниже видно, что в рамках инцидента были затронуты хост windows-kedr и учетная запись пользователя igor talankin.
Сразу можно отметить, что хост находится в категориях Business impact/HIGH и Device type/Workstation, то есть мы имеем дело с рабочей станцией, которая является критичной для нашей инфраструктуры (по легенде рабочая станция принадлежит администратору).
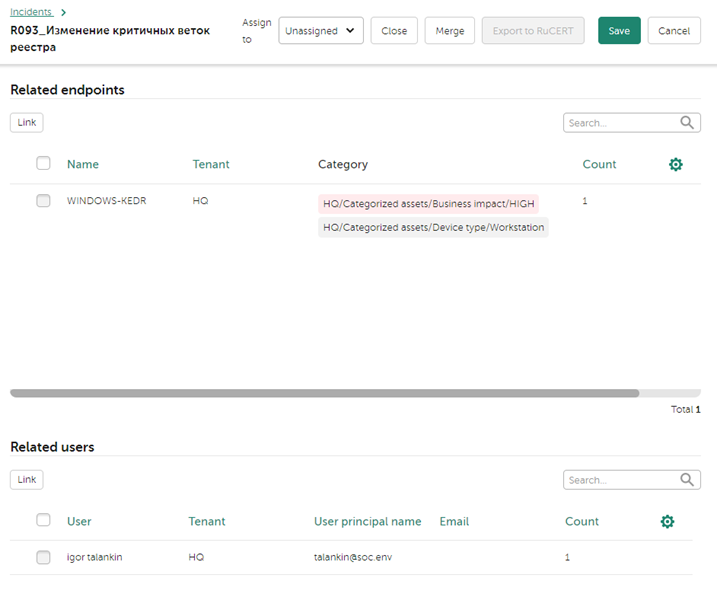
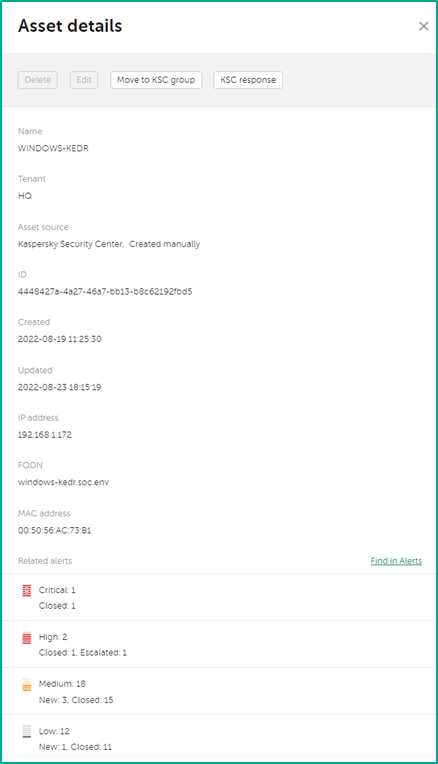
Если нажать на хост, то появятся детали актива. Детали содержат довольно подробную информацию, куда входит:
- FQDN, IP адрес, MAC адрес, время создания и обновления информации
- Количество алертов с разделением по критичности, с которыми этот актив связан. Также есть возможность сразу перейти к этим алертам, для поиска дополнительной информации в рамках инцидента.
- Категории, к которым относится актив
- Уязвимости на хосте
- Информация об установленном ПО
- Информация о hardware
- Другая дополнительная информация
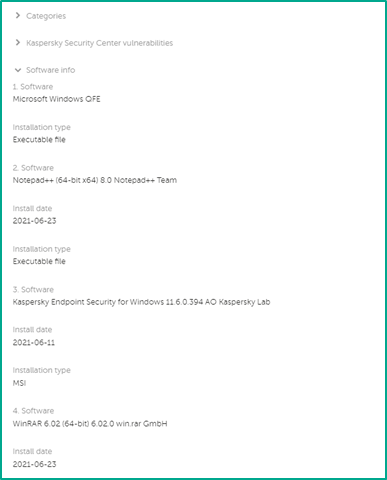
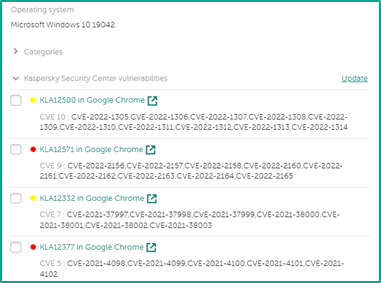
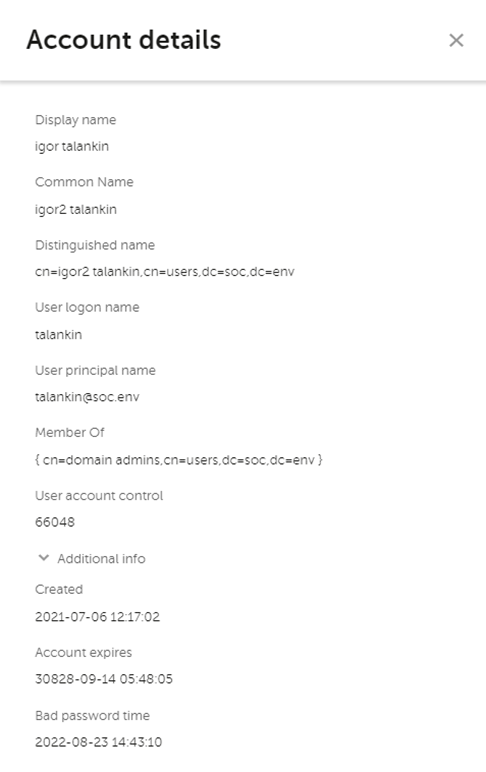
Если нажать на связанную учетную запись, то можно изучить данные о ней по информации из Active Directory:
- Имя пользователя
- Имя учетной записи
- Группы, в которых состоит учетная запись
- Дата истечения пароля, дата создания и время последнего неверного ввода пароля
- Другая информация из AD
Как видно из списка групп, учетная запись состоит в группе доменных администраторов, что подтверждает высокую критичность инцидента.
Определение скоупа
Для определения скоупа инцидента необходимо произвести расследование и выявить по возможности другие события и алерты, которые относятся к этой злонамеренной активности.
Привязка события к инциденту возможна только через алерт (при этом алерт перед изменениями в т.ч. добавления новых событий в него, необходимо отвязать от инцидента).
Поиск связанных алертов
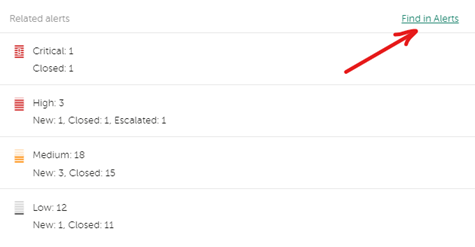
Первым делом имеет смысл проверить другие алерты, которые происходили с затронутыми активами.
Для этого достаточно выбрать актив и в разделе со связанными алертами нажать Find in alerts.
В окне с алертами можно сделать фильтрацию по времени или статусу, чтобы исключит уже обработанные алерта или устаревшие:
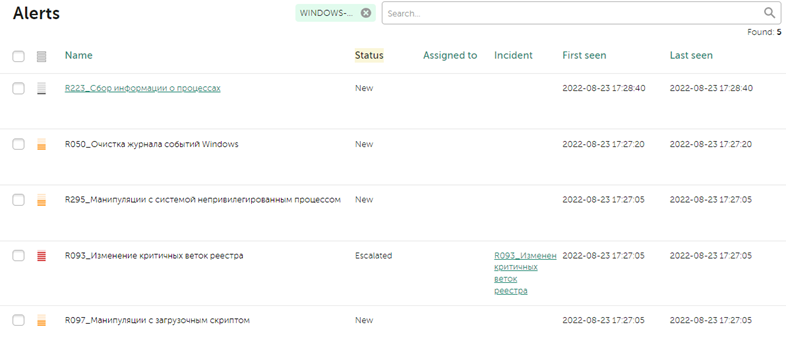
Как видно, с данным активом связаны и другие алерты. Судя по времени, в которое сработали алерты, мы можем сделать вывод, что все они так или иначе связаны друг с другом. Чтобы связать алерты с инцидентом, отмечаем интересующие алерты и нажимаем в нижней части панели Link, в появившемся окне отмечаем инцидент, с которым мы хотим связать алерты и снова нажимаем Link:
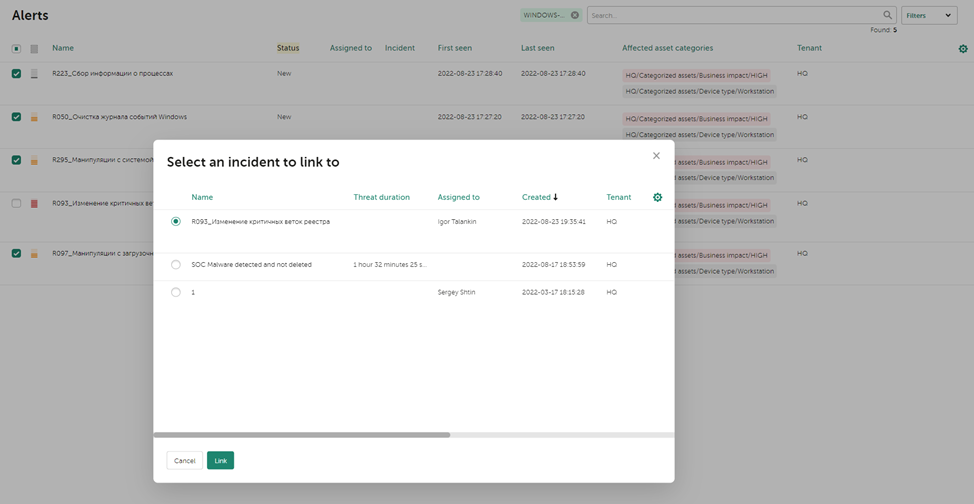
Перейдя обратно в карточку инцидента, мы можем убедиться, что все отмеченные алерты привязаны:
Ту же самую операцию мы можем провести с учетной записью и найти связанные алерты. В случае, если в новом алерте будут новые связанные активы, то мы можем продолжать поиск связанных алертов и по ним, тем самым расширяя скоуп расследования.
В случае, если мы обнаружили, что уже есть инцидент в работе, с которым мы можем объединить текущий инцидент, чтобы вести процесс реагирования в рамках одного инцидента, мы можем склеить их с помощью функции Merge. Для этого в карточке инцидента нужно нажать в верхней части на Merge, а затем выбрать инцидент, с которым мы хотим выполнить склеивание.
Threat hunting
После поиска связанных активов и алертов, можно приступить к более детальному расследованию и углубиться в поиск связанных c инцидентом IOC по всей инфраструктуре.
Для поиска связанных событий можно воспользоваться вкладкой Events и произвести поиск вручную или выбрать любой из связанных алертов и в его карточке нажать Find in events. Данный функционал называется Drilldown analysis:
В появившемся окне с событиями мы можем искать события и сразу же связывать их с выбранным алертом (для привязки алерта он должен быть отвязан от инцидента). Для этого необходимо в верхней части выбрать Search events -> All events:
В результате поиска, нам удалось найти команду, которую выполнил злоумышленник, чтобы создать новый ключ реестра. Исходя из данных события, мы можем найти какой процесс был родительским для reg.exe, им окажется cmd.exe, то есть злоумышленник запустил командную строку и выполнил команду в ней.
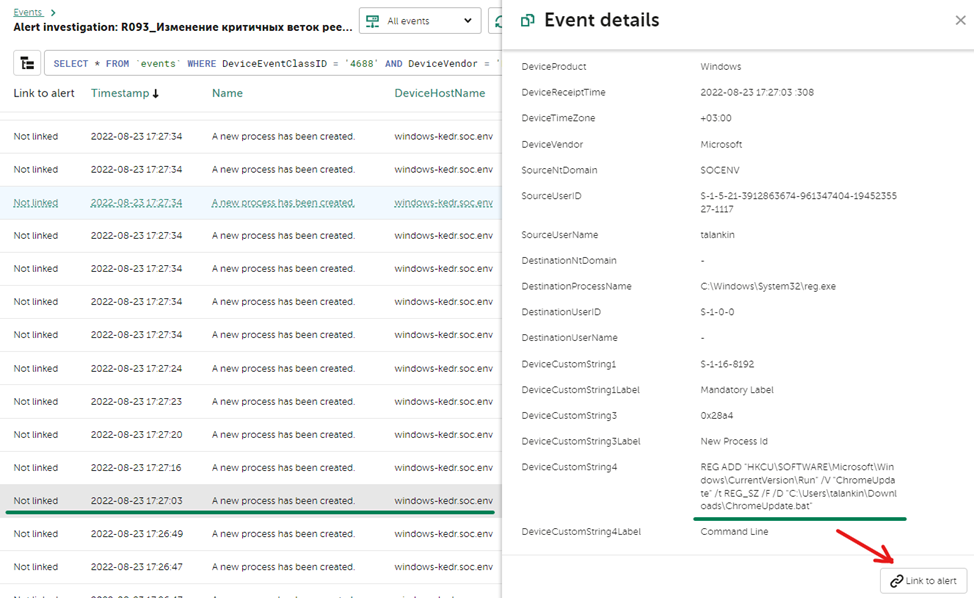
Из этого события появляется информация о некотором файле ChromeUpdate.bat. Чтобы узнать происхождение этого файла, мы можем продолжить процесс поиска, выполнив поиск по FileName = ‘C:\\Users\\talankin\\Downloads\\ChromeUpdate.bat’ и по маске доступа %%4417 (тип доступа WriteData (or AddFile)). В результате поиска мы найдем, что файл был создан процессом msedge.exe, чтобы говорит о том, что файл был скачен из внешнего источника, для дальнейшего анализа уже потребуются события с proxy сервера или NGFW. Это событие мы также привязываем к нашему алерту.

В ходе расследования мы можем выявить новые индикаторы компрометации такие как имя файла, URL, IP адрес и т.д., по этим данным также стоит выполнить поиск ретроспективный анализ, в результате которого можно выявить новые затронутые активы и обнаружить новые следы присутствия злоумышленника. В данном инциденте имеет смысл выполнить поиск файла ChromeUpdate.bat в событиях за последние пару недель.
Произведя Threat hunting для каждого алерта, мы должны выявить всю цепочку атаки.
Определение причин инцидента
По результатам поиска связанных событий мы выявили причины инцидента и можем записать результаты нашего анализа в журнал в карточке инцидента, чтобы передать информацию другим аналитикам или для полноты описания всего процесса реагирования. В разделе Change log мы можем указать важную информацию:

Реагирование
После расследования, у нас есть информация о затронутых активах, а также об индикаторах компрометации, которая поможет в сдерживании. Исходя из типа инцидента требуется определить список действий, которые нужно выполнить, чтобы остановить ход атаки. В данном случае имеет смысл:
- Запустить внеплановое антивирусное сканирование затронутых систем
- Изолировать хост от сети до момента, пока мы не убедимся в безопасности данного хоста
- Добавить файл ChromeUpdate.bat в карантин и создать правила предотвращающее его запуск на других хостах в инфраструктуре
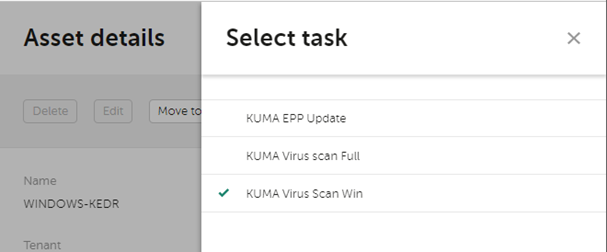
Антивирусной сканирование
Для запуска сканирования в рамках этого инцидента необходимо перейти в карточку инцидента, выбрать затронутый хост и в верхней части информации об активе выбрать KSC Response и отметить заранее пред настроенную задачу по сканированию, а затем нажать Start.
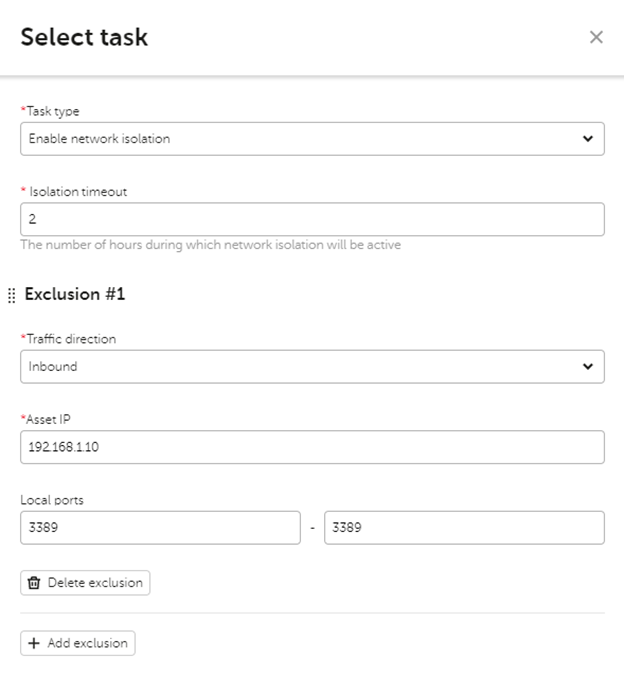
Сетевая изоляция хоста
Для изоляции хоста, необходимо повторить действия для выбранного хоста, но выбрать KEDR Response, затем в Task type выбрать Enable network isolation и заполнить дополнительный параметры при необходимости, например, уточнить время изоляции или исключения в случае необходимости иметь доступ к хосту во время изоляции.
Предотвращение запуска вредоносного файла
Для добавления файла в карантин и создания превентивного правила с запретом запуска данного файла (в случае, если файл исполняемый) нужно повторить действия и выбрать KEDR Response -> Task type: Add preventive rule, в поле File hash указать хэш файла. В поле Asset имеет смысл указать All assets, так как нам необходимо застраховаться от дальнейшего распространения вредоносного файла.

Восстановление
После выполнения всех действий по расследованию и сдерживанию инцидента, а также после очистки инфраструктуры от следов злоумышленника, можно приступить к восстановлению нормальной работоспособности всех систем. Для это может понадобиться отключить какие превентивные правила на EDR или убрать сетевую изоляцию, если она не отключится автоматически. Чтобы выполнить эти действия, необходимо повторить действия подобные тем, что были произведены на предыдущем этапе, только выбрать задачи Disable network isolation и Delete prevention rule.
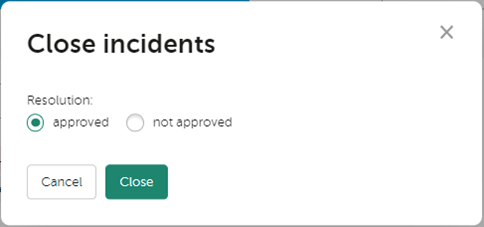
Закрытие инцидента
В конце процесса реагирования мы можем закрыть инцидент, выбрав один из вариантов заключения: approved или not approved. Чтобы закрыть инцидент, необходимо в верхней части карточки инцидента выбрать Close incident, в появившемся окне отметить нужный вариант и выбрать Close:
Закрытый инцидент нельзя «пере»-открыть.
Пошаговое руководство по разработке сценариев реагирования
Пример работы KUMA в тандеме с другими решениями на кейсе
Как использовать MITRE ATT&CK в SOC

Использование MITRE ATT&CK в Центре управления безопасностью (SOC) может значительно расширить возможности обнаружения угроз и реагирования на них.
Правила корреляции из коробки в KUMA (SOC Package и Community-Pack) покрываются техниками и тактиками из матрицы MITRE ATT&CK
Обогащение Техниками и Тактиками на корреляторе
Для актуальных версий: Воспользуйтесь справкой - https://support.kaspersky.com/help/KUMA/3.2/ru-RU/272743.htm
Скачайте справочник техник MITRE ATT&CK на портале GitHub

Должно получиться следующее:
Подгрузите файл сюда Параметры - Общие - Настройки списка техник MITRE:
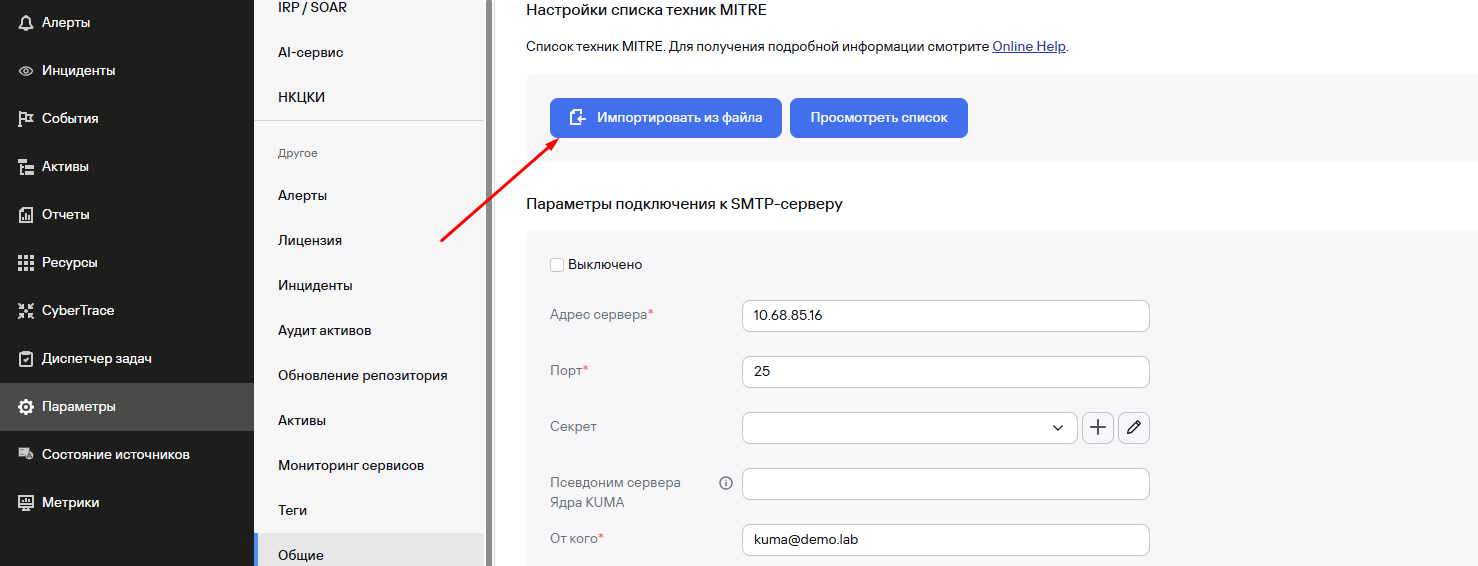
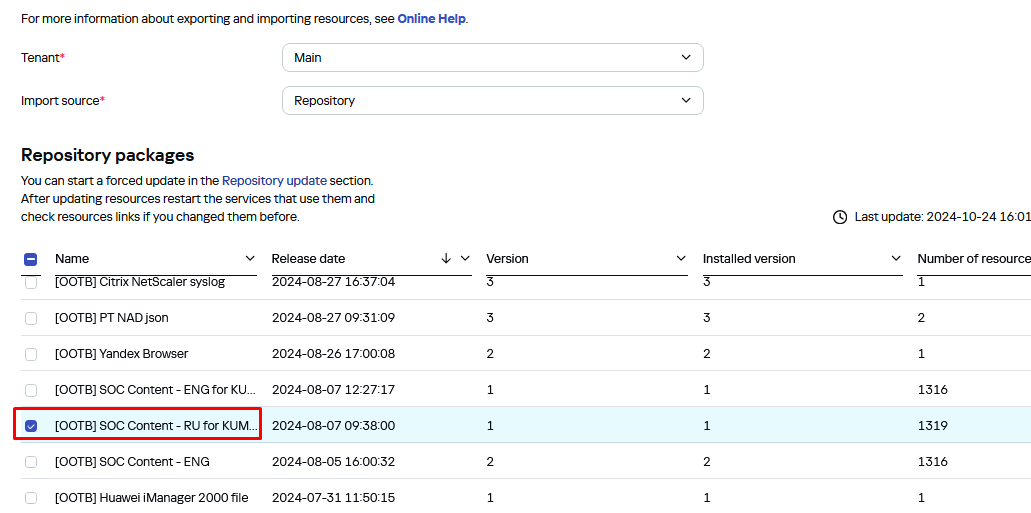
Загрузите следующий пакет правил из репозитория:
Для обогащения техниками и тактиками в событии добавьте словарь в обогащении на корреляторе KUMA:

Ниже шаги для эффективного использования в SOC:
Ознакомьтесь с MITRE ATT&CK
- Понять назначение и структуру платформы MITRE ATT&CK. Может помочь эта статья на русском: https://xakep.ru/2021/03/17/mitre-att-ck/
- Посетите веб-сайт ATT&CK (https://attack.mitre.org/) и ознакомьтесь с матрицей ATT&CK, техниками, тактиками и подтехниками.
Сопоставьте ATT&CK с вашей средой
- Определите соответствующие методы и тактики MITRE ATT&CK, соответствующие инфраструктуре, процессам, приложениям и данным вашей организации.
- Сопоставьте методы MITRE ATT&CK с вашими существующими средствами безопасности, такими как МЭ, системы обнаружения вторжений, решения для защиты конечных точек и др.
Создайте правила обнаружения
- Разработайте правила обнаружения и варианты использования на основе конкретных методов и тактик MITRE ATT&CK.
- Используйте свою систему SIEM или платформы аналитики угроз для создания правил, создающие оповещения при обнаружении подозрительных действий, связанных с определенными методами ATT&CK.
Реализуйте поиск угроз (Threat Hunting)
- Используйте MITRE ATT&CK в качестве руководства для упреждающих упражнений по поиску угроз.
- Найдите индикаторы компрометации (IOC), связанные с известными методами ATT&CK, и используйте их для выявления потенциальных угроз в вашей среде.
Улучшайте реагирование на инциденты
- Включите MITRE ATT&CK в свои процедуры реагирования на инциденты.
- Разрабатывайте сценарии и планы реагирования, соответствующие конкретным методам и тактикам ATT&CK, чтобы эффективно справляться с угрозами и смягчать их последствия.
- Полезные материалы на русском:
- Примеры плейбуков - https://github.com/certsocietegenerale/IRM/tree/main/RU
- Руководство по реагирования ЛК - https://box.kaspersky.com/f/26b68439676f4739baa6/
- Примеры плейбуков - https://github.com/certsocietegenerale/IRM/tree/main/RU
Работайте с Threat Intelligence
- Используйте внешние источники информации об угрозах, соответствующие MITRE ATT&CK.
- Будьте в курсе последних отчетов об угрозах, в которых упоминаются методы и тактика ATT&CK.
- Полезные материалы:
- Бесплатный TI портал ЛК - https://opentip.kaspersky.com/
Пример работы
Находим технику
Например, нам интересен вектор атаки через планировщик задач, для этого можно воспользоваться поиском вверху справа на сайте https://attack.mitre.org/:
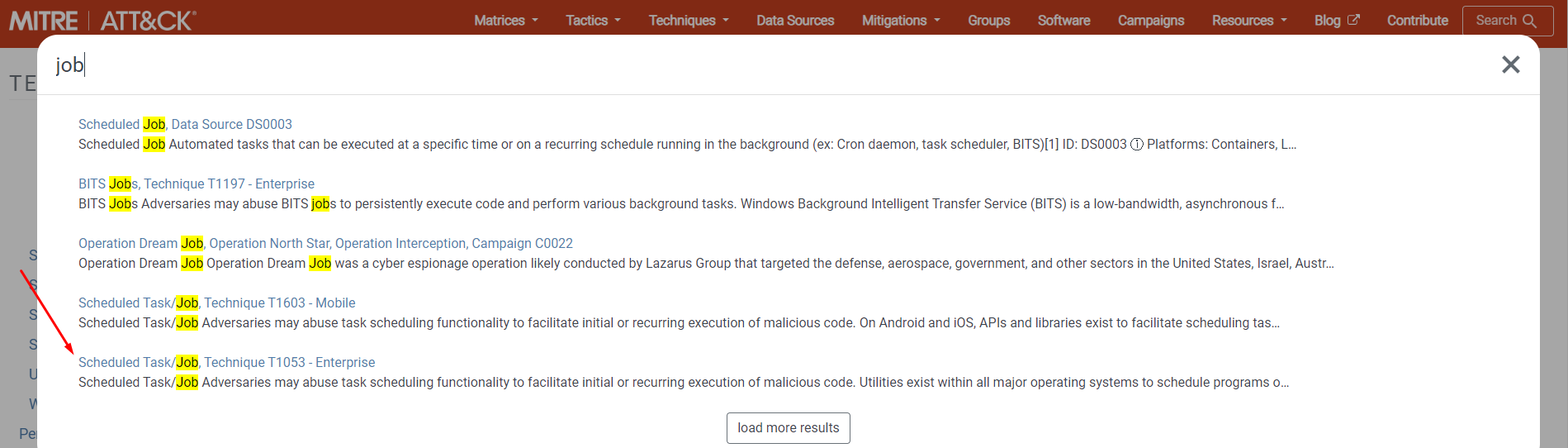
Переходим на интересующую тематику:
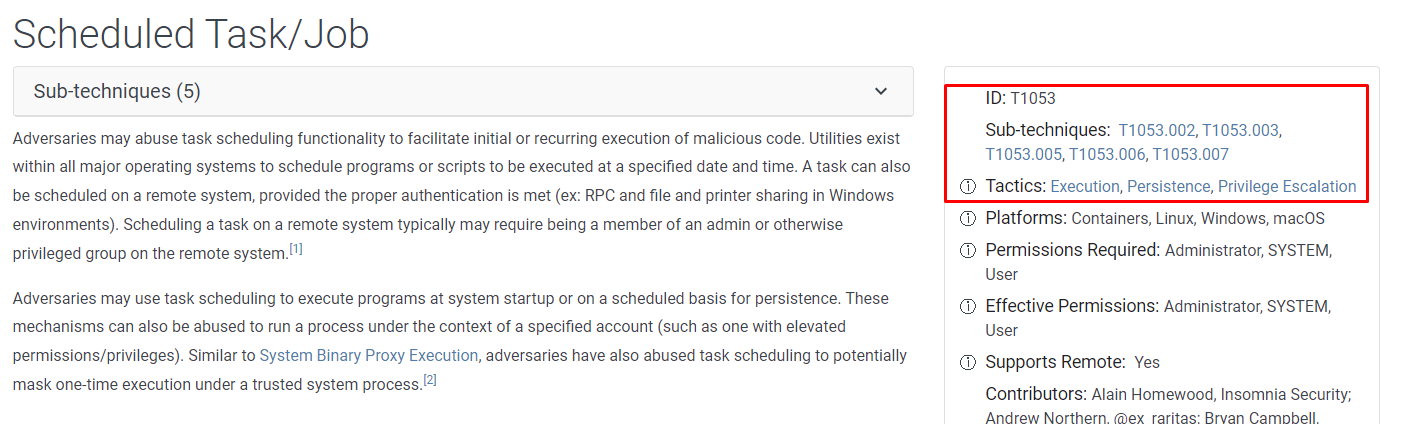
Изучаем материал
- Ознакомьтесь с общей структурой ATT&CK
- Найти параметры и инструменты, которые злоумышленник должен использовать для реализации ATT&CK.
- Поищите о технике или подтехнике на других ресурсах.
- Прочтите раздел «Примеры процедур» - Узнайте, как группы или инструменты используют технику или подтехнику.
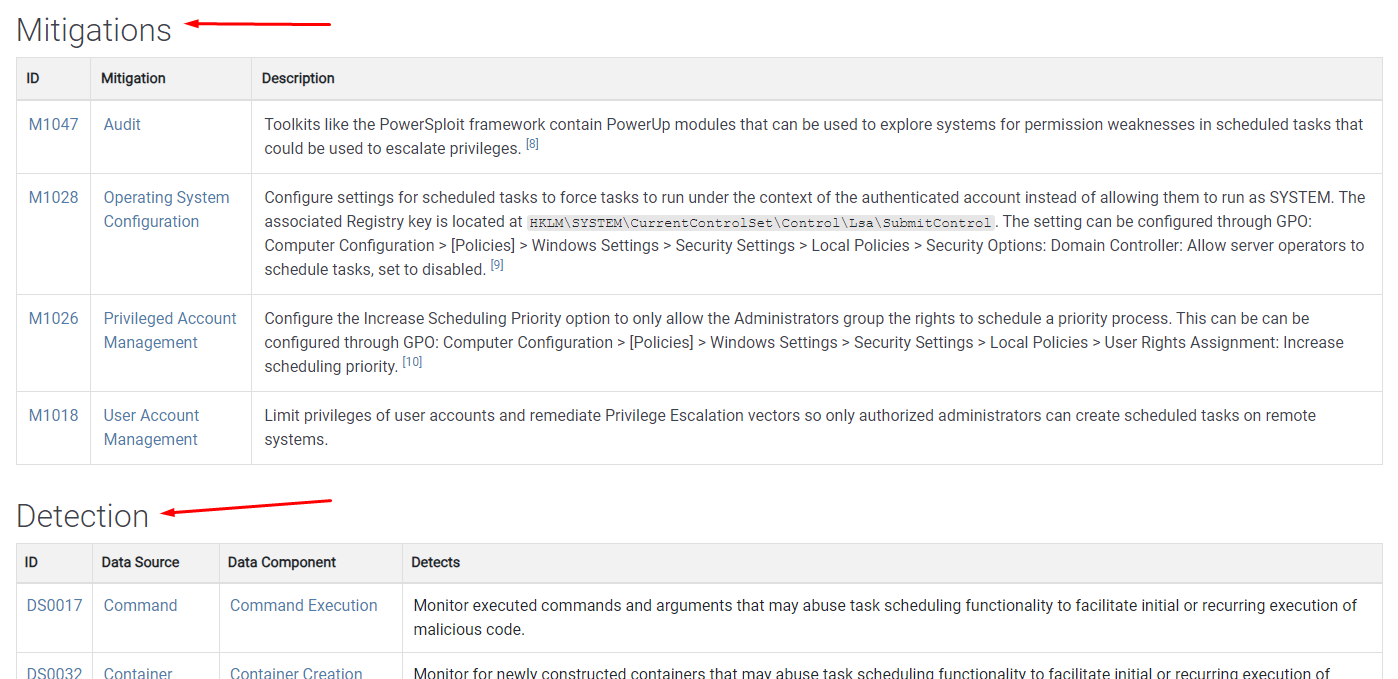
Изучаем меры защиты
- Раздел митигации (снижений последствий) - Найдите митигацию
- Раздел обнаружения - Найдите способы обнаружения этой техники
Преобразуйте TTP (Техники, Тактики и Процедуры) в правила в SIEM
- Найдите правило обнаружения в проекте MITRE CAR - https://car.mitre.org/analytics/by_technique
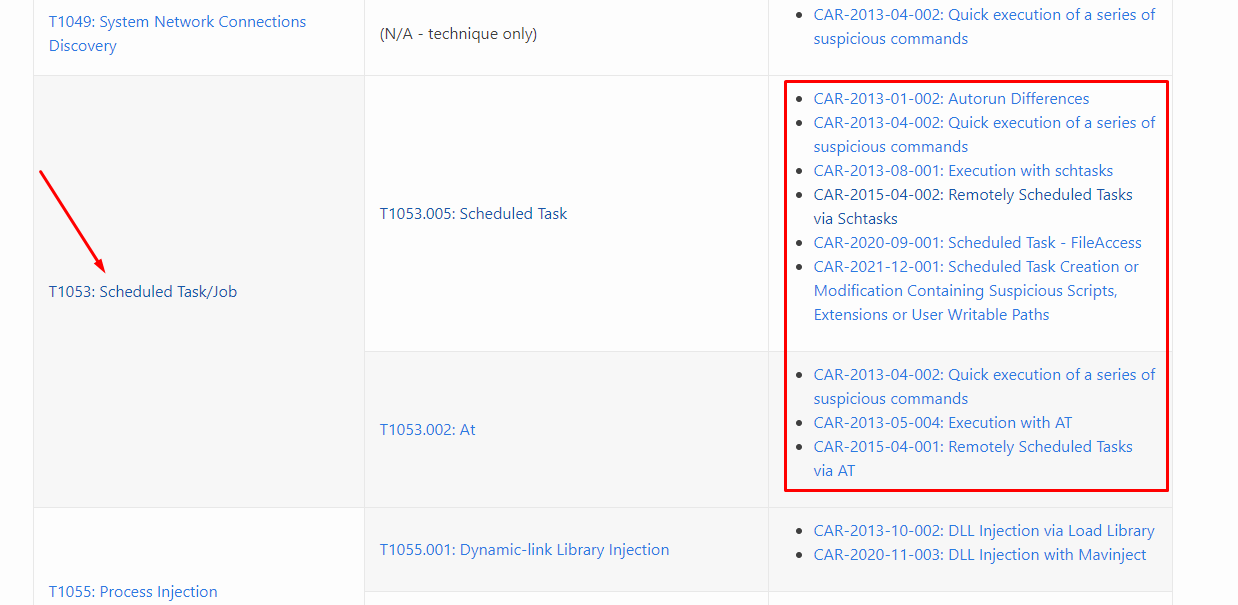
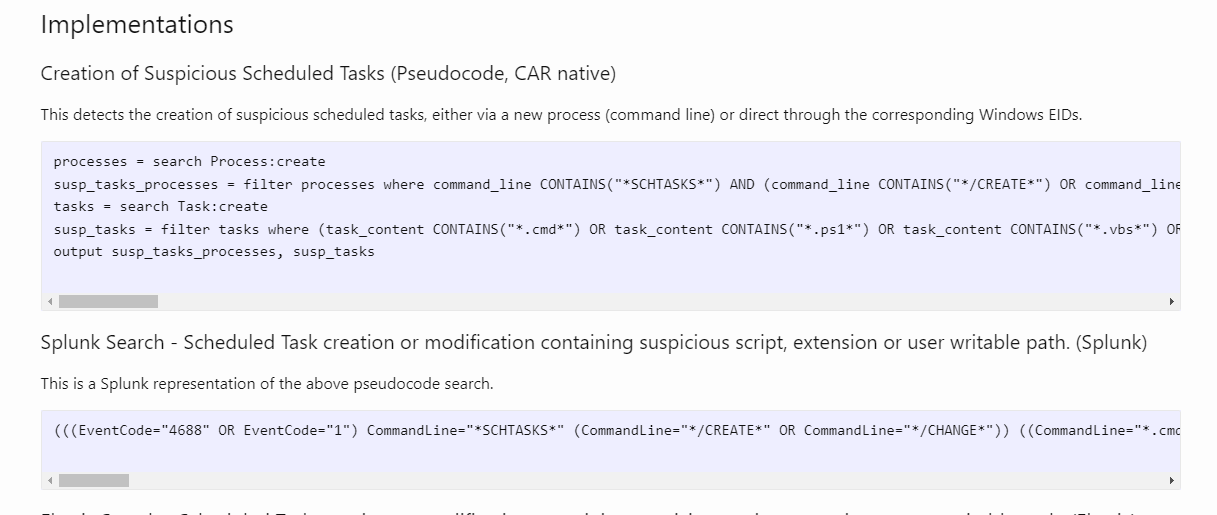
Например, такое правило MITRE CAR - Scheduled Task Creation or Modification Containing Suspicious Scripts, Extensions or User Writable Paths (https://car.mitre.org/analytics/CAR-2021-12-001/). В нем можно увидеть множество вариаций правил, как в псевдокоде, так и в популярных зарубежных SIEM системах.
ATT&CK Navigator
Как слушать коллектором порты меньше 1024
Редактирование файла сервиса
В связи с особенностью функционирования Unix-систем для прослушивания портов с номерами ниже 1024 нужны дополнителльные права.
Для того, чтобы дать сервису соответствующие права выполните следующие действия:
1. Остановите выполнение сервиса коллектора командой
systemctl stop kuma-collector-<id>2. Откройте на редактирование файл службы коллектора
systemctl edit kuma-collector-<id>.service3. В разделе [Service] добавьте следующую строку. Если раздел отсутствует, то нужно его добавить.
AmbientCapabilities=CAP_NET_BIND_SERVICE4. Сохраните полученный файл
5. Обновите параметры сервисов следующей командой
systemctl daemon-reload6. Запустите службу коллектора следующей командой
systemctl start kuma-collector-<id>Где брать официальный контент для KUMA? (Обновление контента)
Начиная с версии KUMA 2.1 контент от Лаборатории Касперского (правила корреляции, нормализаторы, коннекторы и т.п.) публикуются в репозитории ЛК: https://support.kaspersky.com/help/KUMA/4.0/ru-RU/250594.htm
Возможно также офлайн обновление с помощью утилиты KUU - https://kb.kuma-community.ru/books/ustanovka-i-obnovlenie/page/obnovlenie-resursov-s-pomoshhiu-kaspersky-update-utility-kuu
Как получить SOC Package и другой коробочный контент?
1. В Web-интерфейсе KUMA нужно настроить интеграцию с репозиторием

Список серверов, до которых нужно предоставить доступ с KUMA представлен в официальной документации: https://support.kaspersky.ru/common/start/6105
Для обновления напрямую с репозитория НЕЛЬЗЯ использовать Proxy для KUMA < 3.4. Если для доступа к репозиторию требуется использование Proxy или у KUMA нет доступа в Интернет напрямую, то следует использовать Kaspersky Update Utility (KUU). Подробнее в статье: https://kb.kuma-community.ru/books/ustanovka-i-obnovlenie/page/obnovlenie-resursov-s-pomoshhiu-kaspersky-update-utility-kuu
2. После настройки интеграции с репозиторием и Запуска обновления перейдите в Ресурсы и выберите Импортировать ресурсы

3. Далее выберите Репозиторий в качестве источника

Контент в системе применяется сверху вниз, проверяйте, что выбирается к применению, чтобы иметь актуальный набор ресурсов
4. Нажав на имя конкретного пакета, вы увидите информацию о пакете, журнал изменений и перечень импортируемых ресурсов.
Информация о пакете

Пакеты для начальной установки
- Щелкните на столбец Название в пакетах репозитория и отсортируйте по Возрастанию
- Загрузите ресурс, например
[OOTB] KUMA 4.0 resources, в соответствии с вашей версией KUMA - Для детектирования загрузите:
- Правила корреляции -
[OOTB] SOC Content - RU - Правила корреляции мониторинг событий Kaspersky Security Center -
[OOTB] KSC Package - RU - Правила корреляции мониторинг событий Kaspersky Security Mail Gateway -
[OOTB] KSMG Package - RU - (Опционально) Правила корреляции, направленные на соблюдение требований стандарта PCI DSS. -
[OOTB] PCIDSS - RU - Правила поведенческого анализа -
[OOTB] UEBA package - RU - Правила для выявления аномалий в сетевой активности -
[OOTB] Network Package - RU - Правила межпродуктовые в рамках экосистемы Kaspersky -
[OOTB] XDR package - RU - Загрузите (с помощью кнопки Привязать) эти правила в имеющуюся службу коррелятора (встроенные правила OOTB удалите)
- Правила корреляции -
Описание пакетов на странице справки https://support.kaspersky.com/help/KUMA/4.0/ru-RU/250594.htm
5. Для импорта интересующих ресурсов выберите один или несколько пакетов галочкой слева от имени пакета и нажмите Импортировать внизу окна

6. Выбранные ресурсы будут импортированы.
Где взять описание правил из SOC Package?
Описание правил из SOC Package можно скачать из официальной документации: https://support.kaspersky.com/help/KUMA/3.4/ru-RU/250594.htm

Альтернативно, можно воспользоваться интерактивной библиотекой правил по ссылке
На что ориентируемся при разработке правил
Вширь:
- Покрытие матрицы MITRE
- Покрытие новых источников событий
Вглубь
- Отчет MDR Report
- Отчет IR Report (GERT)
- Отчет Threat Landscape Report
- Внутренняя экспертиза (EDR, MDR)
Ad-hoc
- Интересные публикации в блогах и телеграмм-каналах
- Замечания/предложения пользователей
Где взять мапинг коробочных нормализаторов?
Сопоставление полей коробочных нормализаторов можно скачать из официальной документации: https://support.kaspersky.com/help/KUMA/3.4/ru-RU/267237.htm

Форматы времени, которые понимает KUMA
May 8, 2009 5:57:51 PM
oct 7, 1970
oct 7, '70
oct. 7, 1970
oct. 7, 70
Mon Jan 2 15:04:05 2006
Mon Jan 2 15:04:05 MST 2006
Mon Jan 02 15:04:05 -0700 2006
Monday, 02-Jan-06 15:04:05 MST
Mon, 02 Jan 2006 15:04:05 MST
Tue, 11 Jul 2017 16:28:13 +0200 (CEST)
Mon, 02 Jan 2006 15:04:05 -0700
Mon 30 Sep 2018 09:09:09 PM UTC
Mon Aug 10 15:44:11 UTC+0100 2015
Thu, 4 Jan 2018 17:53:36 +0000
Fri Jul 03 2015 18:04:07 GMT+0100 (GMT Daylight Time)
Sun, 3 Jan 2021 00:12:23 +0800 (GMT+08:00)
September 17, 2012 10:09am
September 17, 2012 at 10:09am PST-08
September 17, 2012, 10:10:09
October 7, 1970
October 7th, 1970
12 Feb 2006, 19:17
12 Feb 2006 19:17
14 May 2019 19:11:40.164
7 oct 70
7 oct 1970
03 February 2013
1 July 2013
2013-Feb-03
// dd/Mon/yyy alpha Months
06/Jan/2008:15:04:05 -0700
06/Jan/2008 15:04:05 -0700
// mm/dd/yy
3/31/2014
03/31/2014
08/21/71
8/1/71
4/8/2014 22:05
04/08/2014 22:05
4/8/14 22:05
04/2/2014 03:00:51
8/8/1965 12:00:00 AM
8/8/1965 01:00:01 PM
8/8/1965 01:00 PM
8/8/1965 1:00 PM
8/8/1965 12:00 AM
4/02/2014 03:00:51
03/19/2012 10:11:59
03/19/2012 10:11:59.3186369
// yyyy/mm/dd
2014/3/31
2014/03/31
2014/4/8 22:05
2014/04/08 22:05
2014/04/2 03:00:51
2014/4/02 03:00:51
2012/03/19 10:11:59
2012/03/19 10:11:59.3186369
// yyyy:mm:dd
2014:3:31
2014:03:31
2014:4:8 22:05
2014:04:08 22:05
2014:04:2 03:00:51
2014:4:02 03:00:51
2012:03:19 10:11:59
2012:03:19 10:11:59.3186369
// Chinese
2014年04月08日
// yyyy-mm-ddThh
2006-01-02T15:04:05+0000
2009-08-12T22:15:09-07:00
2009-08-12T22:15:09
2009-08-12T22:15:09.988
2009-08-12T22:15:09Z
2017-07-19T03:21:51:897+0100
2019-05-29T08:41-04 // no seconds, 2 digit TZ offset
// yyyy-mm-dd hh:mm:ss
2014-04-26 17:24:37.3186369
2012-08-03 18:31:59.257000000
2014-04-26 17:24:37.123
2013-04-01 22:43
2013-04-01 22:43:22
2014-12-16 06:20:00 UTC
2014-12-16 06:20:00 GMT
2014-04-26 05:24:37 PM
2014-04-26 13:13:43 +0800
2014-04-26 13:13:43 +0800 +08
2014-04-26 13:13:44 +09:00
2012-08-03 18:31:59.257000000 +0000 UTC
2015-09-30 18:48:56.35272715 +0000 UTC
2015-02-18 00:12:00 +0000 GMT
2015-02-18 00:12:00 +0000 UTC
2015-02-08 03:02:00 +0300 MSK m=+0.000000001
2015-02-08 03:02:00.001 +0300 MSK m=+0.000000001
2017-07-19 03:21:51+00:00
2014-04-26
2014-04
2014
2014-05-11 08:20:13,787
// yyyy-mm-dd-07:00
2020-07-20+08:00
// mm.dd.yy
3.31.2014
03.31.2014
08.21.71
2014.03
2014.03.30
// yyyymmdd and similar
20140601
20140722105203
// yymmdd hh:mm:yy mysql log
// 080313 05:21:55 mysqld started
171113 14:14:20
// unix seconds, ms, micro, nano
1332151919
1384216367189
1384216367111222
1384216367111222333Как перенести KUMA на другой диск
Кейс 1. Диск смонтирован в неверный раздел
Предположим, при подготовке сервера диск, предназначенный для хранения примонтировали не верно, например в папку /var/data. KUMA установлена в папку /opt
Запись в /etc/fstab выглядит примерно следующим образом
/dev/sdb1 /var/data xfs defaults 0 0Последовательность действий будет следующая
1. Останавливаем сервисы kuma-*
systmctl stop kuma-*2. Переносим данные из /opt/kaspersky/kuma в /var/data/kaspersky/kuma
3. Отмонтируем папку /var/data
umount /var/data4. Редактируем /etc/fstab, что бы там была такая запись
/dev/sdb1 /opt xfs defaults 0 05. Выполняем команду
mount -a6. Проверяем, что файловая структура /opt/kaspersky/kuma корректна, проверяем, что на всех папках owner kuma:kuma, если нет, то можно запустить команду
chown -R kuma:kuma /opt/kaspersky/kuma7. Стартуем сервисы kuma-*
systemctl start kuma-*Кейс 2. Появилась возможность подключить большой диск
Предположим, при подготовке сервера, для папки /opt был выделен диск sdb размером 1 ТБ, но теперь есть возможность подключить диск sdc размером 12 Тб
Запись в /etc/fstab выглядит примерно следующим образом
/dev/sdb1 /opt xfs defaults 0 0Последовательность действий будет следующая
1. Останавливаем сервисы kuma-*
systmctl stop kuma-*2. Отмонтируем диск /dev/sdb1 из /opt и монтируем в какой-то иной раздел, например в /mnt/old_opt
mkdir /mnt/old_opt && umount /opt && mnt /dev/sdb1 /mnt/old_opt3. Редактируем /etc/fstab, что бы там была такая запись
/dev/sdc1 /opt xfs defaults 0 04. Запускаем команду монтирования
mount -a5. Создаем структуру папок /opt/kaspersky/kuma
6. Переносим данные из /mnt/old_opt/kaspersky/kuma в папку /opt/kaspersky/kuma. Проверяем иерархию папок, убеждаемся, что на всех папках owner kuma:kuma, если нет, то можно запустить команду:
chown -R kuma:kuma /opt/kaspersky/kuma7. Стартуем сервисы kuma-*
systemctl start kuma-*8. Отмонтируем старый не нужный диск
Лайфхаки для шаблонов
В KUMA во многих местах можно использовать шаблоны для обогащения. Но мало кто знает, что в template можно использовать не только значения полей, например, {{.DeviceAddress}}, но и другой функционал шаблонов GO (ссылка).
Ниже приведем несколько полезных лайфхаков, которые сделают ваши события красивыми и упростят обогащение и корреляцию.
Простое обогащение
Обогащать события можно не только классическими полями, например, {{.DeviceAddress}}, но и полями Extra, а также переменными.
Шаблон с обычными полем:
{{.DeviceAddress}}Шаблон с Extra полем:
{{index .Extra "myField"}}Шаблон с переменными (в функциях переменных):
template('Значения локальных переменных {{index . 0}} и {{index . 1}} а также {{index . 2}}', $var1, $var2, $var10)Обогащение с условиями
Чтобы в message вставить текст "Пользователь user1 на хосте user1-pc.local (10.10.10.10) выполнил команду 'whoami'", а hostname и address не всегда могут быть указаны, но хочется красивую надпись без пустых скобок или лишних пробелов, то можно использовать условия:
Пользователь {{.DestinationNtDomain}}\{{.DestinationUserName}} на хосте {{if and .DeviceAddress .DeviceHostName}} {{.DeviceHostName}} ({{.DeviceAddress}}) {{else if .DeviceAddress}} {{.DeviceAddress}} {{ else }} {{.DeviceHostName}} {{ end }} выполнил команду "{{.DeviceCustomString4}}"Такой же шаблон можно создать и с Extra-полями. Например, в поле события DeviceProcessName нужно записать значение из Extra-поля myField1, а в случае его отсутствия - myField2:
{{if index .Extra "myField1"}}{{index .Extra "myField1"}}{{else}}{{index .Extra "myField2"}}{{end}}Еще пример:
{{if eq .DeviceCustomString1 "" }}{{""}}{{else}}{{"vlan"}}{{end}}Также пример с использованием логических операторов and и or:
{{if and (eq .DeviceEventCategory "Application") ((or (eq .DeviceCustomString4 "MSSQL") (eq .DeviceCustomString4 "SQLISPackage")))}}{{.DestinationUserName}}{{end}}Еще пример:
{{if and ((eq .DeviceCustomIPv6Address2 "") (not (eq .SourceAddress ""))) }}{{.SourceAddress}}{{else}}{{.DeviceCustomIPv6Address2}}{{end}}Использование шаблонов с корреляционными правилами
В правилах standard можно в шаблоне указать количество базовых событий, которые попали в окно корреляции:
{{ len (.BaseEvents) }}В правилах standard можно в шаблоне перечислить все значения, которые были в базовых событиях:
{{range .BaseEvents}} {{.SourceUserName}}{{end}}В правилах standard можно в шаблоне достать значение из конкретного события, используя условия:
{{range .BaseEvents}}{{if eq .DeviceEventClassID "4688"}}{{.DestinationProcessName}}{{end}}{{end}}Также в шаблонах можно использовать переменные, например, можем весь массив сырых событий положить в отдельную переменную $baseEvents и использовать её дальше. Пример ниже сортирует события 4104 по dcn1 и конкатенирует куски ScriptBlockText, чтобы в корреляционном событии получить весь PowerShell скрипт, а не куски из 15,5к символов.
{{ $baseEvents := .BaseEvents }}
{{range $index, $element := $baseEvents}}
{{range $i, $e := $baseEvents}}
{{if eq $e.DeviceCustomNumber1 (len (printf "a%*s" $index ""))}}
{{.S.ScriptBlockText}}
{{end}
}{{end}}
{{end}}Шаблоны с алертами
В правиле обогащения, когда вы обращаетесь, вы как бы находитесь в событии и можете напрямую обращаться к полям.
Но в шаблоне уведомлений вы находитесь уже в алерте и в нем нет полей события, но сами события есть. Поэтому нужно сначала проитерироваться по Events (корреляционные события) или дополнительно по Events.BaseEvents (базовые события корреляционных) и оттуда достать уже поле, куда вы в правиле корреляции все сложили.

Полезные ссылки
Другие варианты работы с шаблонами GO в KUMA:
Замена сертификата (веб - интерфейсе) KUMA
Процесс перевыпуска сертификата ядра в версии KUMA 3.2 был изменен! Актуальная информация приведена в онлайн-справке: https://support.kaspersky.ru/help/KUMA/3.2/ru-RU/275543.htm и https://support.kaspersky.ru/kuma/3.2/217747
Общая информация
После установки Ядра KUMA установщик создает следующие сертификаты в папке /opt/kaspersky/kuma/core/certificates:
- Самоподписанный корневой сертификат ca.cert с ключом ca.key. Подписывает все другие сертификаты, которые используются для внутренней связи между компонентами KUMA.
- Сертификат internal.cert, подписанный корневым сертификатом, и ключ internal.key сервера Ядра. Используется для внутренней связи между компонентами KUMA.
- Сертификат веб-консоли KUMA external.cert и ключ external.key. Используется в веб-консоли KUMA и для запросов REST API.
Между взаимодействием компонентов KUMA не должно быть SSL-инспекции
Запрос сертификата от центра сертификации CA
Создаем файл openssl.cnf:
=====это пример, вписываем свои значения======
[ req ]
default_bits = 4096 # RSA key size
encrypt_key = no # Protect private key
default_md = sha256 # MD to use
utf8 = yes # Input is UTF-8
string_mask = utf8only # Emit UTF-8 strings
prompt = no # Prompt for DN
distinguished_name = server_dn # DN template
req_extensions = server_reqext # Desired extensions
[ server_dn ]
countryName = RU # ISO 3166
localityName = Moscow
organizationName = MYCOMPANY
organizationalUnitName = SOC
commonName = kuma.mycompany.ru # Should match a SAN under alt_names
[ server_reqext ]
basicConstraints = CA:FALSE
keyUsage = critical,digitalSignature,keyEncipherment
extendedKeyUsage = serverAuth,clientAuth
subjectKeyIdentifier = hash
subjectAltName = @alt_names
[alt_names]
DNS.1 = kuma.mycompany.ru
IP.1 = 1.2.3.4Делаем запрос на сертификат:
openssl req -new -nodes -sha256 -out external.csr -config /root/cert/openssl.cnf -keyout external.keyВ текущем каталоге будут созданы файлы external.key (файл с закрытым ключом ) и external.csr (файл запроса на сертификат)
Отдаем запрос на сертификат в центр сертификации. От центра сертификации должны получить сертификат сервера и корневой сертификат центра сертификации и все сертификаты промежуточных центров сертификации если они есть.
- Все сертификаты должны быть в формате PEM (BASE64).
- Содержимое сертификатов должно выглядеть - ( -----BEGIN CERTIFICATE----- и -----END CERTIFICATE-----)
Полученные сертификаты необходимо объединить в одну полную цепочку сертификатов в правильном порядке.
openssl x509 -inform PEM -in server.pem > external.cert
openssl x509 -inform PEM -in subca.pem >> external.cert
openssl x509 -inform PEM -in root.pem >> external.certВ файле с сертификатами важен порядок и должнен быть примерно такой: rootca-subca1-subca2-subca3-...
Полученный файл external.cert необходимо проверить на корректность (должен быть вывод списка цепочки сертификатов):
openssl crl2pkcs7 -nocrl -certfile external.cert | openssl pkcs7 -print_certs -noout
openssl verify external.cert
#external.cert: OKПроверяем корректность полученного сертификата и ключа (результат должен совпадать):
openssl x509 -noout -modulus -in external.cert | openssl md5
#(stdin)= 239994c3bd2a90507a548bf373127e18
openssl rsa -noout -modulus -in external.key | openssl md5
#(stdin)= 239994c3bd2a90507a548bf373127e18Замена в обычной инсталляции (не кластер ядра)
Перед заменой пары external.cert external.key создайте их резервную копию.
openssl pkcs12 -in kumaWebIssuedByCorporateCA.pfx -nocerts -out external.keyopenssl pkcs12 -in kumaWebIssuedByCorporateCA.pfx -nokeys -out external.certopenssl pkcs8 -in private.key -topk8 -nocrypt -out new_private.key/opt/kaspersky/kuma/core/certificates/chown kuma:kuma external.cert external.keyПерезапустить ядро:
systemctl restart kuma-coreЗамена в оказоустойчивом ядре
1. На контрольной машине или Control Plane Master получить список подов и найти кору
k0s kubectl get pod -A2. Зайти в шел пода коры и выполнить бэкап сертификатов. (название core-deployment в каждой инсталяции уникально)
k0s kubectl exec -n kuma --stdin --tty core-deployment-779f8bf646-djszw -- /bin/bash3. Скопировать новый сертификат с файловой системы Control Plane Master на под коры, выгрузить сертификат и ключ
k0s kubectl cp kuma-poc.pfx -n kuma core-deployment-779f8bf646-djszw:/opt/kaspersky/kuma/core/certificates4. Найти деплоймент коры
k0s kubectl get deployments5. Выполнить рестарт деплоймента коры
k0s kubectl rollout restart deployment -n kuma core-deploymentНастройка мониторинга источников с алертом
В рамках данной статьи настроим политику мониторинга определенного источника с взведением алерта при срабатывании политики.
На системы приходят следующие события:
Имеем следующий источник событий (перейдите (в меню слева) на вкладку Состояние источников):

Собятия на этом источнике поступают с потоком 1 EPS.
Создание источников событий происходит один раз в минуту с именем следующего формата после парсинга: "DeviceProduct|DeviceHostname|DeviceAddress|DeviceProcessName".
Настроим политику мониторинга для этого источника: хотя бы 1 событие в течение 1 минуты. Перейдите на вкладку Политики мониторинга и наша политика будет выглядеть следующим образом:
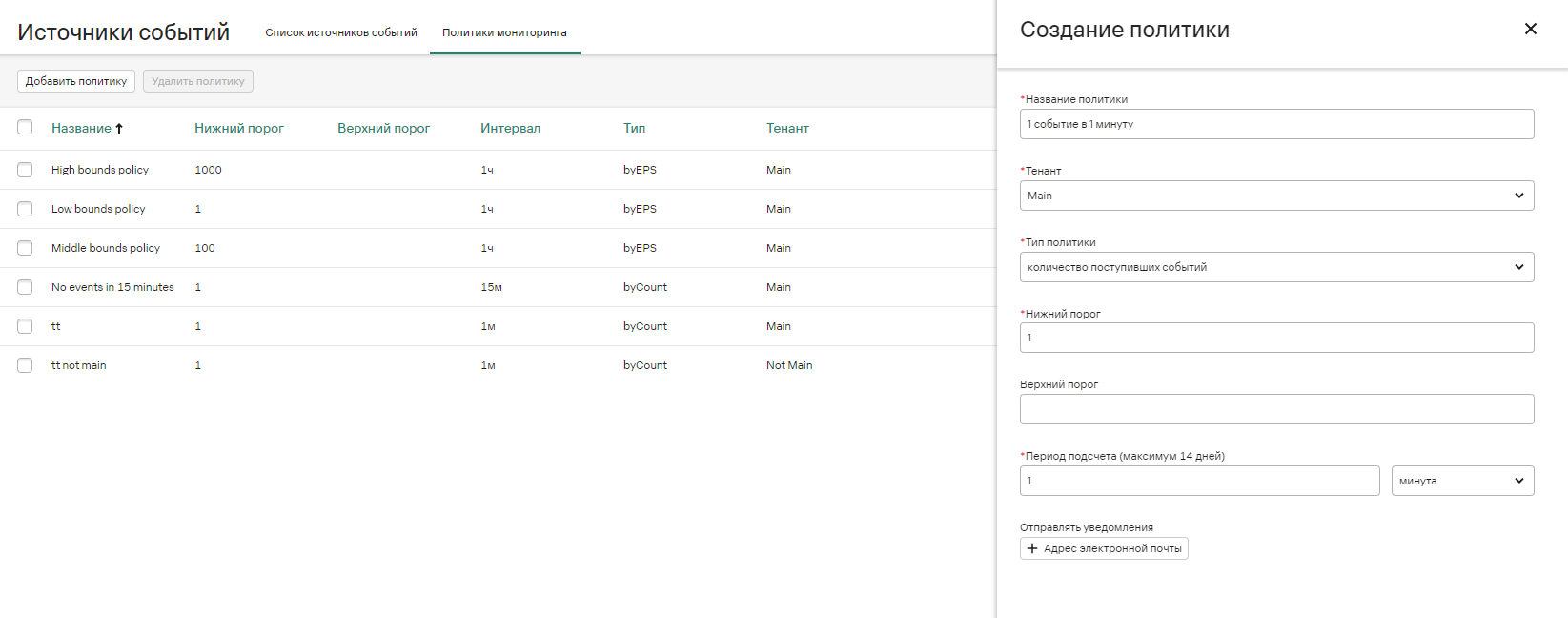
Также можно настроить электронную почту для уведомлений в случае срабатывания политики. Затем необходимо нажать на кнопку Добавить. Затем необзодимо перейти снова на вкладку Список источников событий, выделить источник и закрепить ранее созданную политику:
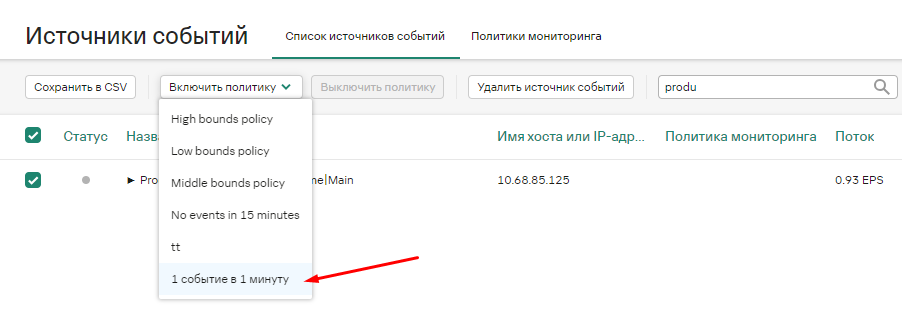
Флажок статуса источника после добавления станет зеленым (означает - соответствие политике).
Убедимся, что правило корреляции мониторинга источников (в стоставе Pre-Sales-Pack) добавлено в коррелятор:
Отключаем подачу событий и получаем следующее:

В событиях:
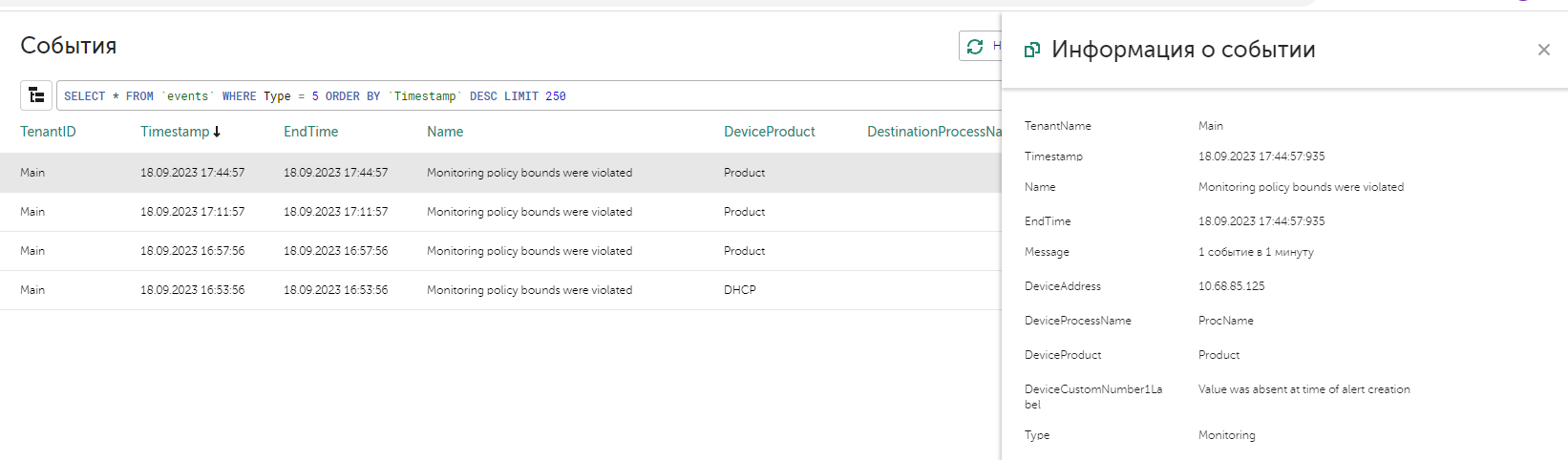
Алерт:
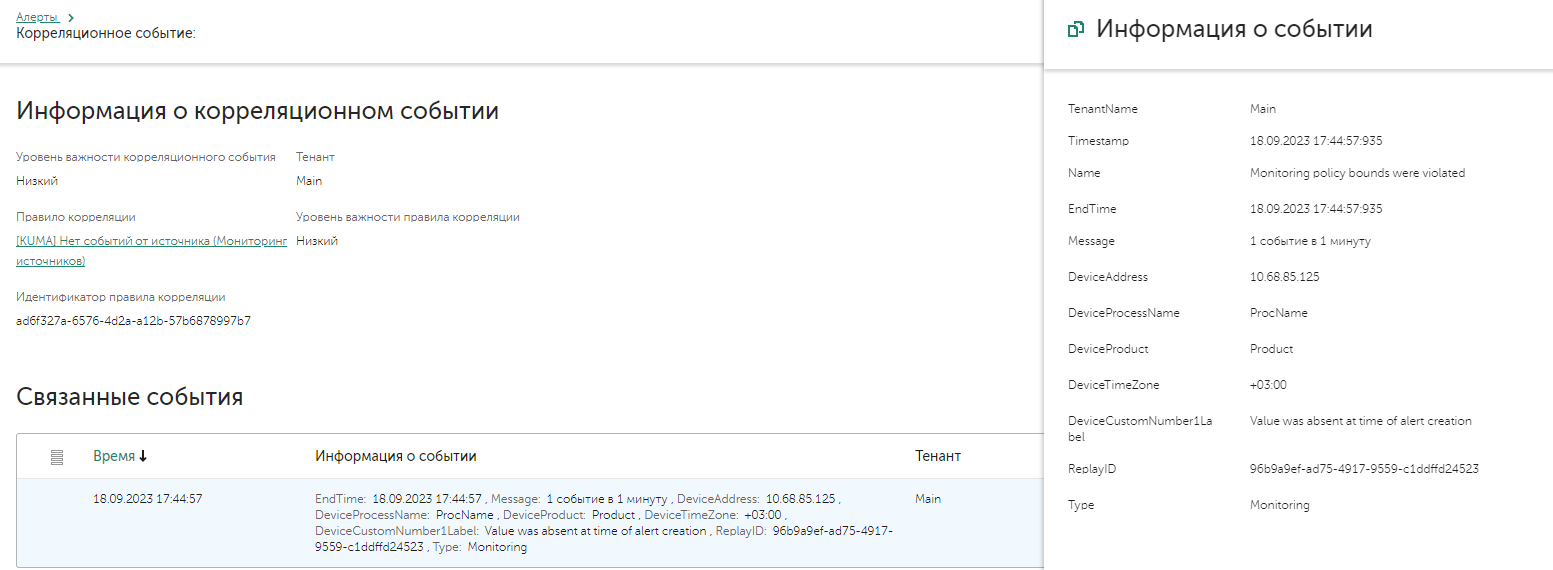
Аудит изменений по активам
Информация, приведенная на данной странице, является разработкой команды pre-sales и/или community KUMA и НЕ является официальной рекомендацией вендора.
Официальная документация по данному разделу приведена в Онлайн-справке на продукт: https://support.kaspersky.com/KUMA/2.1/ru-RU/233948.htm
Аудит изменений по активам позволяет произволить корреляцию событий аудита по активам по измененям данных ассета.
Перейдите в раздел Параметры - Аудит активов веб-интерфейсе KUMA. Щелкните (или добавьте) на тенант и выберите по каким параметрам вести аудит (чтобы производить корреляцию по изменениям необходимо добавить коррелятор):
Событие формируется на каждое изменение: по одному событию на каждое изменение (например, добавлено 5 уязвимостей - значит будет 5 событий аудита ассетов с типом "Добавление уязвимости ассета").
В событиях информацию можно найти следующим запросом:
SELECT * FROM `events` WHERE DeviceEventCategory = 'Audit assets' ORDER BY Timestamp DESC LIMIT 250
Типы событий по которым ведется аудит:
- Ассет добавлен. Создание ассета любым способом: вручную через web-интерфейс KUMA, REST API, импорт KSC и тд.
- Ассет изменен. Изменены такие поля как: Name, IP address, Mac Address, FQDN, Operating system.
- Ассет удален. Ассет помечается как удаленный, если был удален вручную пользователем или если по нему не пришла информация из KSC по истечению срока в параметре TTL.
- Добавление уязвимости ассета. Пришла информация о новой уязвимости, ранее отсутствующей у ассета.
- Устранение уязвимости ассета. Уязвимость считается устраненной, если по ней отсутствует информация во всех источниках ассета. Информация об уязвимостях может приходить от разных источников. Считаем уязвимость устраненной, если со всех источников пришла информация об ее устранении.
- Ассет добавлен в категорию. Реативная категоризация (например, когда правило отправило ассет в определенную категорию) - фиксируется какое правило отправило и какая категория.
- Ассет удален из категории.
В наборе правил корреляции ПресейлПак есть пример правила корреляции по обнаружению новой уязвимости на Ассете по событию аудита в KUMA.
Тенанты в KUMA (Multitenancy)
Термины
- Multitenancy — "множественное владение", использование общих ресурсов разными пользователями изолировано друг от друга.
- Tenant (тенант) — огранизация / филиал организации (в рамках KUMA).
- General tenant — основной тенант (Main), который имеет доступ ко всем данным и настройкам своих филиалов, может осуществлять централизованное управление филиалами.
Права на создание нового и редактирование существующего тенанта — только у пользователя с ролью General admin.
Для редактирования ресурсов в определенном тенанте, помимо прав администратора тенанта добавьте еще права аналитика к УЗ
Отключить Main тенант нельзя (можно переименовать), так как некоторые разделы в KUMA доступны только ему, например, Audit события KUMA складваются только в нем.
Принцип работы
KUMA Core (ядро SIEM) — это web консоль и компонент управления всеми микросервисами KUMA. В каждой инсталляции один сервер Core. Все остальные микросервисы можно распределять по инфраструктуре, как удобно, даже без разделения по тенантам.
Разделение по тенантам позволяет разграничить доступ пользователей KUMA по событиям (как базовым так и корреляционным), контенту (правила парсинга, корреляции и т.д.). Тенант может назначаться Коллектору или Коррелятору, а Хранилищу можно назначить Тенант (если это архитектурно тербуется), когда оно отдельное со своими дисками и мощностями.
Ниже схематично представлен путь событий от коллекторов в разных тенантах (А и В) в единое Хранилище (Тенант Main), где пользователь Тенанта А может видеть только свои события (Тенанта А):

Пользователи подключаются к Core и через него отправляют поисковые запросы в хранилище (или хранилища) своего тенанта.
Выбор тенанта производится в соответсвующем разделе:

Core выступает единой точкой администрирования всей инфраструктуры KUMA, при этом в Core передаются не все события, а только результаты поисковых запросов пользователей, поэтому сетевой трафик минимален.
Отдельные (филиальные) Коррелятор и/или Хранилище имеют смысл, если не хочется значительно нагружать каналы связи между Головным офисом и Филиалом, либо архитектурные / организационные требования, например, локальное хранение.

Кросс-тенантный коррелятор
События разных тенантов могут быть собраны коЛЛекторами, но направляться в один коРРелятор, в этом случае корреляционные события и алерты будут помечены тенантом коррелятора. Ниже представлен пример отправки события от коллектора в Тенанте А в коррелятор Тенант В:
Ресурсы, используемые в корреляторе, должны принадлежать тому же тенанту, что и сам коррелятор (т.е. правила корреляции из Тенанта А могут прилинковаться к коррелятору Тенанта А). Исключение Shared тенант, ресурсы общего тенанта могут быть использованы в любом корреляторе.
Удаление тенанта
При удалении тенанта происходит следующее: Принадлежащие тенанту сервисы, за исключением агентов, автоматически останавливаются. В разделе Ресурсы → Активные сервисы эти сервисы будут отображаться с серым статусом. Прекращается прием и обработка событий, а уже полученные события удаляются.
Описание метрик в KUMA
Официальная документация по данному разделу приведена в Онлайн-справке на продукт: https://support.kaspersky.ru/help/KUMA/3.2/ru-RU/218035.htm
По умолчанию данные о работе KUMA хранятся 3 месяца. Этот срок можно изменить, см. справку.
В KUMA роль системы мониторинга выполняет Victoria Metrics. Информация по всем микросервисам обновляется каждые 5 секунд по HTTP-интерфейсу. А Grafana отвечает за отображение метрик, собранных с помощью Victoria Metrics.
Для просмотра всех наборов графиков щелкните сюда (на имя подсвеченное зеленым) в разделе KUMA "Метрики":
Общие метрики
Следующие метрики извлекаются из всех микросервисов KUMA
- Process — Общие метрики процесса
- Memory — Утилизация оперативной памяти, оценивается резидентная память (RSS - Resident set size)
- DISK BPS — Количество байт в секунду прочитанных/записанных на диск
- Network BPS — Количество байт в секунду полученных/отправленных в сеть
- Network Packet Loss — Количество утраченных сетевых пакетов в секунду
- GC Latency — Время (медиана), затраченное на цикл Garbage Collector'а GO
- Goroutines — Текущее количество активных Go-рутин (потоки в Golang)
OS (Общие метрки операционной системы)
- Load — Load average (средняя нагрузка) на ЦП. Обычно да 1, 5 и 15 минут, если число нагрузки за 15 минут более количества ядер (включая виртуальные) системы, то это не нормально
- CPU — Общая утилизация ЦП
- Memory — Общая утилизация оперативной памяти (RSS). В норме, когда число не доходит до 100%
- Disk — Утилизация дискового пространства
Метрики Collectors
IO (Input-Output)
- Processing EPS — Количество обрабатываемых событий в секунду
- Output EPS — Количество отправляемых в точку назначения событий в секунду
- Output Latency — Время, затраченное на передачу пачки событий точке назначения и на получения ответа от нее
- Output Errors — Количество ошибок отправки пачки событий точке назначения в секунду. Ошибки отправки по сети и ошибки записи в дисковый буффер отображаются отдельно
- Output Event Loss — Количество потерянных событий в секунду. Потеря может произойти, если их не удалось отправить ни в сеть, ни записать в дисковый буффер
- Output Disk Buffer Size — Текущий размер дискового буффера точки назначения. Ноль означает, что ни одна пачка событий не буферизирована, и это хорошо, не копится очередь
Normalization
- Raw & Normalized event size — Размер (медиана) оригинального лога источника и размер нормализованной формы этого лога (события)
- Errors — Количество ошибок нормализации в секунду
Filtration
- EPS — Количество событий в секунду, отбрасываемых фильтром коллектора
Aggregation
- EPS — Количество событий, входящих и выходящих из правила агрегации в секунду. Позволяет оценить эффективность правил агрегации
- Buckets — Текущее количество бакетов в правиле агрегации
Enrichment
- Cache RPS — Количество обращений к локальному кешу в секунду
- Source RPS — Количество обращений к источнику обогащения в секунду
- Source Latency — Время (медиана), затраченное на отправку запроса и получение ответа от источника обогащения
- Queue — Размер очереди запросов на обогащение. Позволяет оценить, является ли данное правило обогащения узким местом
- Errors — Количество ошибок обращений к источнику обогащения, обозреваемых в секунду
Метрики Correlator
IO (Input-Output)
- Processing EPS — Количество обрабатываемых событий в секунду
- Output EPS — Количество событий, отправляемых в точку назначения в секунду
- Output Latency — Время (медиана), затраченное на передачу пачки событий точке назначения и на получения ответа от нее
- Output Errors — Количество ошибок отправки пачки событий точке назначения в секунду. Ошибки отправки в сеть и ошибки записи в дисковый буффер отображаются отдельно
- Output Event Loss — Количество потерянных событий в секунду. Потеря может произойти, если их не удалось отправить ни в сеть, ни записать в дисковый буффер
- Output Disk Buffer Size — Текущий размер дискового буффера точки назначения. Ноль означает, что ни одна пачка событий не буферизирована, и это хорошо, не копится очередь
Correlation
- EPS — Количество корреляционных событий, порождаемых правилом корреляции в секунду
- Buckets — Текущее количество бакетов внутри правила корреляции (только для правил Standard)
- Rate Limiter Hits — Превышение лимита срабатываний правилом корреляции в секунду
- Active Lists OPS — Количество обращений к активному листу в секунду, с указанием операции
- Active Lists Records — Текущее количество записей в активном листе
- Active Lists On-Disk Size — Текущий размер активного листа на диске
Enrichment
- Cache RPS — Количество обращений к локальному кешу в секунду
- Source RPS — Количество обращений к источнику обогащения в секунду
- Source Latency — Время (медиана), затраченное на отправку запроса и получение ответа от источника обогащения
- Queue — Размер очереди запросов на обогащение. Позволяет оценить, является ли данное правило обогащения узким местом
- Errors — Количество ошибок обращений к источнику обогащения, обозреваемых в секунду
Response
- RPS — Количествово запусков/активаций правил реагирования (response) в секунду.
Метрики Storage
Clickhouse / General
- Active Queries — Общее кол-во запросов к кластеру Clickhouse, выполняемых в данный момент. Метрика отображается по каждому инстансу Clickhouse
- QPS — Общее количество запросов в секунду
- Failed QPS — Общее количество неуспешных запросов в секунду
- Allocated memory — Количество памяти (RAM), выделенное процессу Clickhouse
Clickhouse / Insert
- Insert EPS — Количество событий, вставляемых за одну секунду в инстанс Clickhouse
- Insert QPS — Количество запросов на вставку в секунду
- Failed Insert QPS — Количество неуспешных запросов на вставку в секунду
- Delayed Insert QPS — Количество запросов на вставку (в секунду), которые были отложены нодой Clickhouse по превышению soft лимита активных слияний.
- Rejected Insert QPS — Количество запросов на вставку (в секунду), которые были отвергнуты нодой Clickhouse по превышению hard лимита активных слияний.
- Active Merges — Количество активных слияний
- Distribution queue — Количество файлов, в которые сохранены временно эвенты в кластере Clickhouse. Эвенты предназначены для инсерта в тот или иной шард, но не попали из-за того, что шард был недоступен. Эти события недоступны в поиске
Clickhouse / Select
- Select QPS — Количество запросов на выборку данных в секунду
- Failed Select QPS — Количество неуспешных запросов на выборку данных в секунду
Clickhouse / Replication
- Active Zookeeper Connections — Количество активных подключений к нодам кластера Zookeeper. В норме должно быть равным количеству нод в кластере Zookeeper
- Read-only Replicas — Количество нод-реплик Clickhouse, находящихся в режиме read-only. В норме таких реплик быть не должно (равно нулю)
- Active Replication Fetches — Количество активных процессов репликации данных в настоящий момент (скачивание данных с ноды)
- Active Replication Sends — Количество активных процессов репликации данных в настоящий момент (отправка данных ноде)
- Active Replication Consistency Checks — Количество текущих проверок консистентности данных на репликах
Clickhouse / Networking
- Active HTTP Connections — Количество активных подключений к HTTP серверу Clickhouse
- Active TCP Connections — Количество активных подключений к TCP серверу Clickhouse
- Active Interserver Connections — Количество активных служебных подключений между нодами Clickhouse
Метрики Core
IO (Input-Output)
- RPS — Количество запросов в секунду
- Latency — Время (медиана), затраченное на обработку одного запроса
- Errors — Количество ошибок обоработки запросов в секунду
Notification Feed
- Subscriptions — Количество клиентов, подключенных к Core с помощью SSE для получения сообщений от сервера в реальном времени. Обычно равно количеству клиентов, использующих Web-console
- Errors — Количество ошибок отправки оповещений в секунду
Schedulers
- Active — Текущее количество активных системных повторяющихся задач. Фоновые задачи, запущенные пользователем, не учитываются
- Latency — Время (медиана), затраченное на выполнение задачи
- Errors — Количество ошибок выполнения задач, обозреваемых в секунду
С KUMA версии 3.2:
Raft
- Lookup RPS — Количество вызовов процедур чтения в секунду. С указанием процедуры
- Lookup Latency — Длительность выполнения процедур чтения, с указанием процедуры. (99 percentile)
- Propose RPS — Количество вызовов процедур обновления состояния Raft (SQLITE) в секунду. С указанием процедуры
- Propose Latency — Длительность выполнения процедур обновления состояния Raft (SQLITE), с указанием процедуры. (99 percentile)
API
- RPS — Количество запросов в секунду
- Latency — Время, затраченное на обработку одного запроса. Медиана
- Errors — Количество ошибок обоработки запросов, обозреваемых за 1 секунду
С KUMA версии 3.4:
Tasks
- Active tasks — Число выполняемых задач за единицу времени, в шт.
- Task Execution latency — Время выполняемых задач, в сек
- Errors — Ошибки при выполнении задач, в шт
Data Mining
- Executing Rules — Суммарное количество Data Mining правил, которые сейчас выполняются
- Execution Latency — Продолжительность выполнения Data Mining правил (сколько время занял сам запрос в БД от момента запуска, до передачи в коррелятор)
- Queued Rules — Суммарное количество правил в очереди. Очередь появляется тогда, когда запланировано на одно время больше правил, чем разрешено параметром конкурентности (по умолчанию = 1)
- Execution Errors — Количество ошибок при выполнении Data Mining правил
С KUMA версии 3.2
Метрики KUMA Agent
Для сбора доступ в ядро по порту 8429/tcp
IO (Input-Output)
- Processing EPS — Количество обрабатываемых событий за 1 секунду
- Output EPS — Количество отправляемых в точку назначения событий за 1 секунду
- Output Latency — Время, затраченное на передачу пачки событий точке назначения и на получения ответа от нее. Иными словами - продолжительность round-trip. Медиана
- Output Event Loss — Количество потерянных событий за 1 секунду. Потеря может произойти, если их не удалось ни отправить в сеть, ни записать в дисковый буффер. Кроме того, если точка назначения ответила кодом, означающим, к примеру, некорректно сформированный запрос - события также будут утеряны
- Output Errors — Количество ошибок отправки пачки событий точке назначения, обозревамое за 1 секунду. Ошибки отправки в сеть и ошибки записи в дисковый буффер отображаются отдельно
- Output Disk Buffer Size — Текущий размер дискового буффера destination. Ноль означает, что ни одна пачка событий не буферизирована, все в порядке
- Write Network BPS — Количество байт отправленных в сеть за 1 секунду
Метрики EventRouter
IO (Input-Output)
- Processing EPS — Количество обрабатываемых событий за 1 секунду
- Output EPS — Количество отправляемых в точку назначения событий за 1 секунду
- Output Latency — Время, затраченное на передачу пачки событий точке назначения и на получения ответа от нее. Иными словами - продолжительность round-trip. Медиана
- Output Event Loss — Количество потерянных событий за 1 секунду. Потеря может произойти, если их не удалось ни отправить в сеть, ни записать в дисковый буффер. Кроме того, если точка назначения ответила кодом, означающим, к примеру, некорректно сформированный запрос - события также будут утеряны
- Output Errors — Количество ошибок отправки пачки событий точке назначения, обозревамое за 1 секунду. Ошибки отправки в сеть и ошибки записи в дисковый буффер отображаются отдельно
- Output Disk Buffer Size — Текущий размер дискового буффера destination. Ноль означает, что ни одна пачка событий не буферизирована, все в порядке
- Write Network BPS — Количество байт отправленных в сеть за 1 секунду
- Connector Errors — Количество ошибок в логах коннектора
Как узнать связи между ресурсами KUMA
Данный способ является workaround, KUMA до 4.0, в будущих релизах будет добавлен штатный механизм отображения зависимостей.
Шаг 0. Предварительно создаем копию нужного ресурса.
Шаг 1. Выбираем ресурс и нажимаем "Удалить"

Шаг 2.

Шаг 3. Подтверждаем удаление.

Шаг 4. В случае, если от ресурса зависят другие ресурсы KUMA, удаление не произойдет и будет выведен список зависимых ресурсов. Если зависимостей не было найдено, то ресурс будет безвозвратно удален (поэтому на шаге 0 был сделан дубликат ресурса).

Устройство кластера хранилища
Бесплатный курс обучения по ClickHouse от Яндекс Практикум - https://yandex.cloud/ru/training/clickhouse
Кластер - логическая группа машин, обладающих всеми накопленными нормализованными событиями KUMA. Подразумевает наличие одного или нескольких логических шардов.
Shard (шард) - логическая группа машин, обладающих некоторой частью всех накопленных в кластере нормализованных событий. Подразумевает наличие одной или нескольких реплик. Если обьяснить на пальцах, механика работы кластера с несколькими шардами - это работа дисков в RAID0.
Увеличение количества шардов позволяет:
- накапливать больше событий за счет увеличения общего количества серверов и дискового пространства;
- поглощать больший поток событий за счет распределения нагрузки, связанной со вставкой новых событий;
- уменьшить время поиска событий за счет распределения поисковых зон между несколькими машинами.
В случае выхода из строя машины с определенным шардом (при отсутствии репликации) данные продолжат накапливаться другими шардами, но в интерефейсе KUMA нельзя будет искать по событиям до тех пор, пока не ввести в строй обратно "упавшую" машину или поиск вернет не консистентные данные
Replica (реплика) - машина, являющаяся членом логического шарда и обладающая одной копией данных этого шарда. Если реплик несколько - копий тоже несколько (репликация данных). Если обьяснить на пальцах, механика работы кластера с несколькими репликами - это работа дисков в RAID1.
Увеличение количества реплик позволяет:
- улучшить отказоустойчиовость;
- распределить общую нагрузку, связанную с поиском данных, между несколькими машинами (однако для этой цели лучше увеличить количество шардов).
Keeper - машина участвующая в репликации и координации (распределенные Data Definition Language (DDL) запросы) данных на уровне всего кластера хранилищ, позволяющее иметь линеаризуемую запись и нелинейное чтение данных. На весь кластер минимально требуется хотя бы 1 реплика с данной ролью. Рекомендуемое и отказоустойчивое количество таких реплик - 3. Число реплик, участвующих в координации репликации, должно быть нечетным. Если Keeper перестанет работать, то реплики переходят в Read only, при этом поиск будет работать, но новые события записываться не будут.
При разворачивании распределенного кластера, машины с ролью Keeper должны быть запущены ДО запуска / установки машин без роли Keeper
При работе keeper машины испольют RAFT алгоритм для определения лидера среди нескольких keeper машин. Лидер выполняет все операции записи и запускает автоматическое восстановление при отказе любого из подключенных серверов. Остальные узлы — подписчики или последователи, реплицируют данные с лидера и используются клиентскими приложениями для чтения. Подробнее можно почитать тут. Кластер может оставаться работоспособным при отказе определенного количества нод в зависимости от размера кластера. Например, для кластера из 3 нод (Keeper), алгоритм кворума продолжает работать при отказе не более чем одной ноды.
Доп. информация: https://clickhouse.com/docs/en/architecture/horizontal-scaling#architecture-diagram
Описание конфигурации хранилища в инвентаре ansible
Пример инвентаря distributed.inventory.yml, если используется два хранилища и 3 кипера, то конфигурация storage будет выглядеть следующим образом:
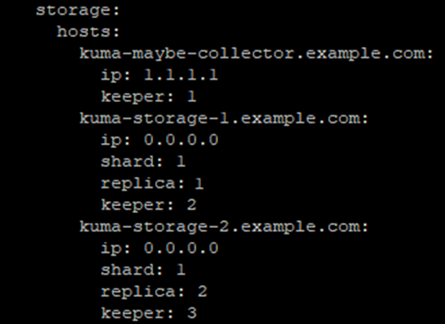
Одно хранилище без кластера

Если указаны параметры shard и replica, то машина является частью кластера и принимает участие в накоплении и поиске нормализованных событий KUMA. Если дополнительно указан параметр keeper, то машина также принимает участие в координации репликации данных на уровне всего кластера. Если keeper на хранилище не нужен, то указывается keeper: 0
Если указан только параметр keeper (отдельная машина с этой ролью), то машина не будет накапливать нормализованные события, но будет участвовать в координации репликации данных на уровне всего кластера. Значения параметра keeper должны быть уникальными, а значения shard и replica равны 0.
"Номера" реплик, шардов и киперов роли не играют. Например, конфиг с номерами реплик 1-2-3 работает так же хорошо как и с номерами 1-23-777, по смыслу это скорее айдишник, а не порядковый номер.
Если в рамках одного шарда определено несколько реплик, то значение параметра replica должно быть уникальным в рамках этого шарда. Пример для четырех серверов хранилища и трех отдельных киперов на рисунке ниже:

При просмотре разделов из веб интерфейса KUMA (Активные сервисы - ПКМ - Смотреть разделы) показывается сколько места занято партицией во всем кластере с учетом всех реплик.

В точке назначения в KUMA (для записи событий в хранилище) прописываются URL всех хранилищ, отдельно установленные машины с ролью keeper указывать НЕ нужно
Буфер хранилища по умолчанию 128 Мб, при большом количестве шардов и заметной медленной работе поиска - увеличьте размер буфера, например, до 512 Мб и увеличте таймаут (интервал очистки буфера), например, до 60 сек.
Редкие большие вставки для БД ClickHouse лучше, чем частые и небольшие.
Установка службы хранилища - https://kb.kuma-community.ru/books/ustanovka-i-obnovlenie/page/ustanovka-sluzby-xranilishha-esli-etogo-ne-proizoslo-pri-ustanovke
Смотри также статью про схему взаимодействия KUMA - https://kb.kuma-community.ru/books/kuma-how-to/page/sxema-setevogo-vzaimodeistviia-kuma
Корректность работы хранилища можно проверить, перейдя во вкладку События и нажав на значок увеличительного стекла (Поиск), далее должны появиться события, поступающие в KUMA или Сообщение «События не найдены». Если при поиске возникает ошибка, то необходимо проверить статусы сервисов в веб интерфейсе KUMA. Провести первичный траблшутинг по этой статье, воспользоваться комьюнити ресурсами или завести кейс в поддержку
Как расширить диск с данными KUMA в случае с lvm
Кейс 1. Увеличивается объем диска
В данном примере расширяется размер диска sda и раздел sda3
- Расширяем диск средствами гипервизора
- Проверяем текущее состояние дисков
lsblk
- Проверяем свободное место
parted /dev/sda unit MB print free
- Изменяем целевой раздел (под номером 3)
parted /dev/sda resizepart 3
- (опционально) Проверяем свободное место, чтобы убедиться, что изменения применились
parted /dev/sda unit MB print free
- (опционально) Проверяем размер физического тома
pvdisplay
- Расширяем физический том
pvresize /dev/sda3
- (опционально) Проверяем логический раздел
lvscan
- Расширяем логический раздел
lvextend /dev/ubuntu-vg/ubuntu-lv -l +100%FREE -r
- (опционально) Проверяем, что все изменения применены
lsblk
Кейс 2. Добавляется новый диск
В данном примере добавляется новый диск sdb
- Подключаем новый диск средствами гипервизора или к железному серверу
- Проверяем текущее состояние дисков
lsblk
- Создаем физический том
pvcreate /dev/sdb
- (опционально) Проверяем том (должны увидеть старый и новый)
pvdisplay
- Расширяем группу томов новым томом
vgextend ubuntu-vg /dev/sdb
- (опционально) Проверяем, что группа томов увеличилась в размере
vgdisplay
- Расширяем логический раздел
lvextend -l +100%FREE /dev/ubuntu-vg/ubuntu-lv
- (опционально) Проверяем, что раздел был успешно расширен
lvdisplay
- Увеличиваем раздел файловой системы (ext4)
resize2fs /dev/ubuntu-vg/ubuntu-lv
Если файловая система xfs используйте следующую командуxfs_growfs /dev/ubuntu-vg/ubuntu-lv - (опционально) Проверяем, что все изменения применены
df -h
Продление сессии пользователя для режима ТВ (TV-mode)
Не актуально для версий KUMA >3.2
В рамках данной статьи настраивается автоматическое продление сессии пользователя для ТВ режима, чтобы отображать дашборды на экранах без перелогина.
По умолчанию в KUMA сессия длится 12 часов и этот параметр не изменяется
1. Создайте пользователя с ролью Младший аналитик (минимальные привилегии для просмотра дашбордов) с доступом в нужные тенанты:

2. Сделайте выход пользователя из KUMA. Перейдите на страницу входа в KUMA, нажмите в браузере F12 (или перейдите в режим разработчика), затем зайдите новым пользователем:

3. Перейдите в окне режима разработчика в браузере во вкладку Application, затем раздел Cookies и скопируйте значения переменных XSRF-TOKEN и kuma_m_sid:

4. Заполните запрос curl своими данными из переменных:
curl -s -k --location 'https://10.68.85.126:7220/api/reset-session-ttl' --header 'Cookie: XSRF-TOKEN=acdb1014-a95e-40c0-afdd-5080133a6463; kuma_session=n6xXfEgIxiC3Bo896X0Ece0sGmovt72RFksI9_PJ09g%3D' --compressed5. Создайте задачу в crontab на ядре KUMA с повторением каждые 4 часа, выполните команду crontab -e и добавьте запись в конце, зайтем выйдите с сохранением:
0 */4 * * * /usr/bin/curl -s -k --location 'https://10.68.85.126:7220/api/reset-session-ttl' --header 'Cookie: XSRF-TOKEN=39dd617f-d016-4d12-b6b1-d9ec4cf30a24; kuma_session=RX8WiZVn0H-xxLR_7wEdU4XCARcNUHWaDwS9CQDBQYA%3D' --compressedКак определить средний размер события
В веб-интерфейсе
Для того, чтобы определить средний размер хранимого события из веб-интерфейса, выполните следующие действия:
1. Войдите в веб-интерфейс с учетной записью администратора
2. Перейдите в Ресурсы - Активные сервисы
3. Выберите ваше хранилище правой кнопкой мыши и нажмите Смотреть разделы

4. В результате откроектся таблица с разделами (партициями). Вы можете найти необходимые партиции через поиск или отфильтровать по доступным полям, например по полю Пространство.

В колонке Размер представлен размер хранимых событий в разделе с учетом реплик в Байтах (до версии 4.0, в 4.0 возможно выбрать единицы отображения).
В колонке События представлено количество событий в разделе.
Для того, чтобы посчитать средний размер хранимого события необходимо воспользоваться формулой:
(Размер ÷ События) ÷ Количество реплик
Для более точного результата рекомендуется проделать вычисления для нескольких разделов одного типа за разные даты и затем вычислить среднее арифметическое.
Cканер уязвимостей ADPulse DC
ADPulse — это инструмент аудита безопасности Active Directory с открытым исходным кодом, который подключается к контроллеру домена через LDAP(S), выполняет 35 автоматических проверок безопасности и создает подробные отчеты в консольном формате, формате JSON и HTML.
Он предназначен для ИТ-администраторов, специалистов по тестированию на проникновение и групп безопасности, которым необходима быстрая оценка неправильных настроек Active Directory и поверхности атаки в режиме только для чтения.
ADPulse работает в режиме только для чтения и не вносит изменений в инфраструктуру — но это не делает его использование безобидным с правовой точки зрения.
Используйте инструмент только если:
-
Вы администратор или сотрудник ИБ своей организации
-
У вас есть письменное разрешение на проведение аудита (scope of work, договор, приказ)
-
Вы проводите работы в рамках официального пентеста с согласованным техническим заданием
Проверки безопасности
|
# |
Проверять |
Описание |
|---|---|---|
|
1 |
Политика паролей |
Минимальная длина, история, сложность, порог блокировки, обратимое шифрование, детализированные PSO. |
|
2 |
Привилегированные учетные записи |
Членство в группах администраторов домена, администраторов предприятия, администраторов схем и других группах с конфиденциальной информацией; устаревшие данные участников, пароли, срок действия которых не истекает, пароли в описаниях, встроенный статус администратора, возраст krbtgt. |
|
3 |
Kerberos |
Учетные записи, допускающие завышение рейтинга Kerberos (SPN в объектах пользователей), учетные записи, допускающие завышение рейтинга AS-REP, шифрование только DES, высокоприоритетные цели, объединяющие adminCount=1 + SPN + PasswordNeverExpires |
|
4 |
Неограниченное делегирование |
Компьютеры и учетные записи пользователей, не относящиеся к центру обработки данных, используются для неограниченного делегирования полномочий Kerberos. |
|
5 |
Ограниченное делегирование |
Учетные записи с переходом протокола (S4U2Self) и стандартными целями с ограниченным делегированием. |
|
6 |
ADCS / PKI |
ESC1, ESC2, ESC3, ESC6, ESC8, ESC9, ESC10, ESC11, ESC13, ESC15, слабые размеры ключей, перечисление ACL участников |
|
7 |
Доверительное использование доменов |
Двустороннее доверие без фильтрации SID, доверие между лесами, внешнее доверие. |
|
8 |
Гигиена аккаунта |
Устаревшие пользователи/компьютеры, учетные записи, в которые никогда не входили, флаг PASSWD_NOTREQD, обратимое шифрование для каждой учетной записи, старые пароли, повторяющиеся SPN. |
|
9 |
Безопасность протокола |
Подписание LDAP/привязка каналов, версии операционных систем контроллеров домена, функциональный уровень домена/леса, рекомендации по NTLMv1/WDigest. |
|
10 |
Объекты групповой политики |
Отключенные, осиротевшие, несвязанные и пустые групповые политики; чрезмерное количество групповых политик. |
|
11 |
LAPS |
Обнаружение устаревших схем LAPS и схем Windows LAPS; компьютеры без паролей LAPS. |
|
12 |
LAPS coverage |
Процентное покрытие всех компьютеров, не являющихся центрами обработки данных, с паролем, управляемым LAPS. |
|
13 |
DNS и инфраструктура |
Использование подстановочных DNS-записей, рекомендации по отравлению LLMNR/NetBIOS-NS. |
|
14 |
Контроллеры домена |
Обнаружение отдельного контроллера домена, устаревшие ОС на контроллерах домена, роли FSMO, политика репликации паролей RODC. |
|
15 |
ACL / Права доступа |
Права доступа ESC4, ESC5, ESC7, DCSync для непривилегированных субъектов, группа защищенных пользователей, списки контроля доступа (ACL) для делегирования. |
|
16 |
Дополнительные функции |
Корзина Active Directory, управление привилегированным доступом (PAM) |
|
17 |
Replication Health |
Количество сайтов, интервалы репликации связей между сайтами, объекты nTDSDSA |
|
18 |
Служебные аккаунты |
Внедрение gMSA, обычные учетные записи пользователей, учетные записи пользователей с adminCount=1 |
|
19 |
Miscellaneous Hardening |
Квота для учетных записей машин, время жизни удаленных файлов, членство в группах администраторов схемы/корпоративных администраторов, гостевая учетная запись, рекомендации по политике аудита. |
|
20 |
Устаревшие операционные системы |
Включены учетные записи компьютеров, сообщающие об окончании поддержки версий Windows. |
|
21 |
Устаревшие протоколы |
Обнаружение SMBv1, обеспечение подписи SMB, принятие нулевых сессий (проверка сети в реальном времени) |
|
22 |
Exchange |
Группа разрешений Windows Exchange (PrivExchange / CVE-2019-0686), доверенная подсистема Exchange |
|
23 |
Защищенные администраторы |
adminCount=1 inventory — orphaned, ghost (disabled) and stale accounts |
|
24 |
Пароли в описаниях |
Обнаружение учетных данных, хранящихся в поле «Описание» пользователей, администраторов и компьютеров, на основе ключевых слов. |
|
25 |
GPP / cpassword (MS14-025) |
Программа выполняет обход файлов XML с атрибутами групповых политик в каталоге SYSVOL и расшифровывает их с помощью общеизвестного ключа AES от Microsoft. |
|
26 |
AdminSDHolder ACL |
Считывает двоичный список контроля доступа (DACL) и помечает непривилегированные учетные записи с правами на запись — эти записи автоматически распространяются на все защищенные учетные записи каждые 60 минут через SDProp. |
|
27 |
История SID |
Обнаруживает учетные записи с заполненными данными; повышает статус до CRITICAL, если какой-либо внедренный SID соответствует привилегированной группе (администраторы домена, администраторы предприятия и т. д.). |
|
28 |
Shadow Credentials |
Функция помечает неожиданные записи в объектах пользователей и компьютеров, позволяя использовать аутентификацию на основе сертификатов без знания пароля учетной записи. |
|
29 |
RC4 / Устаревшее шифрование Kerberos |
Проверяет учетные записи служб, контроллеров домена и администраторов, чтобы выявить те, которые по-прежнему разрешают использование RC4-HMAC — уязвимого типа шифрования, специально запрашиваемого злоумышленниками для взлома в автономном режиме. |
|
30 |
Foreign Security Principals in Privileged Groups |
Выявляет и помечает любые FSP из доверенного домена, являющиеся членами конфиденциальной локальной группы (администраторы домена, операторы резервного копирования и т. д.). |
|
31 |
Доступ, совместимый с версиями до Windows 2000. |
Проверяет, являются ли или являются членами этой группы, что позволяет осуществлять неаутентифицированное перечисление SAMR/LSARPC из любой точки сети. |
|
32 |
Dangerous Constrained Delegation Targets |
Проводит перекрестную проверку целевых объектов делегирования на основе имен хостов контроллеров домена и помечает учетные записи, делегирующие делегирование приоритетным классам обслуживания ( , , , , ) на контроллерах домена. |
|
33 |
Orphaned AD Subnets |
Обнаруживает подсети без назначений, в результате чего клиенты получают случайный контроллер домена и потенциально маршрутизируют трафик аутентификации через каналы WAN. |
|
34 |
Legacy FRS SYSVOL Replication |
Определяет, продолжает ли SYSVOL реплицироваться с помощью устаревшей службы репликации файлов (File Replication Service) вместо DFSR, и помечает состояния, остановившиеся в процессе миграции. |
|
35 |
RBCD on Domain Object / DCs |
Проверяет состояние головного узла домена NC и всех объектов компьютеров контроллера домена — любая из конфигураций предоставляет фактические права администратора домена разрешенным субъектам через S4U2Proxy. |
Требования
-
Python 3.8+
-
Сетевой доступ к контроллеру домена (порт 636 для LDAPS, 389 для LDAP, 445 для SMB-зондов)
-
Учетная запись домена с правами на чтение (для большинства проверок права администратора не требуются).
-
Для проверки 25 (GPP/cpassword): SYSVOL должен быть доступен с сканирующего хоста (UNC-путь в Windows или монтирование Samba в Linux/macOS).
Установка:
git clone https://github.com/yourorg/adpulse.git
cd adpulse
# Содание виртуальной среды
python -m venv venv
source venv/bin/activate # Linux / macOS
venv\Scripts\activate # Windows
# Устанвока зависимостей
pip install -r requirements.txtВозможные аргументы
| Аргумент | Необходимый | По умолчанию | Описание |
|---|---|---|---|
--domain |
Да | — | Целевой домен AD (например corp.local) |
--user |
Да | — | Имя пользователя домена |
--password |
Да | — | пароль домена |
--hash |
Только без пароля | — | Хэш домена NTLM |
--dc-ip |
Нет | Автоматически решено | IP-адрес контроллера домена |
--report |
Нет | all |
Формат отчета: console, json, html, илиall |
--output-dir |
Нет | . |
Родительский каталог для Reports/папки |
--no-color |
Нет | false |
Отключить цвет в выводе на консоль |
Базовое сканирование
python ADPulse.py --domain corp.local --user user --password "P@ssw0rd!"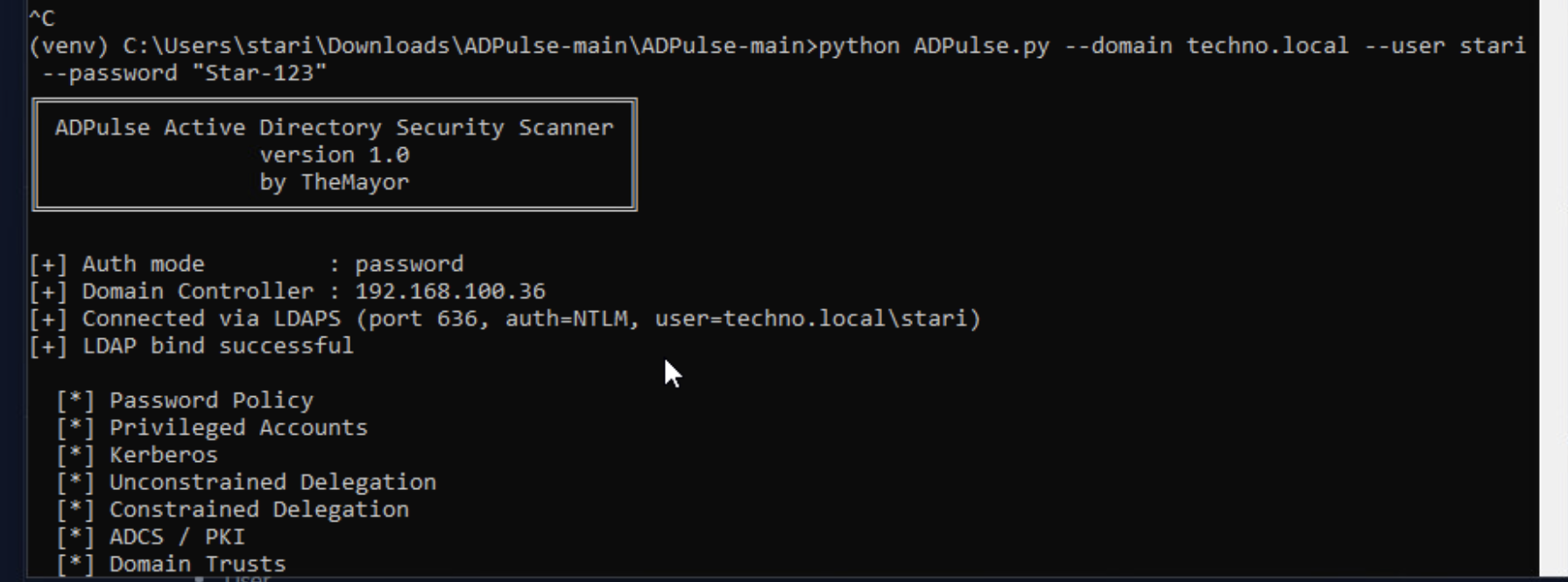
После сканирования вы увидите в командной строке все обнаруженные уязвимости
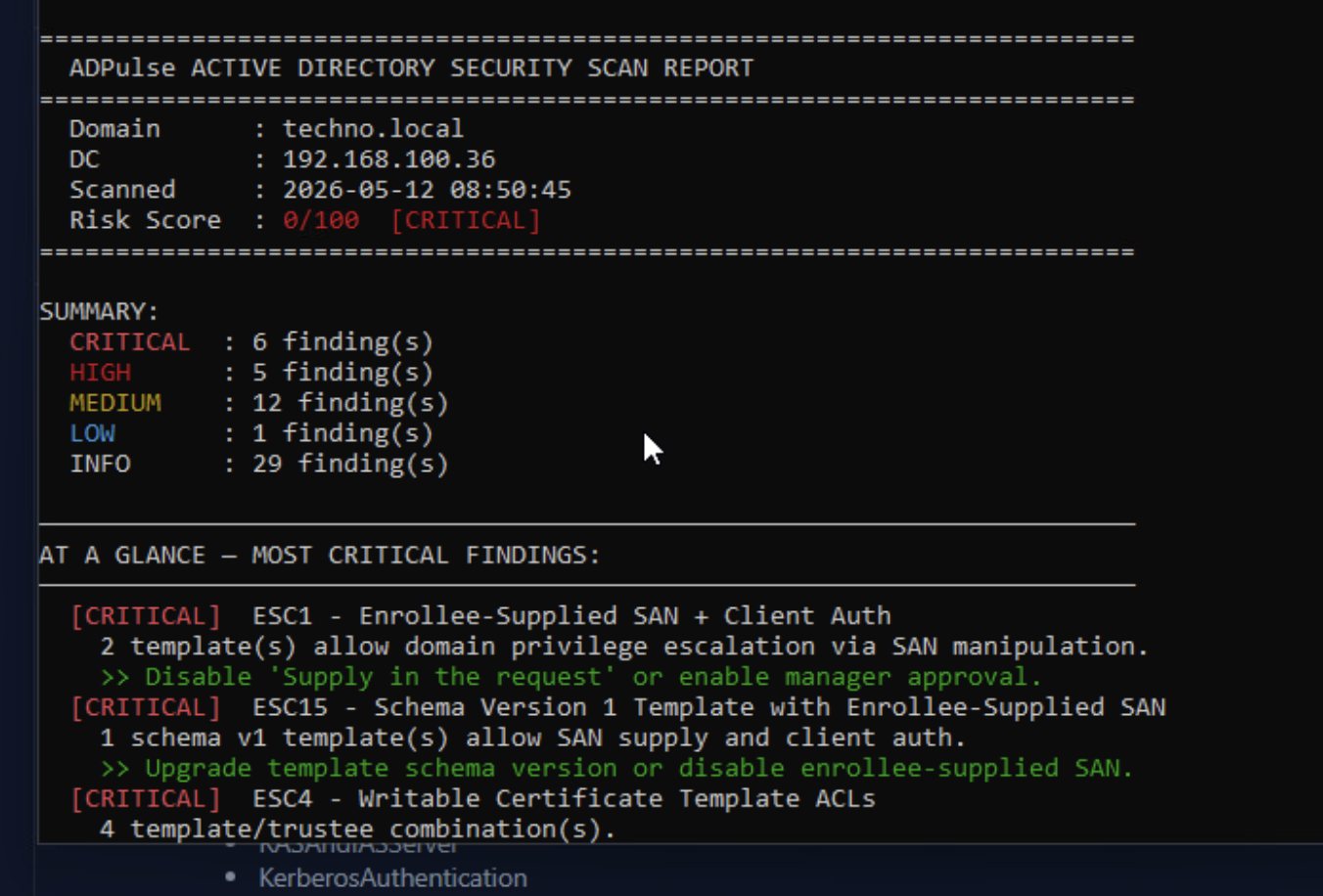
Также автоматически создаются отчеты на устройстве

откроем html отчет:

Подсчет очков
За каждое обнаруженное нарушение начисляется штраф в виде снижения оценки риска. Общий балл начинается со 100 и уменьшается за каждое обнаруженное нарушение:
|
Счет |
Уровень риска |
Значение |
|---|---|---|
|
80–100 |
НИЗКИЙ |
Хорошая система безопасности, лишь незначительные проблемы. |
|
60–79 |
СЕРЕДИНА |
Существенные недостатки, которые следует устранить. |
|
40–59 |
ВЫСОКИЙ |
Присутствуют существенные уязвимости. |
|
0–39 |
КРИТИЧЕСКИЙ |
Серьезные риски — требуется немедленное устранение последствий. |
Устранение уязвимостей
В отчете будут уже указаны рекомендации для устранения:
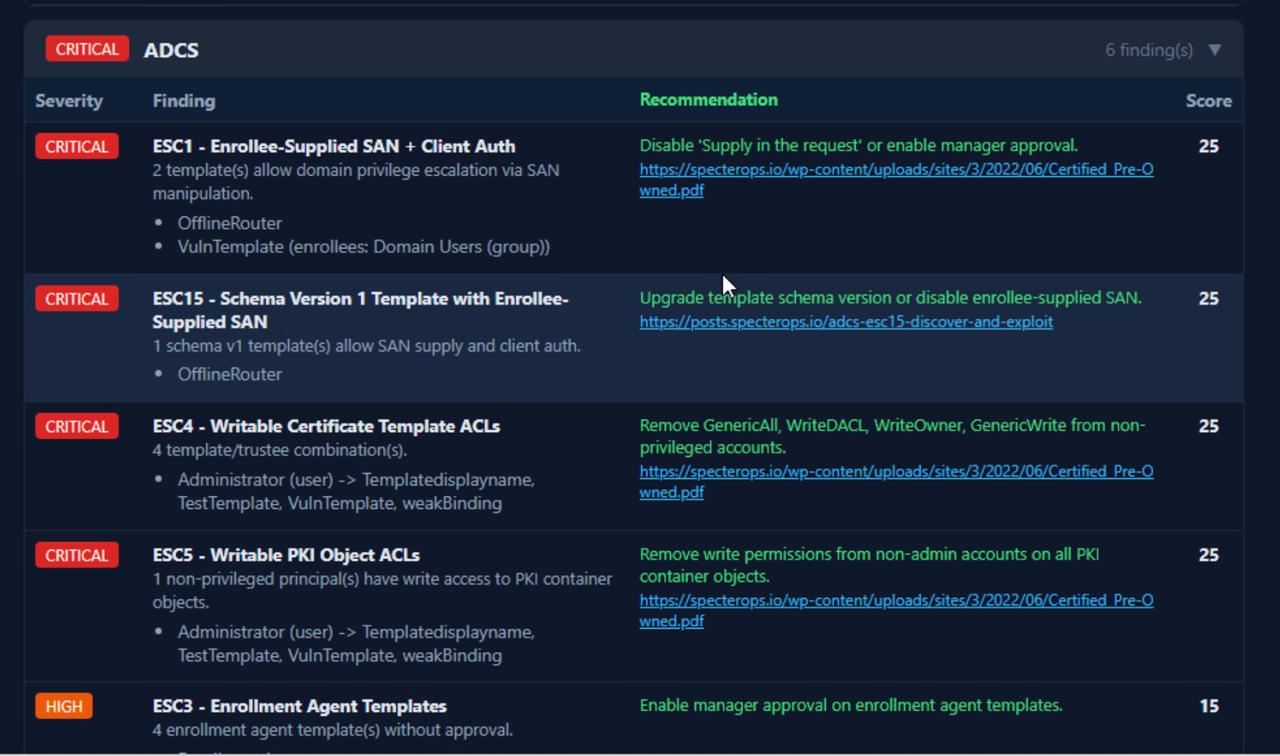
При переходе по предложенным ссылкам, вы сможете подробно изучить их